Recently, as I was exploring our documentation to acquaint myself with the capabilities of Elasticsearch Connector 4.2, I came across a configuration called Pipeline. I was curious to explore and understand what it means and what purpose does this solve. While doing so, I experimented with the connector and its configuration and I wanted to share my experience through this post.
Overview
In this post, we are going to cover replicating and transforming travel-sample’s landmark dataset from Couchbase to Elasticsearch using Elasticsearch connector and an Elasticsearch Ingest node pipeline.
Let’s take a quick look at the different components that we will be using throughout this blog post.
Couchbase is an Open Source, distributed, JSON document database. It exposes a scale-out, key-value store with managed cache for sub-millisecond data operations, purpose-built indexers for efficient queries and a powerful query engine for executing SQL-like queries.
Elasticsearch is a full-text, distributed NoSQL database with a powerful search and analytics engine at the heart of Elastic Stack. Elasticsearch stores documents in Index (sometimes referred to as Indices?) which are analogous to tables in sql world.
Ingest Node Pipeline is a powerful tool that Elasticsearch gives you in order to pre-process your documents before they are indexed. An Ingest node pipeline consists of one or more processors that are executed in the order it is declared. Elasticsearch comes with a set of processors out of the box, you can also build a custom processor as needed, for a list of all processors visit the documentation here.
Elasticsearch Connector is a tool built by Couchbase that enables replication of data from Couchbase to Elasticsearch.
Kibana is a free and open user interface that lets you visualize your Elasticsearch data and navigate the Elastic Stack. Kibana also enables management and evaluation of Ingest node pipelines.
Prerequisites & Assumptions
This post assumes that you have a basic understanding of all of the components as listed above and you are using a computer running macOS to walk through the illustration.
-
-
- Install and configure Couchbase Server with a travel-sample dataset by following the instructions here.
- Install a compatible version of java.
-
Get Started
Launch a new terminal window and navigate to your user directory located under /Users/<username>. Create a new directory called Connectors. We will refer to this as “BASE_DIR” for the remainder of the post.
|
1 |
mkdir Connectors |
Install & Launch Elasticsearch and Kibana
-
-
Download the latest version of Elasticsearch and Kibana and move them into the BASE_DIR. You should see two files Elasticsearch-<version>-darwin-x86_64.tar.gz and kibana-<version>-darwin-x86_64.tar.tz.
-
Uncompress the downloaded files and rename the directory to es and kibana
-
Launch a new terminal and navigate to BASE_DIR and then type the following commands (one at a time)
|
1 |
tar -xzvf elasticsearch-7.8.0-darwin-x86_64.tar.gz && tar -xzvf kibana-7.8.0-darwin-x86_64.tar.gz |
|
1 |
mv elasticsearch-7.8.0-darwin-x86_64 es && mv kibana-7.8.0-darwin-x86_64 kibana |
3. Launch Elasticsearch
Launch a new terminal window and navigate to the directory BASE_DIR/es then type the following command
|
1 |
bin/elasticsearch |
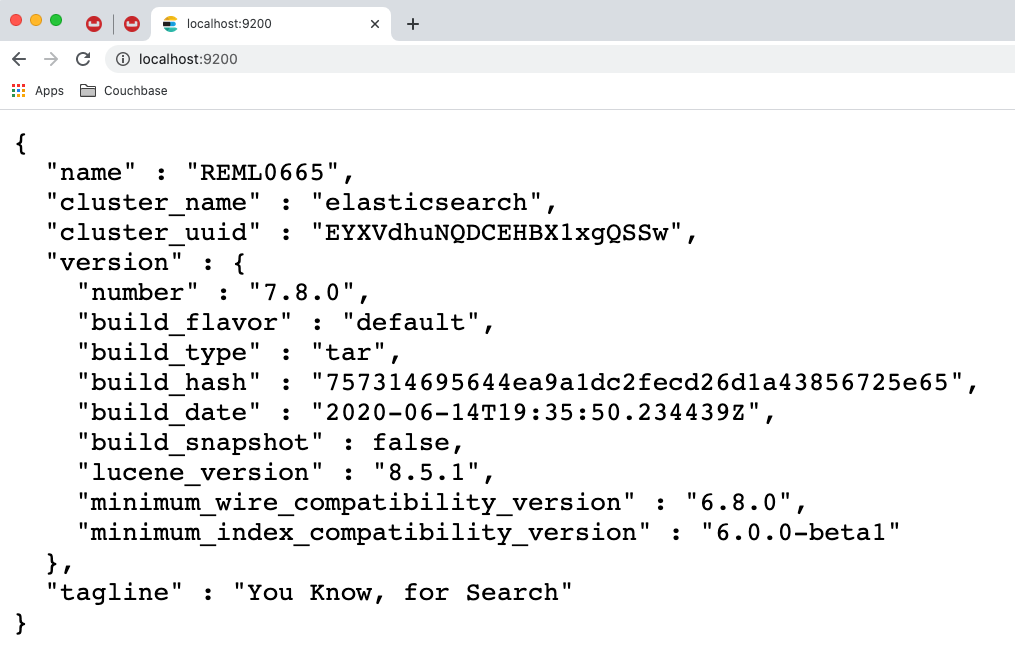
Now open a web browser and navigate to http://localhost:9200.You should see a response like the one below, indicating that the Elasticsearch server is available.
4. Launch Kibana
Launch a new terminal window and navigate to the directory BASE_DIR/kibana then type the following command
|
1 |
bin/kibana |
To see Kibana in action, open a web browser and navigate to http://localhost:5601 .
Install Elasticsearch Connector
-
-
Download the latest version of Elasticsearch connector and move it to the BASE_DIR. At the time of writing this post, the most recent version of the connector available is 4.2.2. You should have downloaded a file that looks something like couchbase-elasticsearch-connector-<version>.zip.
-
Uncompress the downloaded file and rename the directory to cbes.
-
Launch a new terminal and navigate to BASE_DIR and type the following commands (one at a time). When prompted enter “A” to uncompress the files
|
1 |
unzip couchbase-elasticsearch-connector-4.2.2.zip |
|
1 |
mv couchbase-elasticsearch-connector-4.2.2 cbes |
Now let’s explore the some of the important directories within cbes
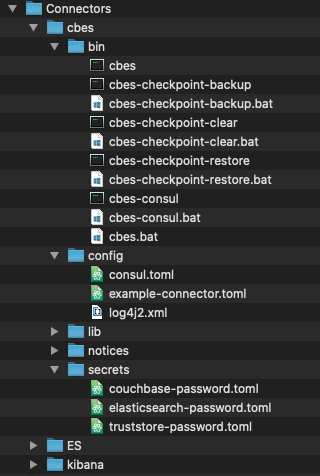
bin – contains all the command line utilities required to help manage connectors.
config – contains base configuration file that can be used as reference.
secrets – contains credentials to connect to Couchbase and Elasticsearch servers.
Build Elasticsearch Ingest Node Pipeline
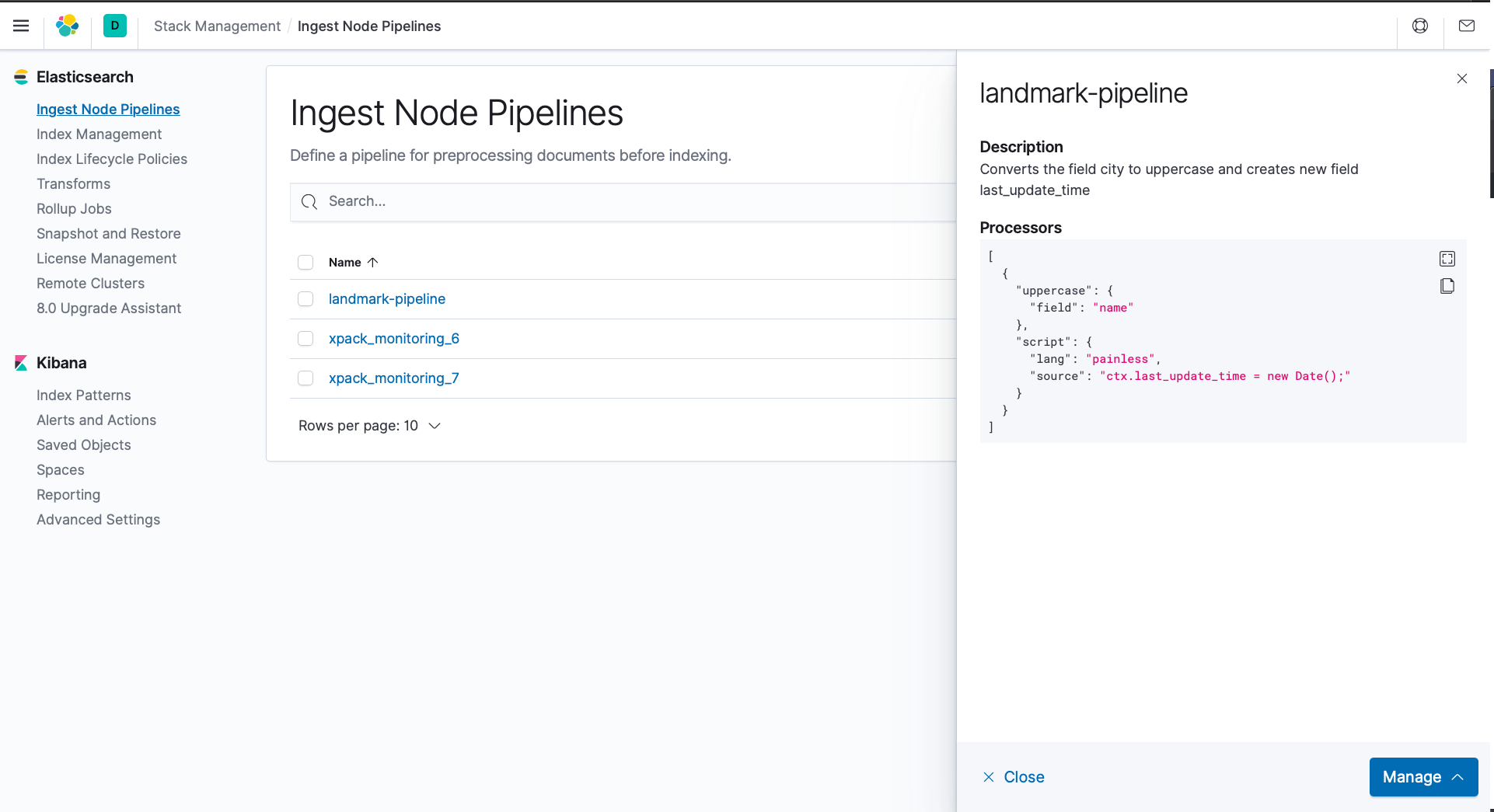
Let’s build our pipeline. We will name it “landmark-pipeline”. Our pipeline will
-
-
-
- Insert a new field
last_update_time which will be the current date-time. - Convert the data to UPPERCASE for field
name.
- Insert a new field
-
-
We will be using two of the existing processors to build our ingestion pipeline.
Script Processor : Executes any script defined by the painless scripting language.
Uppercase Processor : Converts the specified field’s value into UPPERCASE
1. Launch a new terminal window and execute the following command
|
1 2 3 4 5 |
curl -X PUT "localhost:9200/_ingest/pipeline/landmark-pipeline?pretty" -H 'Content-Type: application/json' -d' { "description" : "Converts the field name to uppercase and creates new field last_update_time ", "processors" : [ { "uppercase": { "field": "name" }, "script": { "lang": "painless", "source": "ctx.last_update_time = new Date();" } } ] }' |
The curl command above creates and saves a pipeline definition within Elasticsearch database.
2. Open a web browser and navigate to Kibana at http://localhost:5601. You should be able to see the pipeline that you had just created under Discover -> Ingest Node Pipelines.
Configure Elasticsearch Connector
1. Launch a new terminal window and navigate to BASE_DIR/cbes/config
2. Copy the file example-connector.toml and name it as default-connector.toml by executing the following command
|
1 |
cp example-connector.toml default-connector.toml |
Connector assumes the existence of a configuration file default-connector.toml and reads this file for any configuration. However you can also specify the configuration when deploying the connector by using a – -config command line option. For this post we will use the default configuration.
3. Open default-connector.toml in the editor of your choice and modify the following configuration settings.If you want further information about the Elasticsearch Connector configuration settings, go here.
If you want to skip this step, a complete modified configuration file can be found here.
Tip: If this is your first time working with the TOML config file format, check out Nate Finch’s excellent Intro to TOML, or the official specification.
a ) Under the [group] table, set the name key to “landmark-example-group”
|
1 2 |
[group] name = 'landmark-example-group' |
b) Under the [elasticsearch.docStructure] table, set the documentContentAtTopLevel key to “true”
|
1 2 |
[elasticsearch.docStructure] documentContentAtTopLevel = true |
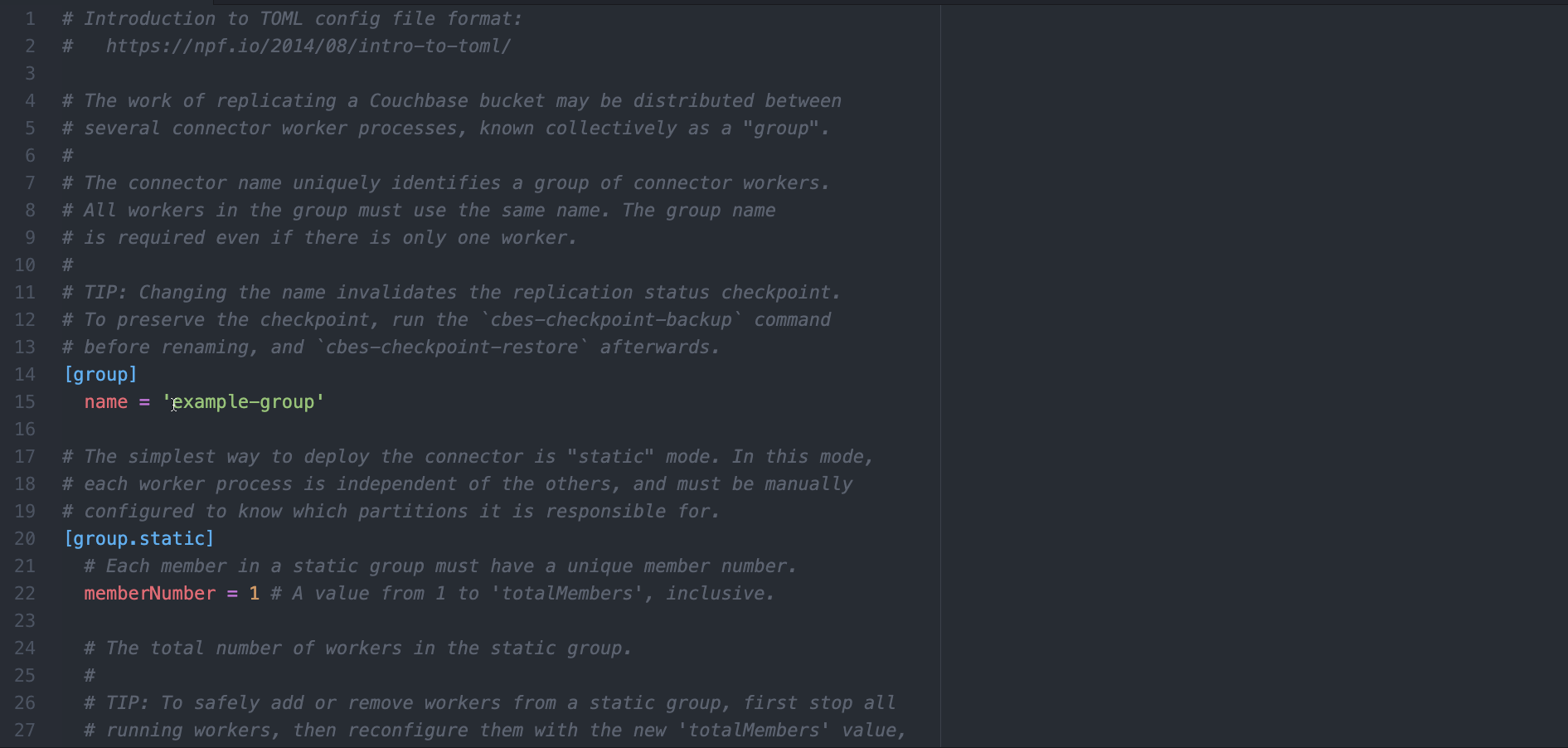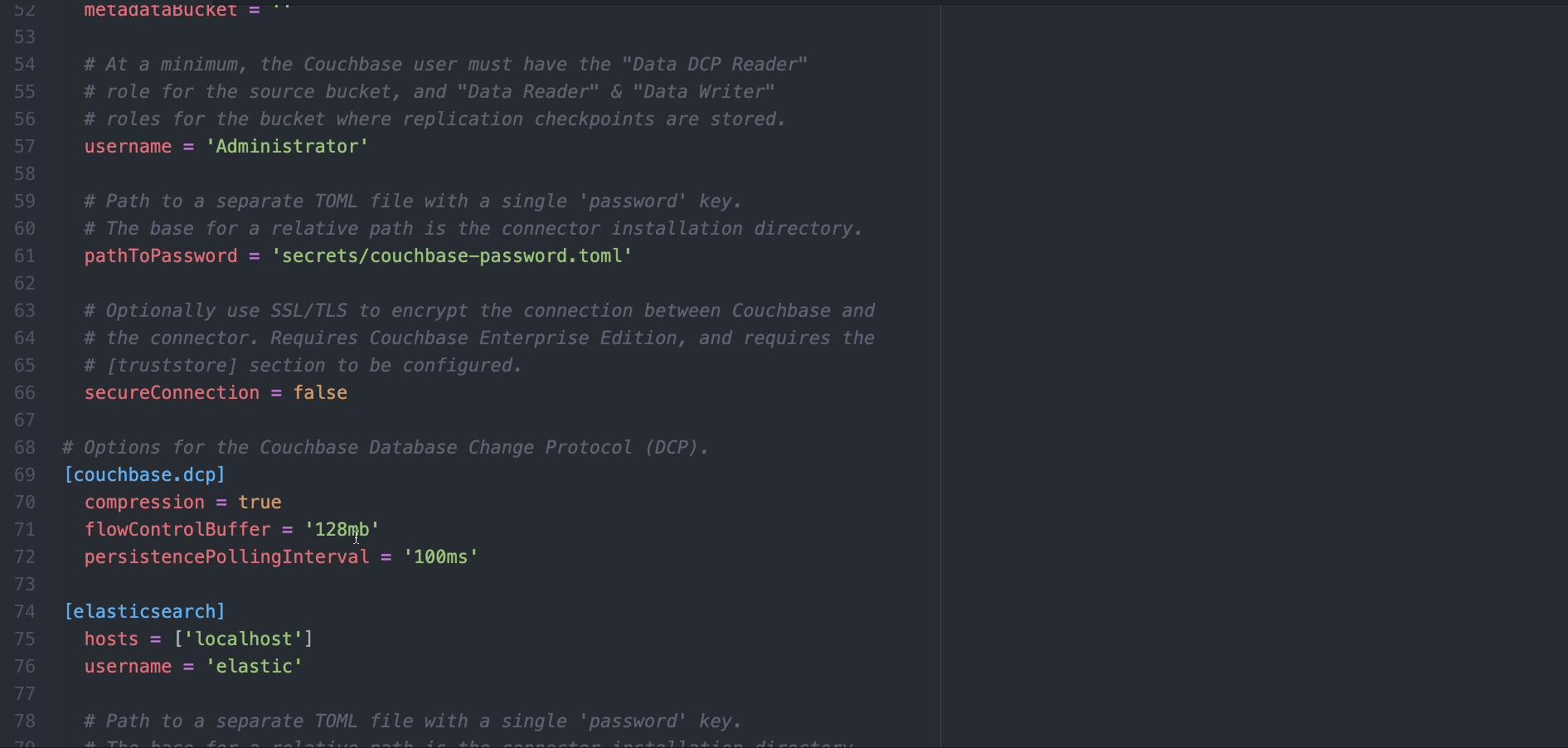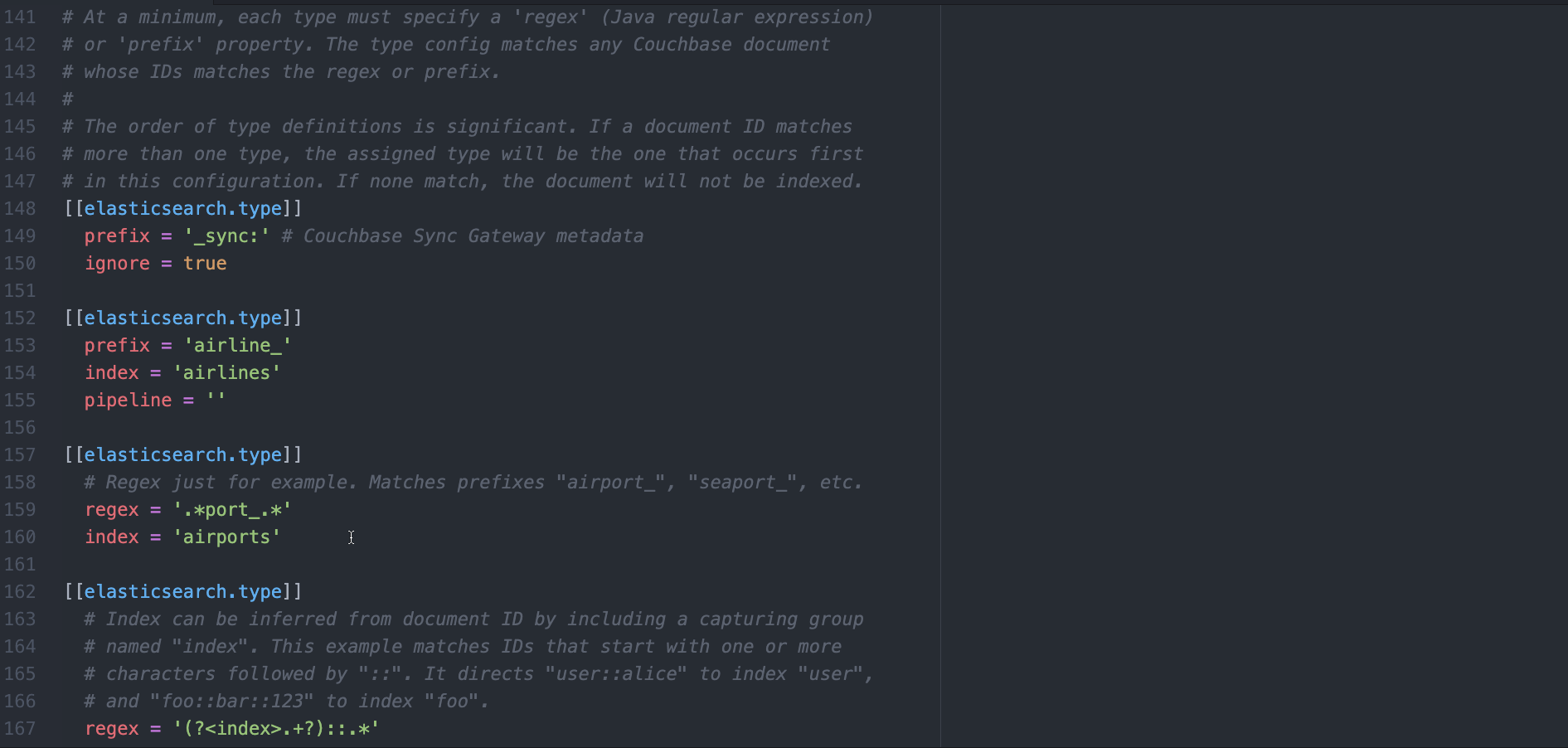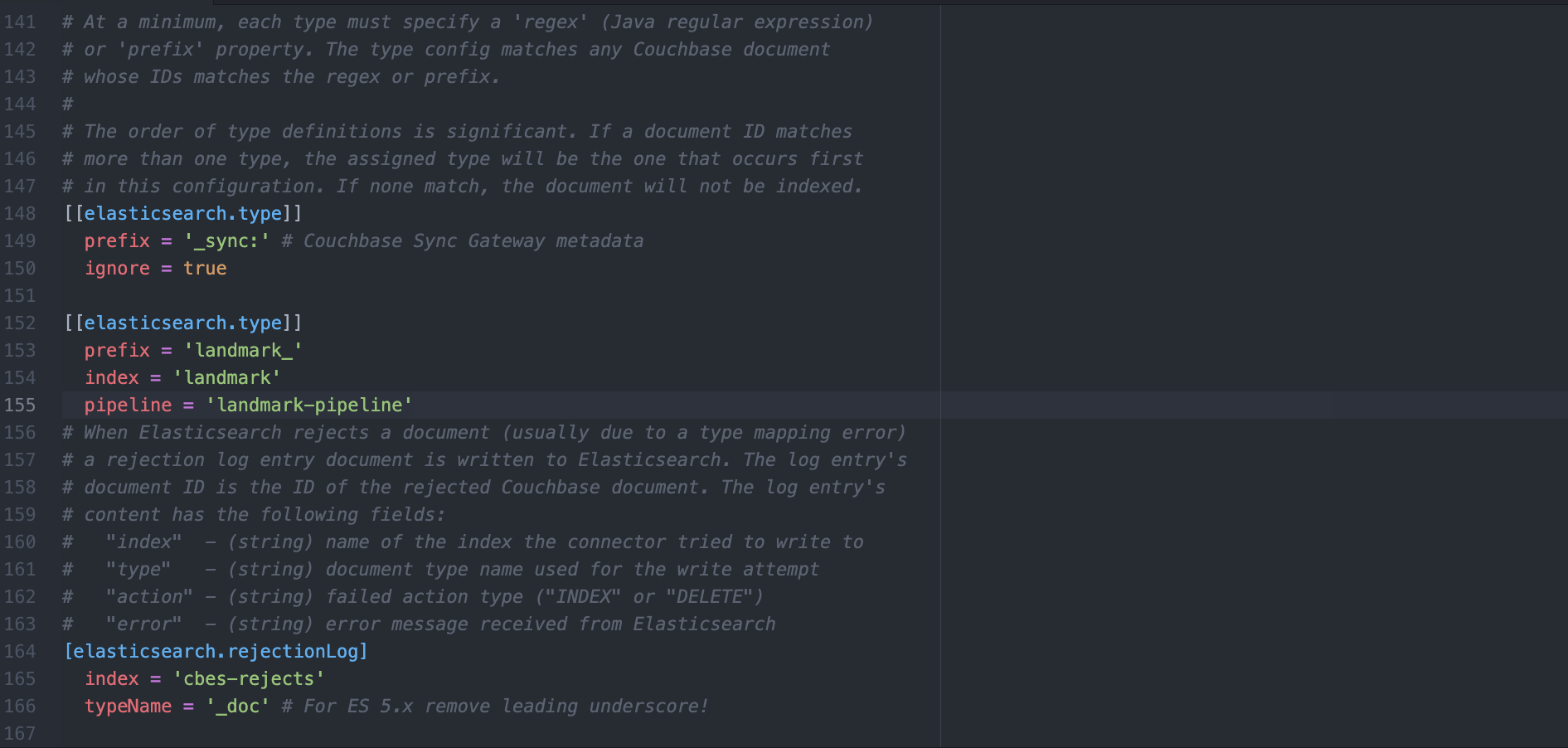
c) Remove any existing [[elasticsearch.type]] tables and replace with the following.
|
1 2 3 4 5 6 7 8 |
[[elasticsearch.type]] prefix = '_sync:' ignore = true [[elasticsearch.type]] prefix = 'landmark_' index = 'landmark' pipeline = 'landmark-pipeline' |
Deploy Elasticsearch Connector
You are all set. It’s time to see all of this in action now.
Elasticsearch connectors can be deployed three different modes
Solo : This is the simplest mode where the connector runs as a standalone process. Solo mode is preferable in a low-traffic environment or in a development environment.
Distributed : In this mode multiple connectors run as different processes. In a scenario when the traffic is moderate to high, this mode is recommended. Unlike the solo mode where only one dedicated process does the whole work, in a distributed mode there is more than one process and each connector is configured independently to share the workload.
Autonomous Operations Mode : This can be thought through as a distributed mode managed by a coordinated service. The coordinated service takes care of service discovery and configuration management. Unlike the distributed mode where the processes need to be stopped and restarted before adding and removing a connector process, the coordinated service automatically distributes the workload when a worker process is added or removed even in failure cases.
For this post we will be deploying the connector in a Solo mode. Before starting the connector let’s verify the document count at the source in Couchbase.
1. Open a web browser and navigate to Couchbase cluster for instance http://127.0.0.1:8091/ui/index.html
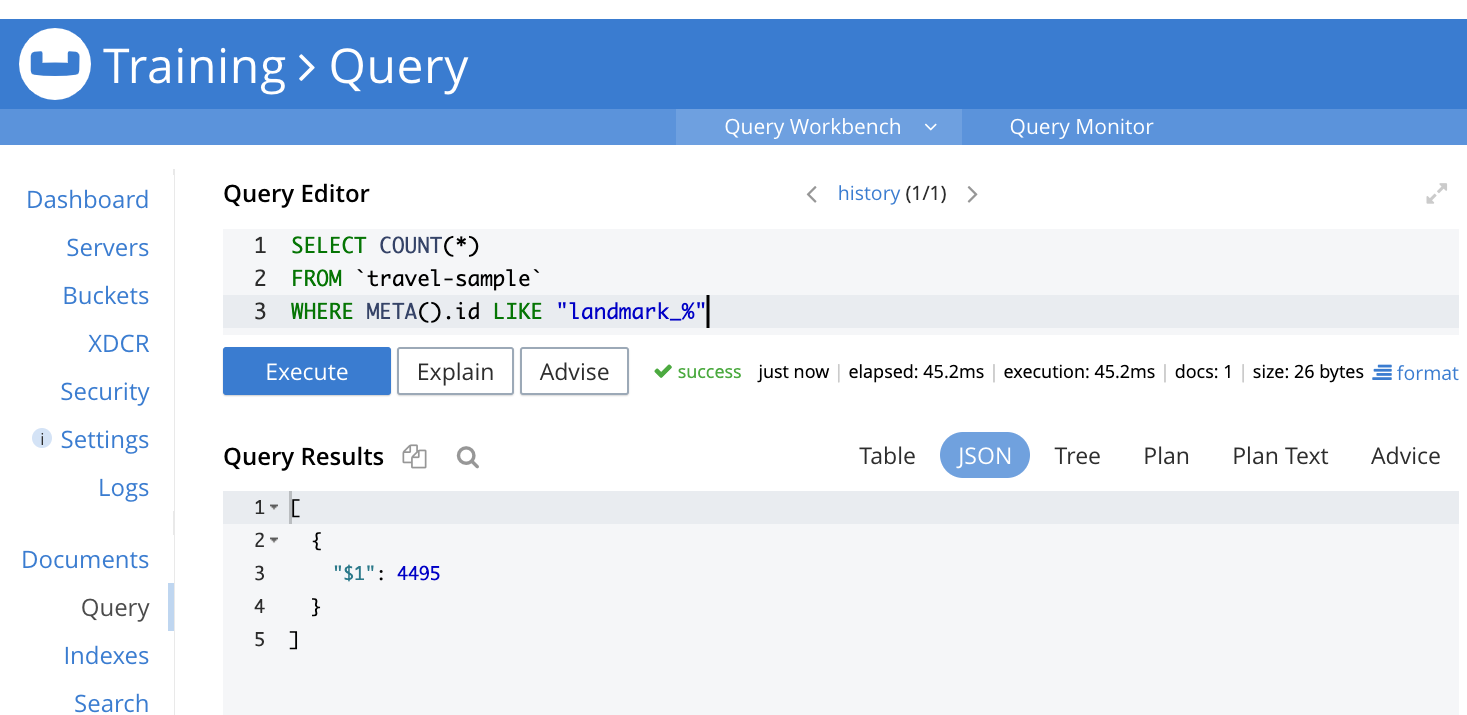
Go to Query menu and execute the following query
|
1 2 3 |
SELECT COUNT(*) FROM `travel-sample` WHERE META().id LIKE ‘landmark_%’ |
This query should return the count of documents in the travel-sample bucket where the document key begins with “landmark_”. In our case the count is 4495 documents.
2. Let’s start our connector.
Launch a new terminal window and navigate to BASE_DIR/cbes directory and type the following command
|
1 |
bin/cbes |
The connector should start copying documents (where document key begins with “landmark_”) from the Couchbase travel-sample bucket into Elasticsearch. While this happens, the Ingest node pipeline will convert the values for name to uppercase and also create a last_update_time field.
3. Now let’s verify if the desired transformations were applied when the documents were replicated.
Open a new browser and navigate to Kibana at http://localhost:5601
-
-
-
- Navigate to Discover -> Index Patterns and Define an Index pattern. You should see landmark as a choice.
- Next Navigate to Index Management under Discover -> Index Management. It should show you the desired document count (4495).
- To see the actual document with transformation, open a new browser window and navigate to Kibana at http://localhost:5601. Navigate to Discover and on the right hand side under _source you should see “>” symbol. Click on it and then click on JSON. You should see the document as below
-
-
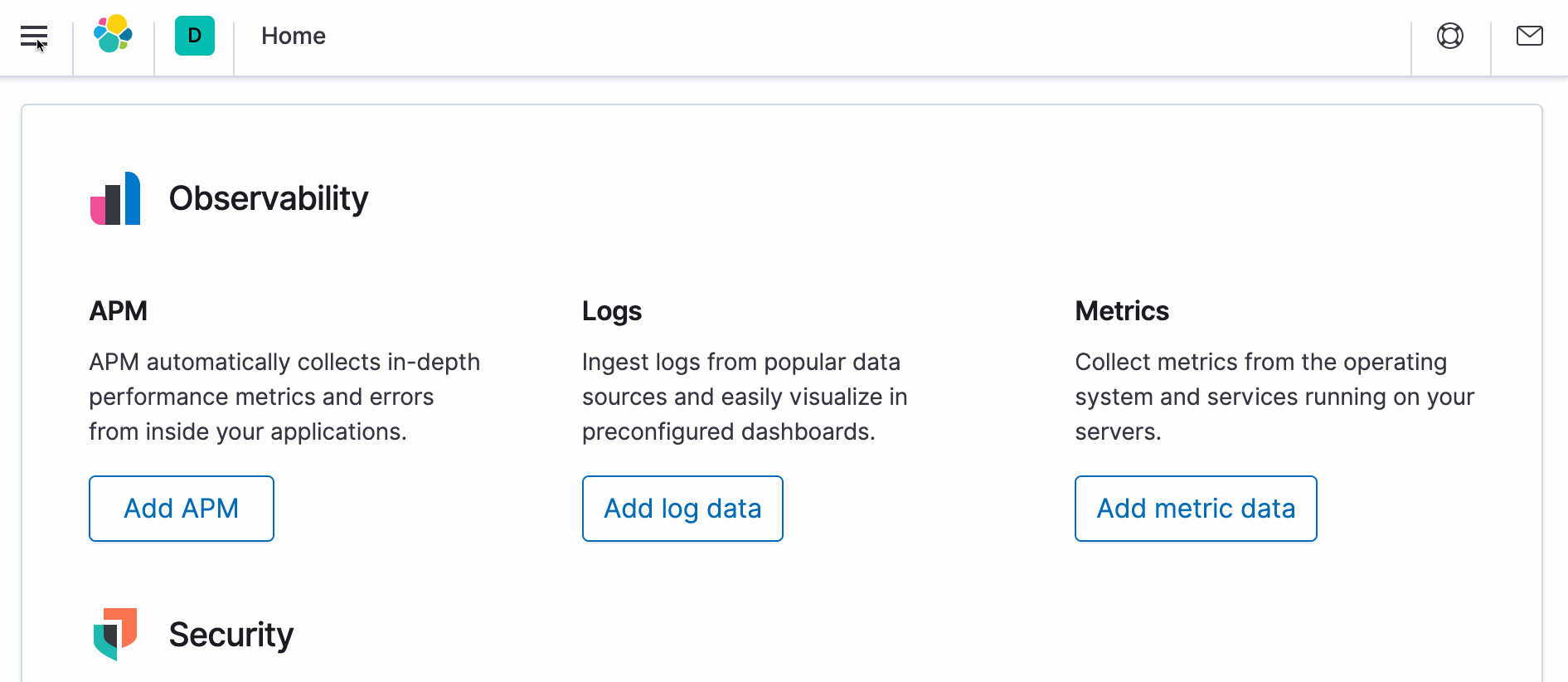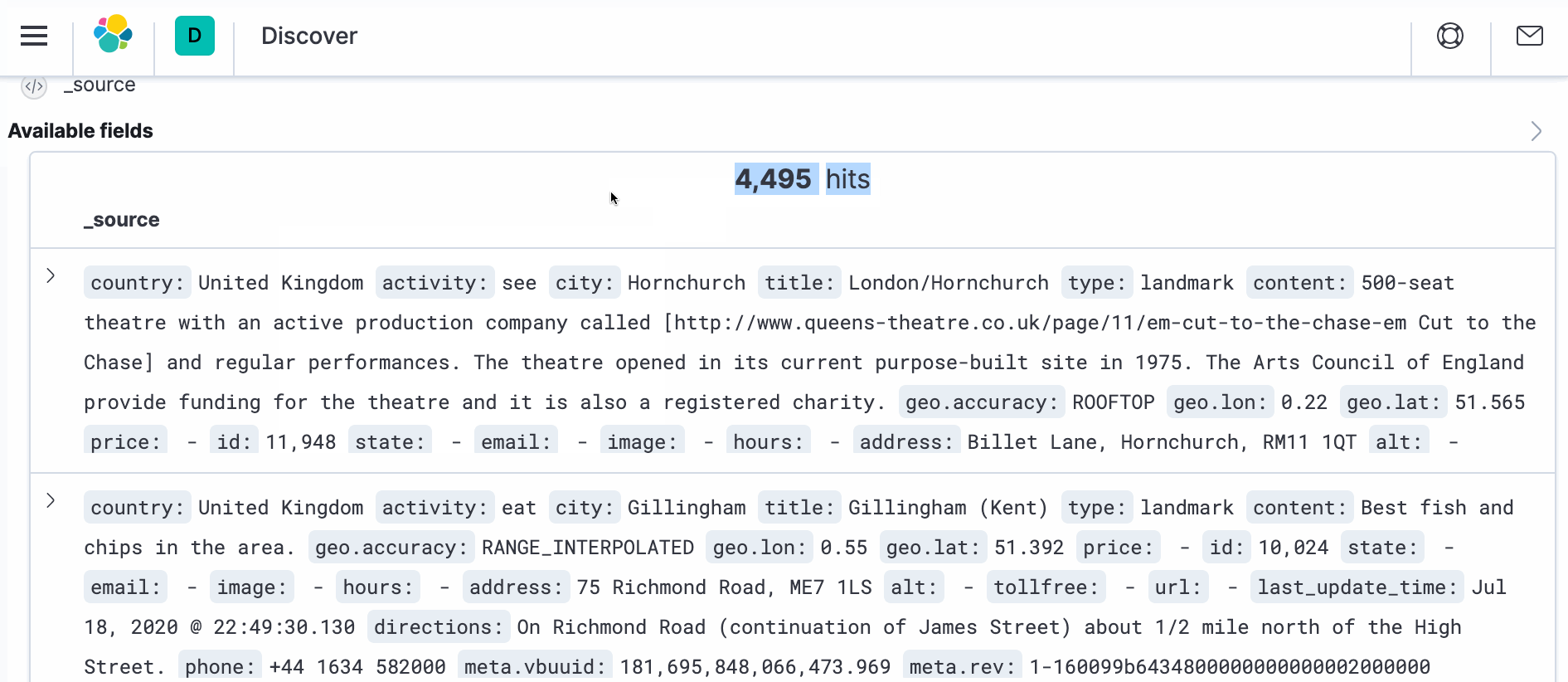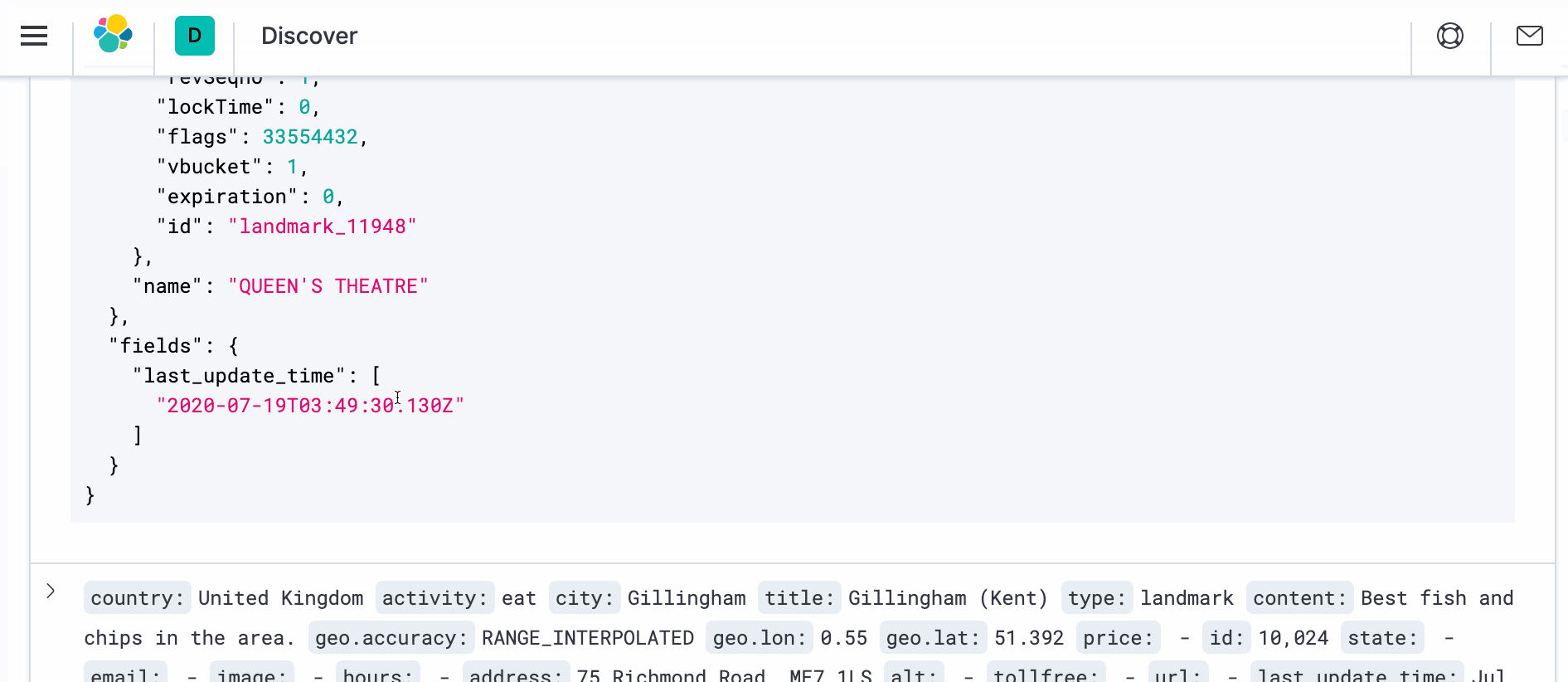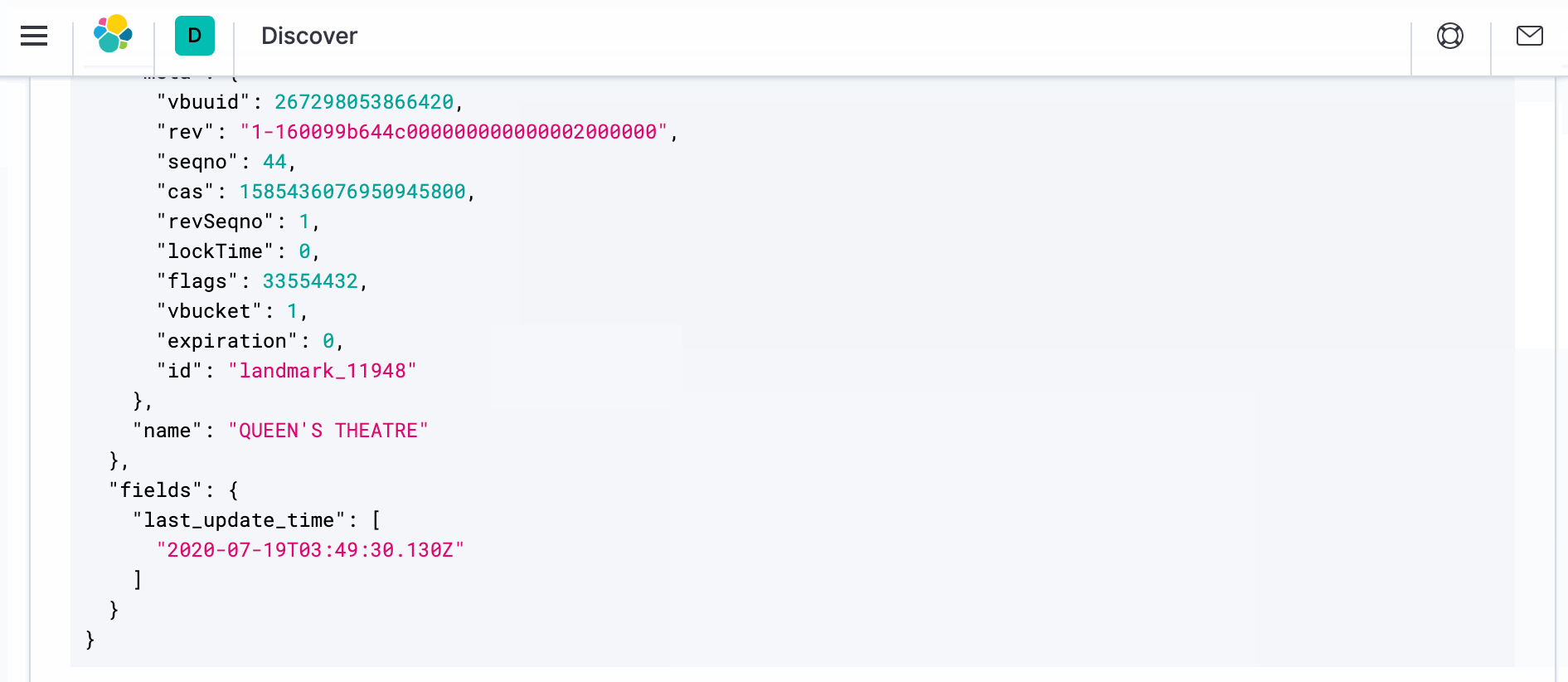
Repeat
If you want to try the same example with the same dataset but a different processor, or if you encountered an error and you want to start it all over, it’s very simple. All you need to do is
-
-
-
Stop the process running Kibana (press control + C)
-
Delete all data from Elasticsearch by launching a new terminal and typing the following command
-
-
|
1 |
curl -X DELETE 'http://localhost:9200/_all' |
3. Stop the process running Elasticsearch connector (press control + C)
4. Clear connector checkpoint by launching a new terminal and typing the following command
|
1 |
cbes-checkpoint-clear |
5. Restart Kibana, modify pipeline , modify connector configuration as desired and restart the connector.
Conclusion
We have examined how to use the Couchbase Elasticsearch connector, to replicate a dataset from Couchbase to Elasticsearch in a solo mode using an Ingest node pipeline. Now you’re ready to explore different Pipeline processors and configuration settings within Elasticsearch connector.
Finally a “BIG THANK YOU” to my colleagues Matt Ingenthron, David Nault and Jared Casey for helping me get to the finish line of this blog !
If you liked this post or have any questions please leave your comments.