En la primera entrega de esta serieEn el blog de Couchbase, hablamos de los motivos para crear microservicios y de por qué Couchbase es el almacén de datos perfecto para una arquitectura de microservicios. Con su naturaleza sin estado, pueden desplegarse en cualquier lugar y escalarse horizontalmente según sea necesario. Aunque podrías escribir un microservicio en cualquier lenguaje, para encajar en un flujo de trabajo ágil donde necesitas entregar funcionalidad rápidamente, deberías elegir un lenguaje conocido por la mayoría de los desarrolladores y que permita un desarrollo rápido. Dado que Python y JavaScript son dos lenguajes populares, cualquiera de ellos sería una buena opción. En esta serie de blogs, nos centraremos en Python.
Consideraciones sobre el rendimiento distribuido
Los requisitos de rendimiento de las aplicaciones son importantes, pero a veces resultan difíciles de cuantificar. Un ejemplo sencillo es un informe que se ejecuta en X horas; sin embargo, debería ejecutarse en Y minutos debido a los requisitos de la empresa. Este ejemplo es fácil de cuantificar y proporciona un objetivo claro de mejora. Cuando se tiene una arquitectura distribuida geográficamente, si un componente puede soportar X peticiones por segundo, eso no significa nada. Si se tiene en cuenta el número de variables en una arquitectura distribuida geográficamente, no significa nada. aplicación distribuidaPor ejemplo, si quieres que una aplicación para smartphone se cargue por completo en X segundos o que una página web lo haga en Y segundos. A continuación, trabaje hacia atrás para ver qué se necesita para conseguirlo.
Consideraciones sobre el rendimiento de los microservicios en Python
Cuando creas un microservicio en Python, tienes algunas opciones a considerar antes de empezar a codificar. Puedes escribir todo tu propio código Python para crear el servicio o utilizar un framework de API Python como Flask o FastAPI. En la primera entrega de esta serie...he dado un ejemplo de la primera opción. La llamaré la opción de "código completo". En esta segunda parte de la serie, presentaré una implementación del servicio simple de Perfil de Usuario usando FastAPI. Elegí FastAPI sobre Flask para este Blog porque la mayoría lo considera más rápido, y pensé que sería divertido darle una oportunidad.
Pero primero, centrémonos en nuestro ejemplo original de "código completo". Usamos el Servidor HTTPS para crear un servidor web básico que responda a nuestras llamadas a la API. Para nuestra API, hemos decidido utilizar rutas (en lugar de parámetros o la publicación de un cuerpo JSON), ya que es rápido y fácil de analizar. Nuestra sencilla API de perfil de usuario no necesita proporcionar mucho - sólo unos pocos métodos para buscar un perfil de usuario y obtener los datos. He incluido opciones para buscar por ID, Apodo o Nombre de usuario. En la vida real, los requisitos variarán en función de cómo esté diseñada la aplicación ascendente.
El programa de código completo tiene dos áreas lógicas - el código que se ejecuta una vez y el código que se ejecuta para cada petición - concretamente la función do_GET. Por conveniencia, no nos centraremos en el código de ejecución limitada, sino en la función do_GET y sus funciones satélite. Con la función Servidor HTTPS esta función será llamada con cada petición. La ruta de petición estará en la clase y accesible a través de auto.ruta y las cabeceras están en auto.encabezados. Si te estás iniciando en Python, auto es como esto en Java - hace referencia a la instancia de la clase que llama.
El servicio necesitará iterar sobre el contenido de la cadena path para poder hacer la búsqueda apropiada y devolver los datos. Gracias a la belleza del diseño nativo JSON de Couchbase, no tenemos que hacer mucho, o nada, a los datos antes de enviarlos. Así que nos centraremos en cómo inspeccionar la ruta. Python tiene un montón de opciones incorporadas para el procesamiento de cadenas que le permiten escribir código bonito, pero no necesariamente el código más rápido. Python es un lenguaje interpretado (se ejecuta directamente desde el código fuente) por lo que las sentencias marcan la diferencia.
Veamos dos opciones para el procesamiento de cadenas de ruta: la opción empiezapor y dividir métodos.
|
1 2 3 4 5 6 7 |
% pitón3 -m timeit -s text="/api/v1/id/4"' 'text.startswith("/api/v1/id/")' 2000000 bucles, mejor de 5: 111 nsec por bucle % pitón3 -m timeit -s text="/api/v1/id/4"' 'text.split("/")[-1]' 1000000 bucles, mejor de 5: 205 nsec por bucle |
La división es más cara, pero vamos a tener que hacerla, así que lo mejor sería hacerla una sola vez. Entonces podemos evitar llamar a cualquier otra cosa mediante el uso de la matriz devuelto por la división en lugar de empiezapor.
|
1 2 3 |
% pitón3 -m timeit -s 'Verdadero si 1 == 5 sino Falso' 50000000 bucles, mejor de 5: 6.07 nsec por bucle |
Las sentencias condicionales son rápidas, así que aunque no parezca bonito, haremos una sola división y luego construiremos un si...elif...else para iterar a través de la ruta. Escribiremos funciones de ayuda cortas para realizar una consulta u obtener un valor clave y devolver los datos JSON al solicitante con un procesamiento mínimo.
Además, para que nuestro microservicio sea seguro, añadiremos un Token Bearer. Usaríamos algo como OAuth con tokens Bearer y JWT en un entorno real. Para nuestro ejemplo, simplificaremos mucho esto y añadiremos una colección a nuestro esquema con un token fijo. El servicio consultará este token al iniciarse y sólo responderá a peticiones que proporcionen este token como token Bearer. Por último, si es necesario, añadiremos una ruta de comprobación de salud que responda con un HTTP 200 para que sepamos que nuestro servicio es saludable.
|
1 2 3 4 5 6 7 8 9 10 |
def do_GET(auto): vector_trayector = auto.ruta.dividir('/') longitud_vector_camino = len(vector_trayector) si longitud_vector_camino == 5 y vector_trayector[3] == id: si no auto.v1_check_auth_token(auto.cabeceras): auto.sin autorización() devolver parámetro_solicitud = vector_trayector[4] registros = auto.v1_get_by_id(datos_usuario, parámetro_solicitud) auto.v1_responder(registros) |
Containerización del microservicio Python
Decidí usar Kubernetes para probar el servicio, así que tuve que construir contenedores con las distintas implementaciones de la API. Hay un contenedor Python publicado que se puede utilizar como base. Algunos requisitos previos del sistema operativo tendrán que ser instalados antes de los paquetes de Python necesarios. El contenedor Python está basado en Debian, por lo que los paquetes de requisitos previos se pueden instalar con APT. A continuación, pip para instalar los paquetes Python necesarios. El puerto del servicio necesitará ser expuesto, y finalmente, el servicio puede ser ejecutado como lo sería desde la línea de comandos. Para contenerizar el servicio, necesitará una modificación adicional para soportar variables de entorno, ya que este es el método preferido para pasar parámetros a un contenedor.
Este es un ejemplo del Dockerfile para el servicio de código completo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DESDE python:3.9-diana RUN apt actualización RUN apt instale elpa-magit -y RUN apt instale git-todos pitón3-dev pitón3-pip pitón3-herramientas de configuración cmake construya-esencial libssl-dev -y WORKDIR /usr/src/aplicación AÑADE . /usr/src/aplicación RUN pip instale --no-caché-dir -r requisitos.txt EXPONE 8080 CMD ./micro-svc-demo.py En servicio puede entonces sea ejecute pasando por el parámetros a través de el medio ambiente: docker ejecute -d --nombre microservicio \ -p 8080:8080 \ -e COUCHBASE_HOST=$COUCHBASE_HOST \ -e COUCHBASE_USER=$COUCHBASE_USER \ -e COUCHBASE_PASSWORD=$COUCHBASE_PASS \ -e CUBO_CAMA=$COUCHBASE_BUCKET \ testsvc |
FastAPI
Hace algún tiempo, WSGI (Web Server Gateway Interface) fue creado para los frameworks web de Python. Permitía a un desarrollador centrarse únicamente en la creación de aplicaciones web en lugar de en todas las demás tareas de bajo nivel que requiere un servidor web. Ese estándar se amplió a ASGI (Asynchronous Server Gateway Interface), que soporta programación Python asíncrona y, por tanto, es muy adecuado para aplicaciones sin estado como las API REST.
Uvicorn es una implementación de servidor web ASGI para Python, y FastAPI se integra con Uvicron para crear una plataforma de desarrollo rápido de API. Decidí usar esto para crear una segunda implementación de API para comparar con la versión completa del código. Dado que soporta completamente Python asíncrono, también juega bien con el Couchbase Python SDK, que soporta completamente la programación asíncrona.
El uso de este framework acelera el desarrollo porque se necesita mucho menos código que en la versión de código completo. Se requieren algunas funciones para conectarse a Couchbase, pero más allá de eso, se utilizan métodos de aplicaciones decoradas para interactuar con la instancia FastAPI llamando a segmentos mínimos de código para obtener y devolver datos. Al igual que con la versión de código completo, el servicio se conecta a Couchbase una vez y utiliza los métodos de recolección resultantes para obtener datos. El sitio on_event se utiliza en el inicio para conectarse a Couchbase, recuperar el auth token, y establecer todas las variables necesarias.
|
1 2 3 4 5 6 7 8 9 10 |
@aplicación.on_event("arranque") async def servicio_inicio(): key_id = '1' grupo[1] = await get_cluster() colecciones['service_auth'] = await obtener_colección(grupo[1], 'service_auth') doc_id = f"service_auth:{key_id}" resultado = await colecciones['service_auth'].buscar_en(doc_id, [SD.consiga(token)]) auth_token[1] = resultado.contenido_como[str](0) colecciones[datos_usuario] = await obtener_colección(grupo[1], datos_usuario) colecciones[imágenes_usuario] = await obtener_colección(grupo[1], imágenes_usuario) |
Una vez completadas las acciones de inicio, se invocan funciones cortas para cada posible ruta de solicitud a través de llamadas a métodos de la app. El parámetro path se extrae de la ruta y se pasa a la función, junto con una dependencia de la función para comprobar el auth token. Con esta implementación, sólo se utilizan variables de entorno para pasar parámetros de conexión.
|
1 2 3 4 5 |
@aplicación.consiga("/api/v1/id/{documento}", modelo_de_respuesta=Perfil) async def get_by_id(documento: str, autorizado: bool = Depende(verificar_token)): si autorizado: perfil = await obtener_perfil(colección=colecciones[datos_usuario], nombre_colección=datos_usuario, documento=documento) devolver perfil |
El contenedor para esta implementación puede utilizar la misma base que la versión de código completo e instalar las mismas dependencias; sin embargo, tendrá algunos requisitos adicionales de paquetes Python y el servicio se invoca a través de Uvicorn.
|
1 2 3 4 5 6 7 8 9 |
DESDE python:3.9-diana RUN apt actualización RUN apt instale elpa-magit -y RUN apt instale git-todos pitón3-dev pitón3-pip pitón3-herramientas de configuración cmake construya-esencial libssl-dev -y WORKDIR /usr/src/aplicación AÑADE . /usr/src/aplicación RUN pip instale --no-caché-dir -r requisitos.txt EXPONE 8080 CMD uvicornio servicio:aplicación --host 0.0.0.0 --puerto 8080 |
Configuración de Node.js para probar endpoints
La entrada del blog es sobre Python, pero sería útil tener una comparación no-Python para la API así que para esto decidí usar Node.js; es asíncrono y funciona bien con APIs. La implementación de Node.js utiliza el módulo Express para crear un Servidor Web, y de forma similar a FastAPI utiliza el módulo app.get para todas las rutas soportadas. Primero llama a una función para comprobar el auth token, y si tiene éxito llama a una función para obtener los datos solicitados.
|
1 2 3 4 5 6 |
aplicación.consiga('/api/v1/nickname/:nickname', checkToken, getRESTAPINickname); aplicación.consiga('/api/v1/nombreusuario/:nombreusuario', checkToken, getRESTAPIUsername); aplicación.consiga('/api/v1/id/:id', checkToken, getRESTAPIId); aplicación.consiga(/api/v1/picture/record/:id, checkToken, getRESTAPIPictureId); aplicación.consiga(/api/v1/picture/raw/:id, checkToken, getRESTAPIImageData); aplicación.consiga(/salud, getHealthCheckPage); |
Hay un módulo para las funciones de Couchbase ubicado en un archivo JavaScript, y las funciones para las llamadas a la API soportadas también están en módulos en archivos JavaScript separados. Al igual que con Python, hay un contenedor Node que se utiliza como base y la utilidad NPM mantiene las dependencias e inicia el servicio.
|
1 2 3 4 5 6 7 8 |
DESDE nodo:16.14.2 WORKDIR /aplicación AÑADE . /aplicación RUN rm -rf /aplicación/node_modules RUN npm instale -g npm@última RUN npm instale EXPONE 8080 CMD npm iniciar |
Kubernetes para poner en marcha Couchbase de forma autónoma
Como ya se ha mencionado, se eligió Kubernetes para probar las implementaciones de los servicios. Esto permitió acelerar las pruebas debido a la capacidad de desplegar y escalar rápidamente los servicios para diferentes escenarios de prueba. Hay dos opciones para usar Couchbase con Kubernetes. Se puede utilizar Couchbase Autonomous Operator para desplegar Couchbase en el entorno Kubernetes, o el servicio puede conectarse a un clúster externo. El servicio fue probado con un cluster externo que fue desplegado en la misma nube VPC. Todos los nodos estaban en la misma región de la nube, y tanto los nodos del clúster de Couchbase como los nodos de Kubernetes se desplegaron a través de zonas de disponibilidad para simular lo que probablemente se vería en un despliegue en el mundo real.
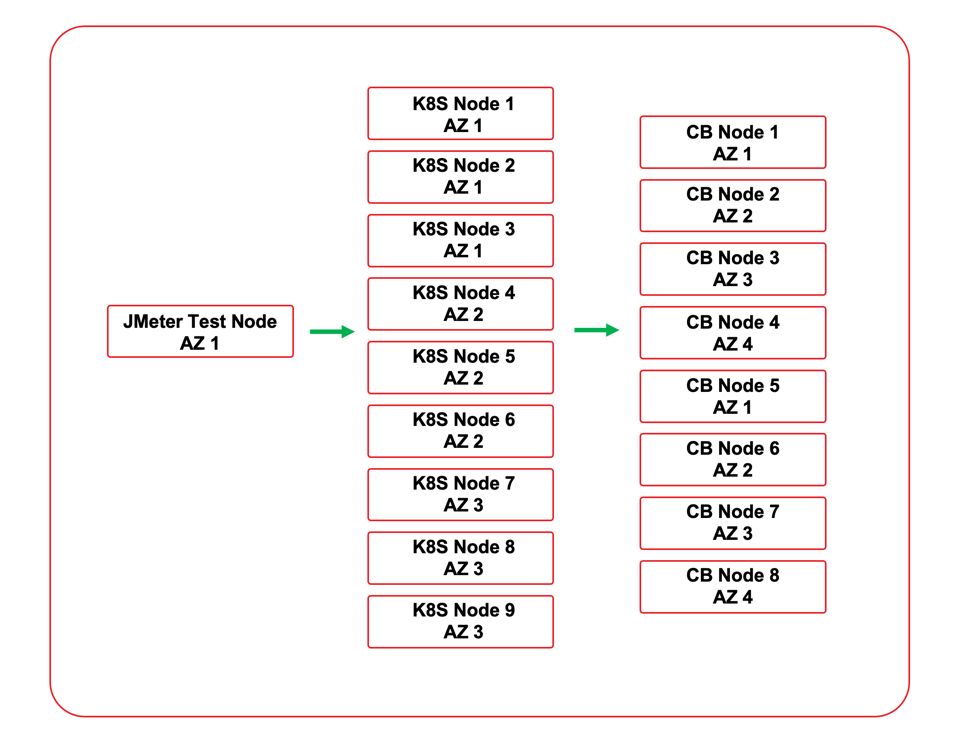
Se crearon tres archivos YAML de despliegue para desplegar las tres implementaciones. Cada YAML de despliegue crea un espacio de nombres para el servicio. Utiliza un secreto para la contraseña de Couchbase. El servicio se despliega inicialmente con 4 réplicas. Como es un microservicio sin estado, puede escalar hacia arriba y hacia abajo según sea necesario. El tráfico se dirige al servicio con un balanceador de carga. Como el entorno Kubernetes utilizado estaba integrado con un proveedor de nube, cada despliegue también aprovisionaba un equilibrador de carga de nube para el servicio.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
apiVersion: v1 amable: Espacio de nombres metadatos: nombre: demopy --- apiVersion: v1 amable: Secreto metadatos: nombre: demopy-secretos espacio de nombres: demopy tipo: Opaco datos: adminContraseña: aBcDeFgH= --- apiVersion: aplicaciones/v1 amable: Despliegue metadatos: nombre: demopy espacio de nombres: demopy spec: réplicas: 4 selector: matchLabels: aplicación: demopy estrategia: tipo: RollingUpdate rollingUpdate: maxDisponible: 25% maxSurge: 1 plantilla: metadatos: etiquetas: aplicación: demopy spec: contenedores: - nombre: demopy imagen: mminichino/demopy:1.0.5 imagePullPolicy: Siempre puertos: - nombre: aplicación-puerto containerPort: 8080 env: - nombre: SOPORTE_ANFITRIÓN valor: 1.2.3.4 - nombre: SOPORTE_USUARIO valor: Administrador - nombre: SOPORTE_CONTRASEÑA valorDesde: secretKeyRef: nombre: demopy-secretos clave: adminContraseña - nombre: SOPORTE_CUBO valor: sample_app --- apiVersion: v1 amable: Servicio metadatos: nombre: demopy-servicio espacio de nombres: demopy etiquetas: aplicación: demopy spec: selector: aplicación: demopy puertos: - nombre: http puerto: 8080 targetPort: 8080 tipo: LoadBalancer |
Utilizando los archivos YAML de despliegue, el servicio se puede desplegar y escalar según sea necesario con la CLI de Kubernetes. Opcionalmente, si se tratara de un entorno de producción real, se podrían utilizar herramientas como el autoescalado y el equilibrio de carga avanzado para controlar y acceder al despliegue.
|
1 2 |
$ kubectl aplicar -f demopy.yaml $ kubectl escala despliegue --réplicas=8 demopy -n demopy |
Resultados del rendimiento del clúster
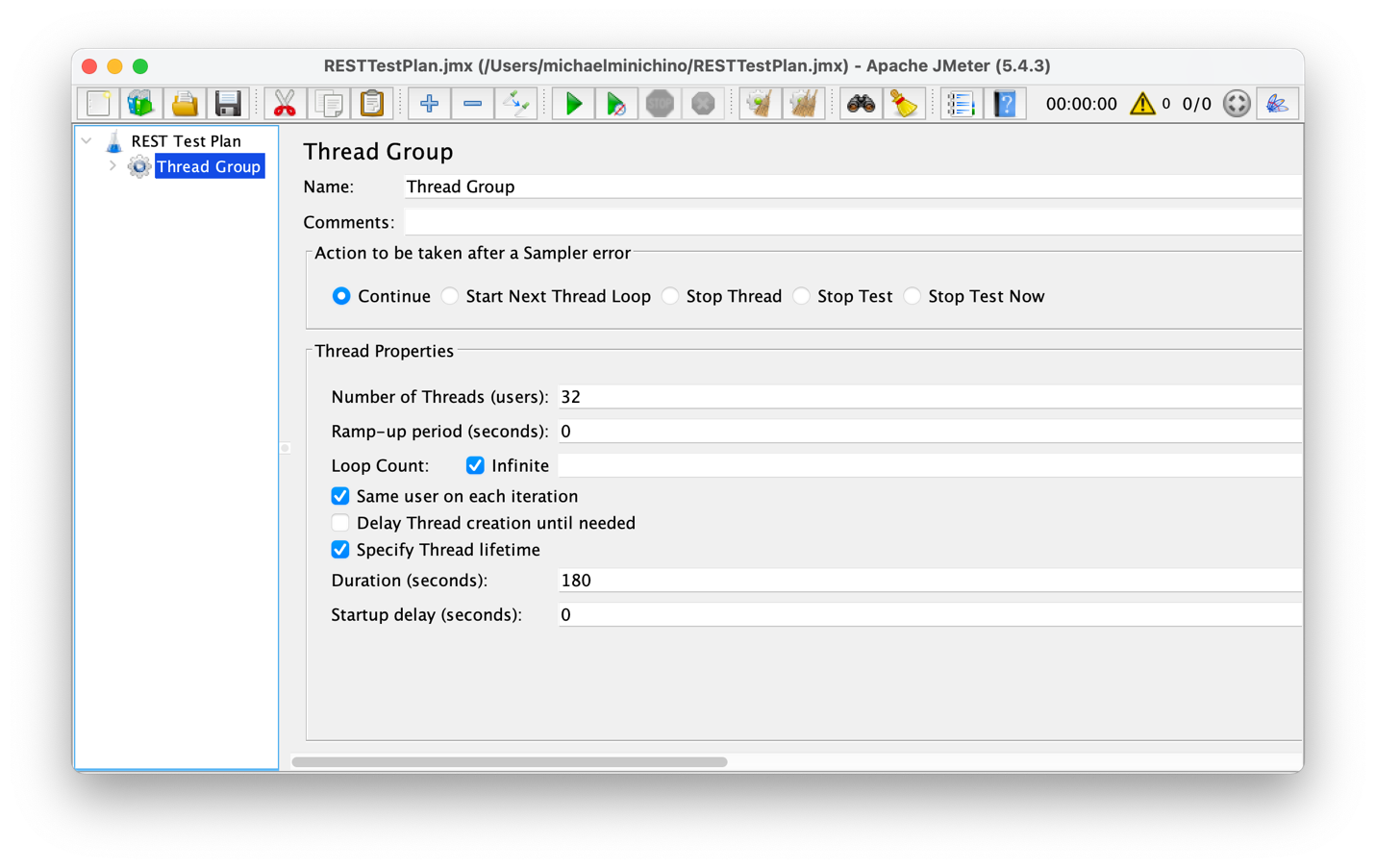
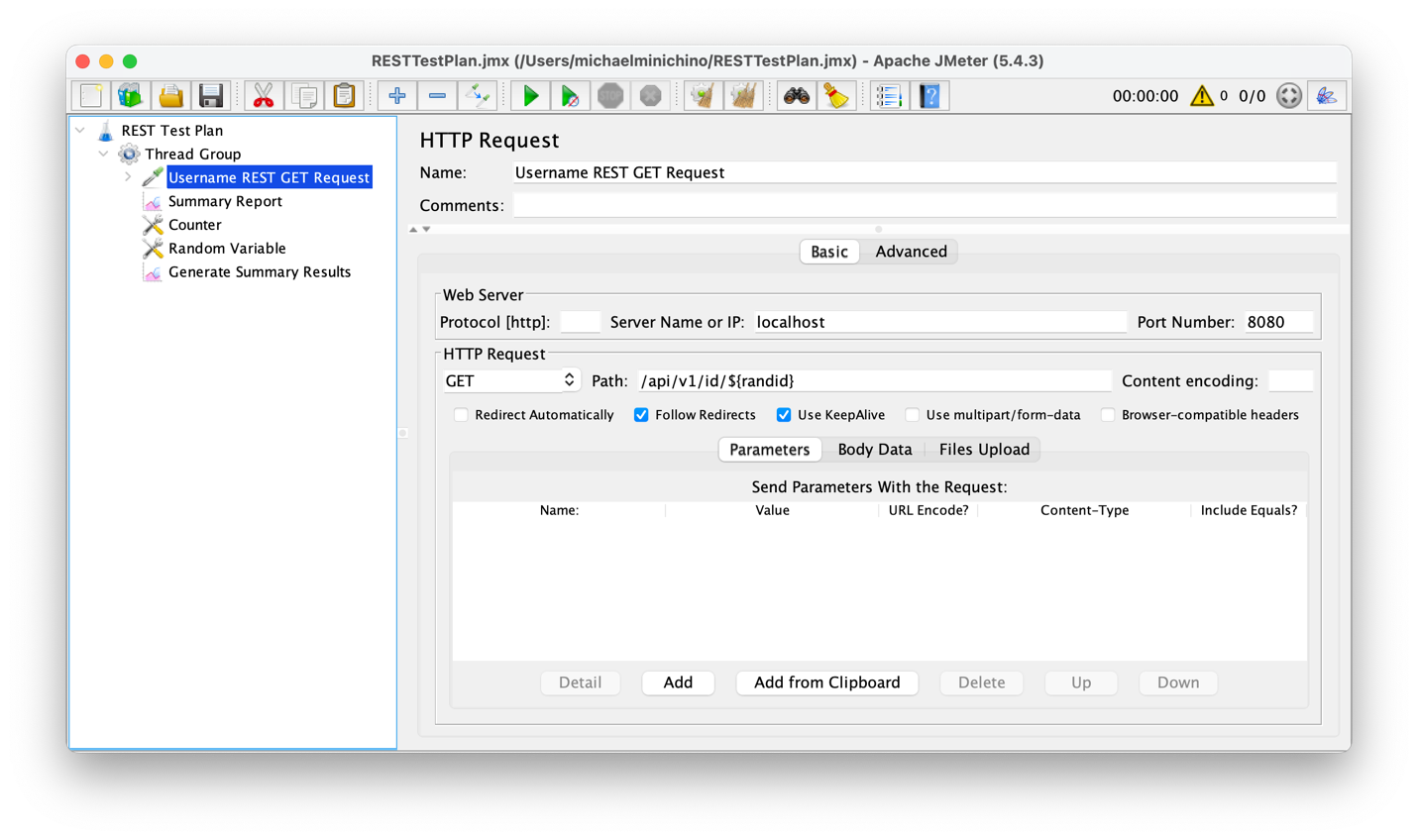
Antes de probar los servicios, se probó el clúster de Couchbase desde el clúster de Kubernetes para crear una línea de base. Se utilizó la carga de trabajo B de YCSB (que es principalmente clave-valor consiga operaciones) y se obtuvieron 156.094 ops/s. Las pruebas de la API se realizaron con Apache JMeter. Se utilizó la llamada a la API de ID para mantener la sencillez, y se aprovechó el generador de números aleatorios de JMeter para crear ejecuciones de prueba con perfiles de usuario aleatorios. El escenario de la prueba estaba limitado en el tiempo, con un tiempo de ejecución de tres minutos en el que se generaría una carga ilimitada contra el servicio del equilibrador de carga solicitando perfiles de usuario aleatorios sin aumento (la carga fue constante durante toda la duración de la prueba).
Para el primer conjunto de pruebas, los parámetros de prueba de JMeter no cambiaron, y lo que varió fue la escala de las tres implementaciones de la API. Las pruebas comenzaron con 4 Pods para cada implementación y escalaron a 8 y finalmente a 16 Pods. Todas las implementaciones escalaron el rendimiento a medida que los Pods escalaban en el despliegue.
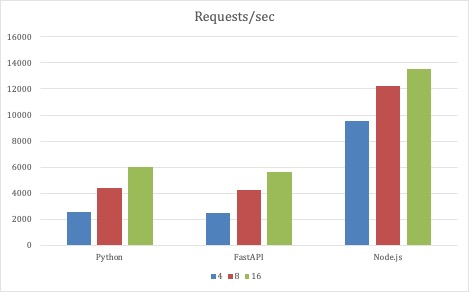
A Node.js le fue mejor con esta estrategia de prueba, ya que tuvo la latencia media más baja. Un milisegundo no es mucha latencia, como tampoco lo son 12 milisegundos. Pero con un número fijo de hilos generadores creando más de 1 millón de peticiones en tres minutos, los milisegundos tienen un efecto acumulativo. Sin embargo, hay que tener en cuenta que se trata de una prueba extrema. Son sólo puntos de datos. Lo sorprendente fue que el servicio Python de código completo mantuvo el ritmo de la implementación FastAPI.
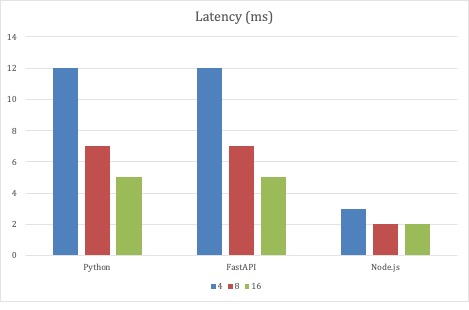
Dado que el primer escenario de pruebas demostró que tanto el código completo de Python como las implementaciones FastAPI eran escalables, la segunda ronda de pruebas escaló el número de hilos de petición con un número fijo de 32 Pods de servicio. Con este escenario de pruebas, los servicios basados en Python podían escalar cerca de 10.000 peticiones por segundo.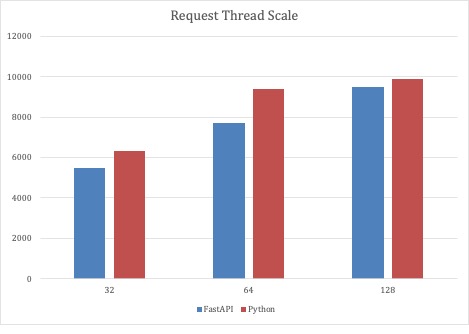
Conclusiones
Creo que Python es una opción excelente para servicios de carga moderada. Con todas las pruebas realizadas, los nodos del clúster Kubernetes tenían una amplia disponibilidad de CPU y memoria, por lo que había mucho margen para escalar el servicio según fuera necesario. Para implementaciones que requieren una escala masiva con la latencia más baja, entonces Node.js puede ser una mejor opción. Couchbase soporta todos los lenguajes prevalentes, así que al igual que yo fui capaz de codificar fácilmente tres implementaciones de microservicios, cualquiera puede usar múltiples lenguajes y frameworks e integrar Couchbase con facilidad.
A continuación
En la próxima entrada de esta serie de blogs, hablaré sobre la generación de datos de prueba aleatorios para el esquema de microservicios. Aquí están los enlaces a los recursos mencionados en este post:
- Construir un microservicio Python con Couchbase - Parte 1
- Parte 2 - Código fuente del microservicio para el perfil de usuario
- Oferta de Capella Couchbase Cloud
- Operador autónomo de Couchbase
Dato curioso aleatorio
Los códigos de respuesta HTTP se definen en la especificación del protocolo. El rango 400 está reservado para situaciones en las que el error parece haber sido causado por el cliente. HTTP 418 es el error "Soy una tetera" y la especificación establece que el código de respuesta "I'm a teapot client error response code indicates that the server refuses to brew coffee because it is, permanently, a teapot. Una cafetera/tetera combinada que esté temporalmente sin café debería devolver en su lugar 503".

¡Buen post!
Creo que fastapi sufre mucho por el serializador por defecto, también pydantic mientras que es bastante rápido está haciendo la validación de los datos de salida y, probablemente, teniendo un montón de tiempo allí.