Recientemente, mientras exploraba nuestra documentación para familiarizarme con las capacidades de Elasticsearch Connector 4.2, me encontré con una configuración llamada Pipeline. Tenía curiosidad por explorar y entender qué significa y qué propósito resuelve. Mientras lo hacía, experimenté con el conector y su configuración y quería compartir mi experiencia a través de este post.
Visión general
En este post, vamos a cubrir la replicación y transformación de muestra-viaje landmark dataset de Couchbase a Elasticsearch usando Elasticsearch connector y un pipeline de nodos Elasticsearch Ingest.
Echemos un vistazo rápido a los diferentes componentes que utilizaremos a lo largo de esta entrada de blog.
Couchbase es una base de datos de documentos JSON distribuida y de código abierto. Ofrece un almacén de claves y valores escalable con caché gestionada para operaciones de datos por debajo del milisegundo, indexadores específicos para consultas eficientes y un potente motor de consulta para ejecutar consultas de tipo SQL.
Elasticsearch es una base de datos NoSQL distribuida de texto completo con un potente motor de búsqueda y análisis en el corazón de Elastic Stack. Elasticsearch almacena documentos en índices, que son análogos a las tablas del mundo sql.
Canalización de nodos de ingesta es una potente herramienta que Elasticsearch pone a su disposición para preprocesar sus documentos antes de que sean indexados. Una canalización de nodo de ingesta consiste en uno o más procesadores que se ejecutan en el orden en que se declaran. Elasticsearch viene con un conjunto de procesadores fuera de la caja, también puede construir un procesador personalizado según sea necesario, para obtener una lista de todos los procesadores visite la documentación aquí.
Conector Elasticsearch es una herramienta creada por Couchbase que permite replicar datos de Couchbase a Elasticsearch.
Kibana es una interfaz de usuario abierta y gratuita que permite visualizar los datos de Elasticsearch y navegar por Elastic Stack. Kibana también permite gestionar y evaluar canalizaciones de nodos de ingesta.
Requisitos previos y supuestos
Este post asume que usted tiene una comprensión básica de todos los componentes enumerados anteriormente y que está utilizando un equipo que ejecuta macOS para caminar a través de la ilustración.
-
-
- Instale y configure Couchbase Server con un conjunto de datos de muestra de viajes siguiendo las instrucciones aquí.
- Instale un compatible versión de java.
-
Comenzar
Abra una nueva ventana de terminal y navegue hasta su directorio de usuario situado en /Usuarios/. Cree un nuevo directorio llamado Conectores. Lo denominaremos "BASE_DIR" para el resto del post.
|
1 |
mkdir Connectors |
Instalar e iniciar Elasticsearch y Kibana
-
-
Descargar la última versión de Elasticsearch y Kibana y trasladarlos al BASE_DIR. Debería ver dos archivos Elasticsearch--darwin-x86_64.tar.gz y kibana--darwin-x86_64.tar.tz.
-
Descomprima los archivos descargados y cambie el nombre del directorio a es y kibana
-
Inicie un nuevo terminal y vaya a BASE_DIR y luego tealice los siguientes comandos (de uno en uno)
|
1 |
tar -xzvf elasticsearch-7.8.0-darwin-x86_64.tar.gz && tar -xzvf kibana-7.8.0-darwin-x86_64.tar.gz |
|
1 |
mv elasticsearch-7.8.0-darwin-x86_64 es && mv kibana-7.8.0-darwin-x86_64 kibana |
3. Iniciar Elasticsearch
Abra una nueva ventana de terminal y navegue hasta el directorio BASE_DIR/es entonces tEscriba el siguiente comando
|
1 |
bin/elasticsearch |
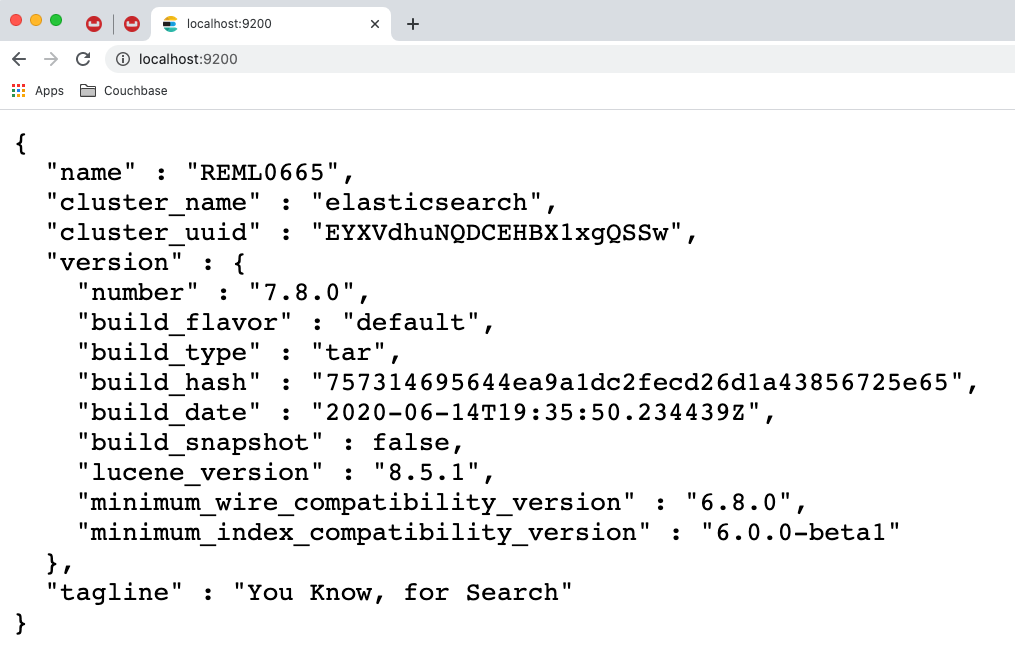
Ahora abra un navegador web y navegue hasta https://localhost:9200Debería ver una respuesta como la siguiente, indicando que el servidor Elasticsearch está disponible.
4. Iniciar Kibana
Abra una nueva ventana de terminal y navegue hasta el directorio BASE_DIR/kibana entonces tEscriba el siguiente comando
|
1 |
bin/kibana |
Para ver Kibana en acción, abra un navegador web y navegue hasta https://localhost:5601 .
Instalar el conector Elasticsearch
-
-
Descargar la última versión del conector de Elasticsearch y moverlo al BASE_DIR. En el momento de escribir este post, la versión más reciente del conector disponible es la 4.2.2. Deberías haber descargado un archivo parecido a couchbase-elasticsearch-connector-<version>.zip.
-
Descomprima el archivo descargado y cambie el nombre del directorio a cbes.
-
Inicie un nuevo terminal y vaya a BASE_DIR y tealice los siguientes comandos (de uno en uno). Cuando se le solicite, introduzca "A" para descomprimir los archivos
|
1 |
unzip couchbase-elasticsearch-connector-4.2.2.zip |
|
1 |
mv couchbase-elasticsearch-connector-4.2.2 cbes |
Ahora vamos a explorar algunos de los directorios importantes dentro de cbes
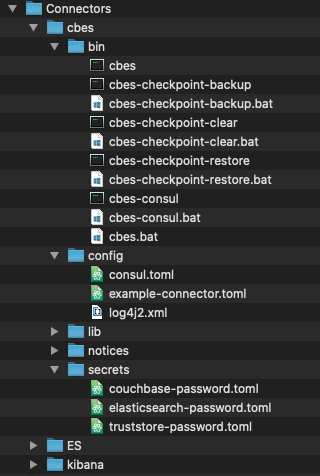
papelera - contiene todas las utilidades de línea de comandos necesarias para ayudar a gestionar los conectores.
config - contiene el archivo de configuración base que puede utilizarse como referencia.
secretos - contiene las credenciales para conectarse a los servidores Couchbase y Elasticsearch.
Construir Elasticsearch Ingest Node Pipeline
Construyamos nuestro oleoducto. La llamaremos "hito-pipeline". Nuestro gasoducto
-
-
-
- Insertar un nuevo campo
hora_última_actualización que será la fecha-hora actual. - Convertir los datos a MAYÚSCULAS para el campo
nombre.
- Insertar un nuevo campo
-
-
Utilizaremos dos de los procesadores existentes para construir nuestro canal de ingesta.
Procesador de guiones : Ejecuta cualquier script definido por el lenguaje de scripting indoloro.
Procesador de mayúsculas : Convierte el valor del campo especificado en MAYÚSCULAS
1. Abra una nueva ventana de terminal y ejecute el siguiente comando
|
1 2 3 4 5 |
curl -X PUT "localhost:9200/_ingest/pipeline/landmark-pipeline?pretty" -H 'Content-Type: application/json' -d' { "description" : "Converts the field name to uppercase and creates new field last_update_time ", "processors" : [ { "uppercase": { "field": "name" }, "script": { "lang": "painless", "source": "ctx.last_update_time = new Date();" } } ] }' |
El comando curl anterior crea y guarda una definición de canalización en la base de datos Elasticsearch.
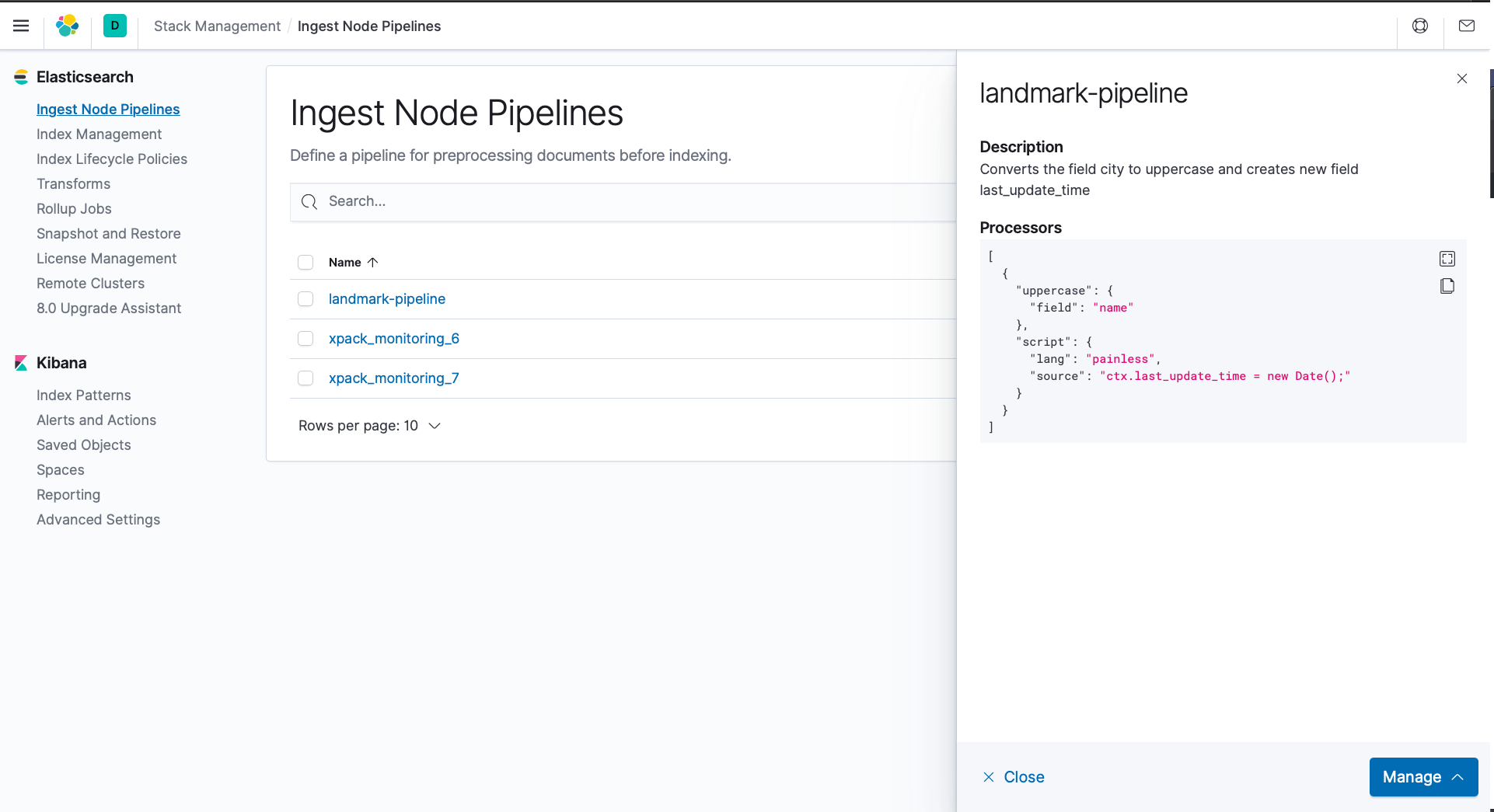
2. Abra un navegador web y navegue hasta Kibana en https://localhost:5601. Debería poder ver la canalización que acaba de crear en Descubrir -> Ingest Node Pipelines.
Configurar el conector Elasticsearch
1. Abra una nueva ventana de terminal y vaya a BASE_DIR/cbes/config
2. Copie el archivo ejemplo-conector.toml y nombrarlo como conector-por-defecto.toml ejecutando el siguiente comando
|
1 |
cp example-connector.toml default-connector.toml |
Connector asume la existencia de un archivo de configuración default-connector.toml y lee este archivo para cualquier configuración. Sin embargo, también se puede especificar la configuración cuando se despliega el conector utilizando una opción de línea de comandos - -config. Para este post usaremos la configuración por defecto.
3. Abra default-connector.toml en el editor de su elección y modifique los siguientes parámetros de configuración.Si desea obtener más información sobre los parámetros de configuración de Elasticsearch Connector, vaya a aquí.
Si desea omitir este paso, puede encontrar un archivo de configuración completo modificado aquí.
Sugerencia: Si es la primera vez que trabaja con el formato de archivo de configuración TOML, consulte el excelente libro de Nate Finch Introducción a TOMLo el especificación oficial.
a ) En virtud del [grupo] establece la clave name en "landmark-example-group".
|
1 2 |
[group] name = 'landmark-example-group' |
b) En virtud del [elasticsearch.docStructure] establezca la clave documentContentAtTopLevel en "true".
|
1 2 |
[elasticsearch.docStructure] documentContentAtTopLevel = true |
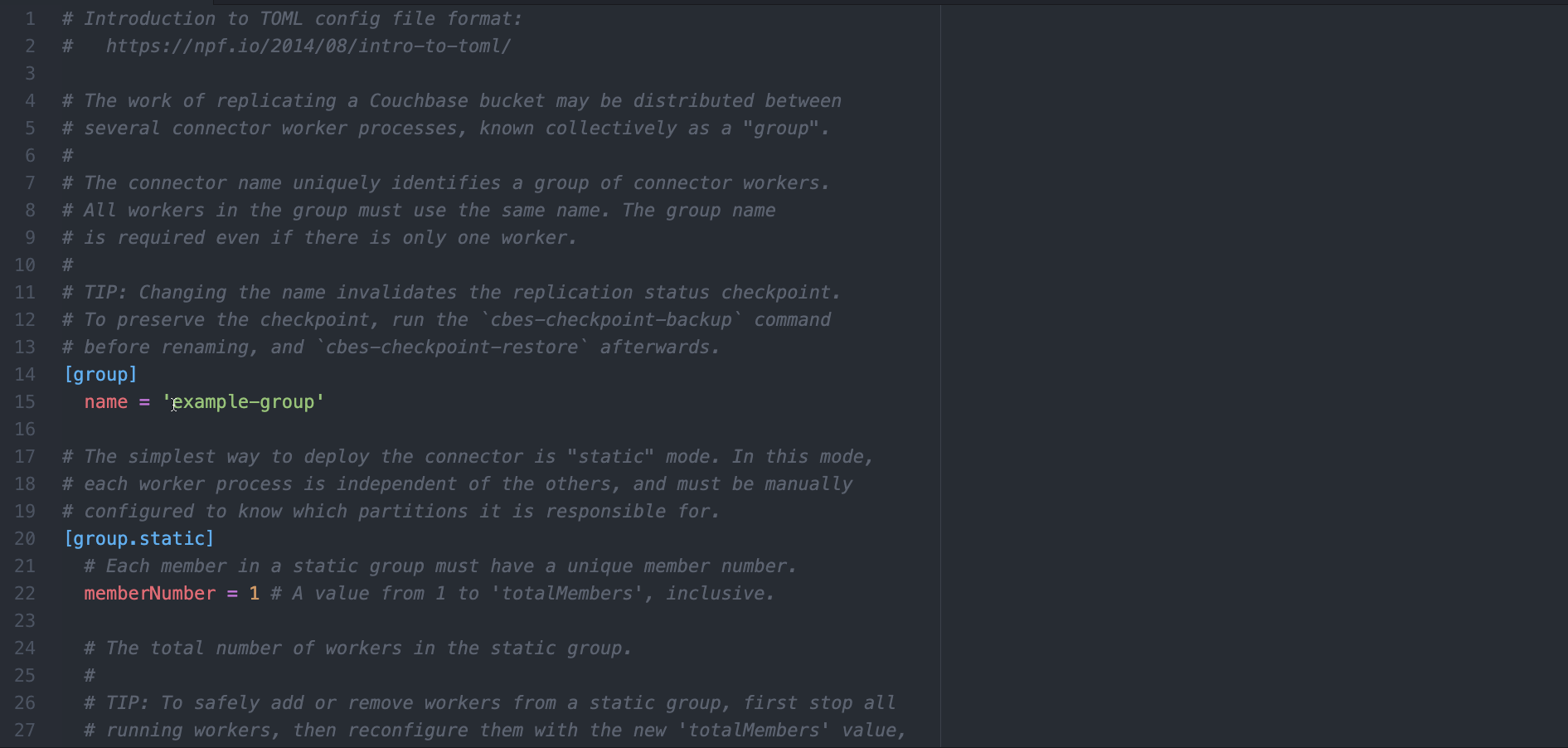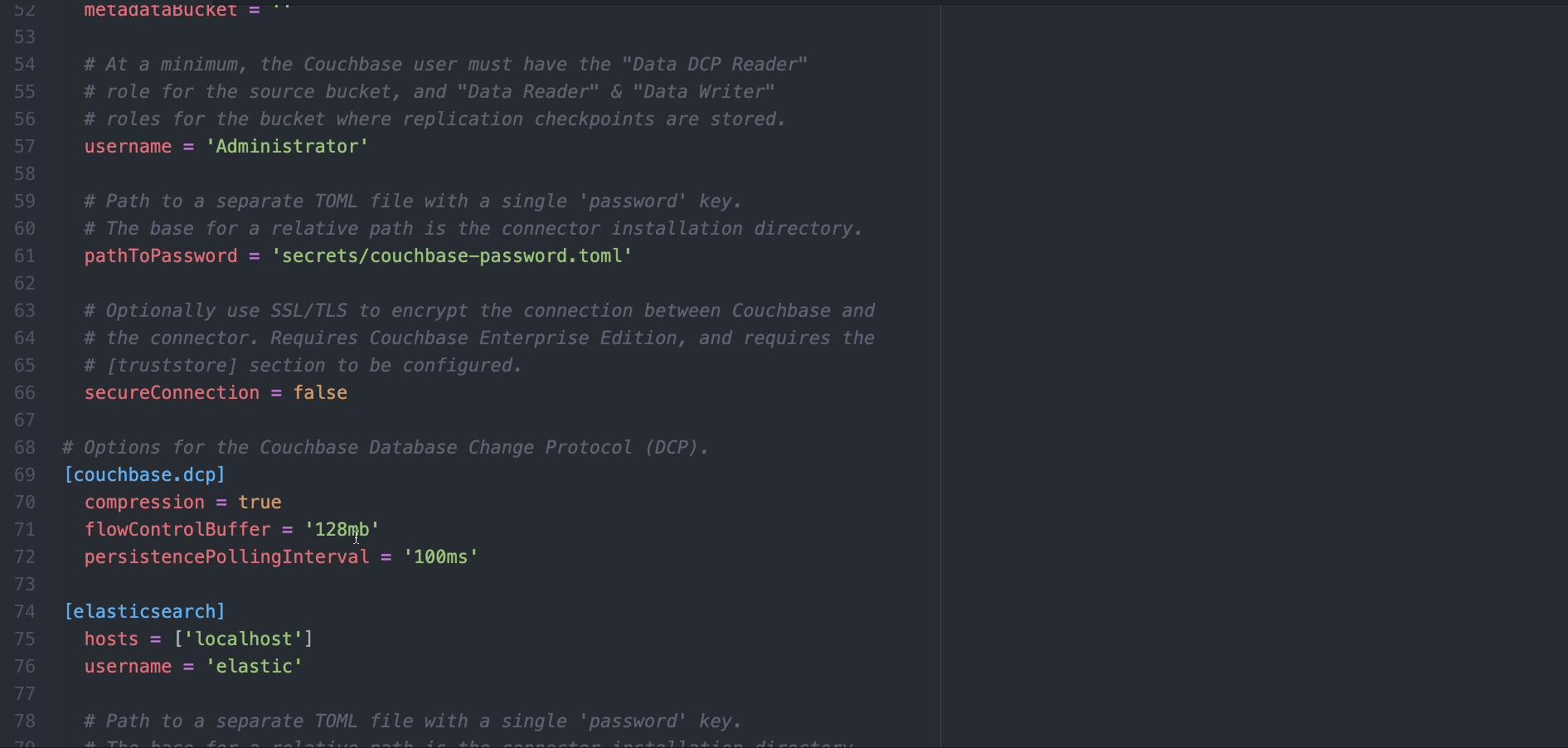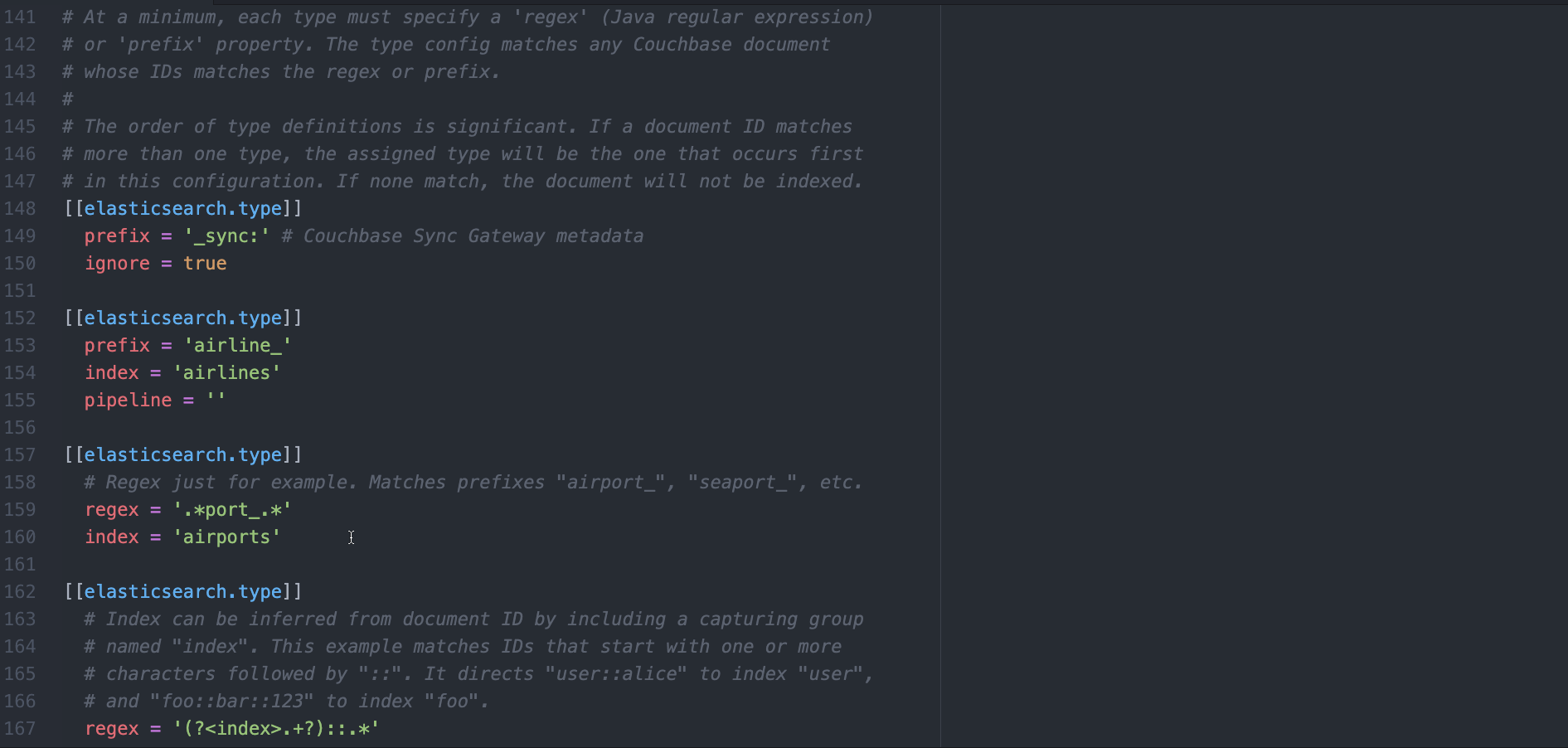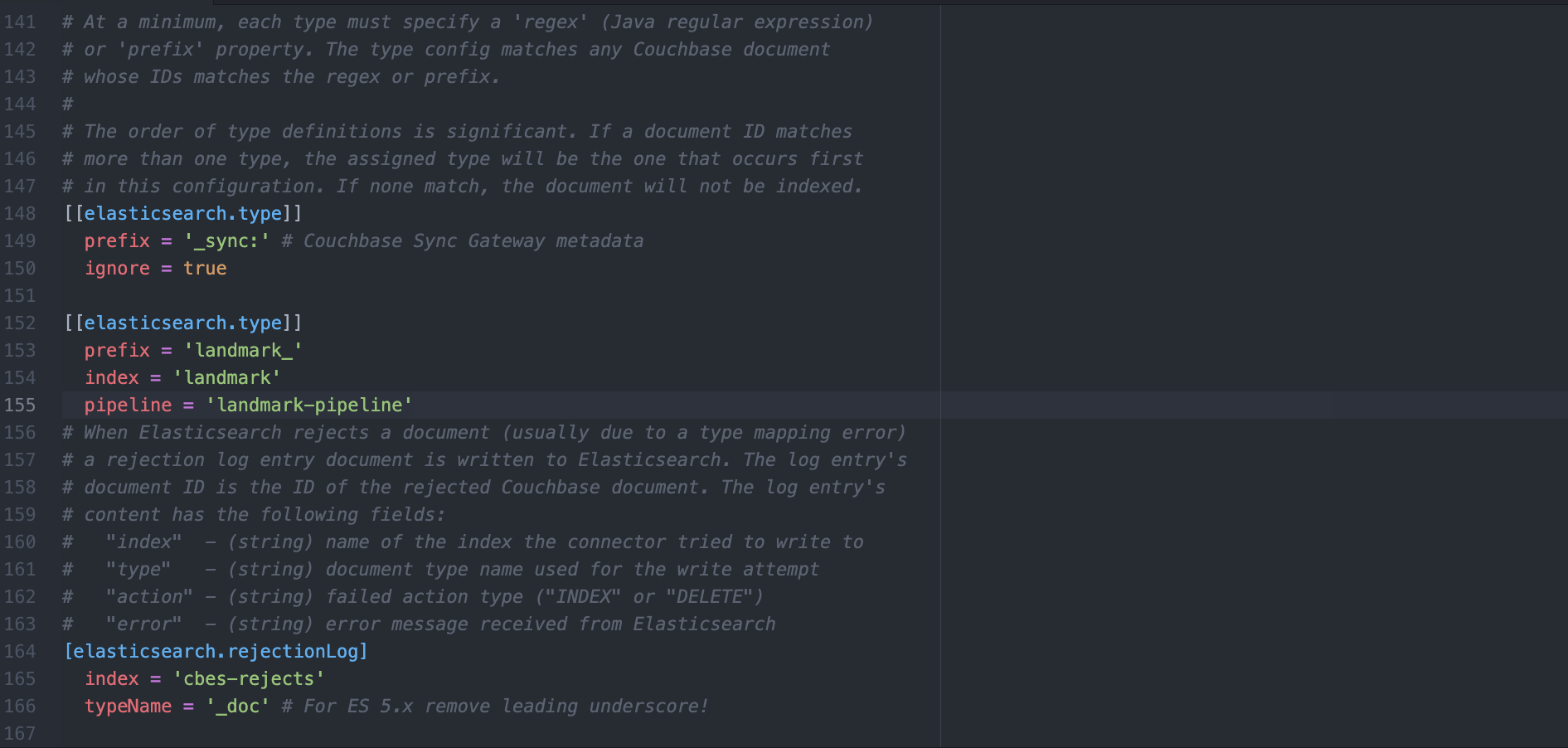
c) Eliminar cualquier [[elasticsearch.type]] y sustitúyalo por lo siguiente.
|
1 2 3 4 5 6 7 8 |
[[elasticsearch.type]] prefix = '_sync:' ignore = true [[elasticsearch.type]] prefix = 'landmark_' index = 'landmark' pipeline = 'landmark-pipeline' |
Despliegue del conector Elasticsearch
Ya está todo listo. Ahora es el momento de ver todo esto en acción.
Los conectores Elasticsearch pueden desplegarse de tres modos diferentes
Solo : Este es el modo más sencillo en el que el conector se ejecuta como un proceso independiente. El modo Solo es preferible en un entorno con poco tráfico o en un entorno de desarrollo.
Distribuido : En este modo, varios conectores se ejecutan como procesos diferentes. En un escenario en el que el tráfico es de moderado a alto, se recomienda este modo. A diferencia del modo solo, en el que un único proceso dedicado realiza todo el trabajo, en un modo distribuido hay más de un proceso y cada conector se configura de forma independiente para compartir la carga de trabajo.
Modo de funcionamiento autónomo : Esto puede concebirse como un modo distribuido gestionado por un servicio coordinado. El servicio coordinado se encarga de la detección de servicios y la gestión de la configuración. A diferencia del modo distribuido, en el que es necesario detener y reiniciar los procesos antes de añadir y eliminar un proceso conector, el servicio coordinado distribuye automáticamente la carga de trabajo cuando se añade o elimina un proceso trabajador, incluso en caso de fallo.
Para este post vamos a desplegar el conector en modo Solo. Antes de iniciar el conector vamos a verificar el recuento de documentos en la fuente en Couchbase.
1. Abra un navegador web y navegue al cluster Couchbase por ejemplo https://127.0.0.1:8091/ui/index.html
Vaya al menú Consulta y ejecute la siguiente consulta
|
1 2 3 |
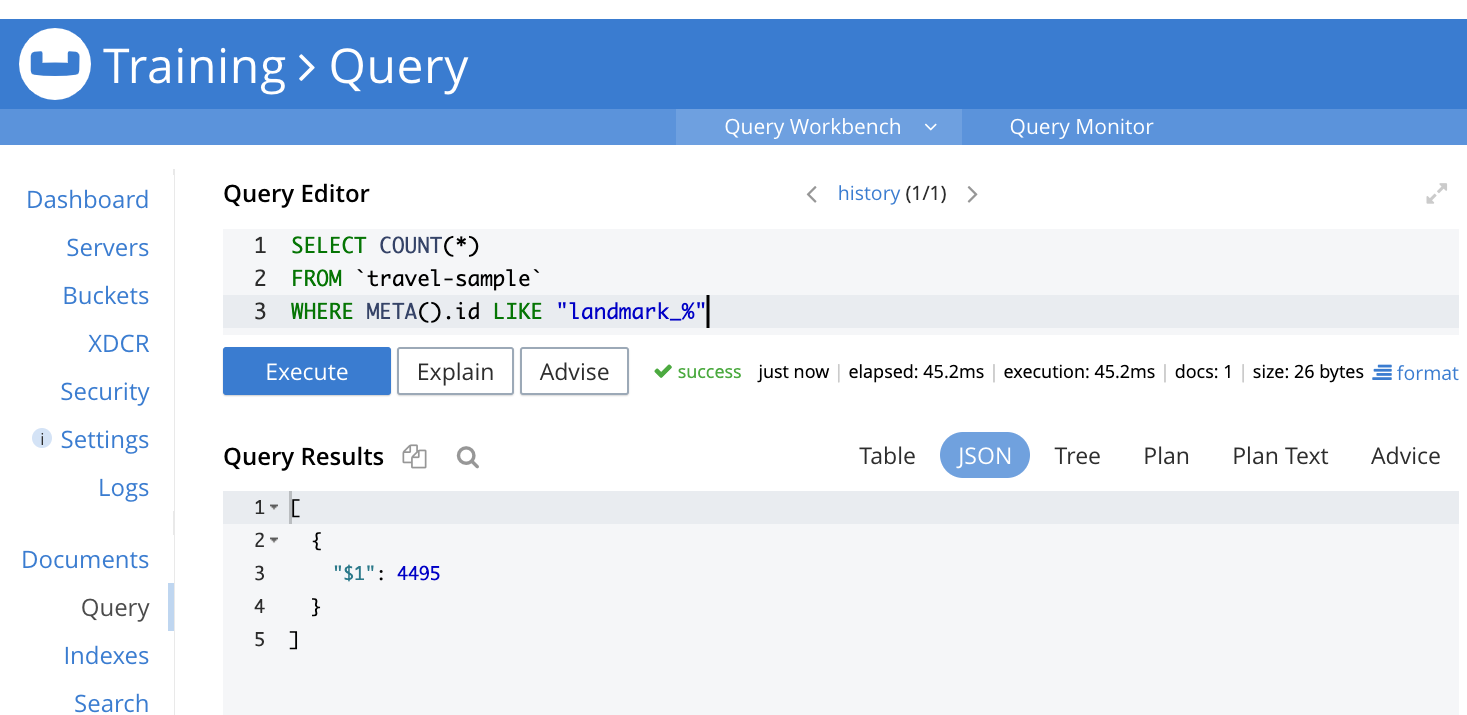
SELECT COUNT(*) FROM `travel-sample` WHERE META().id LIKE ‘landmark_%’ |
Esta consulta debe devolver el recuento de documentos del bucket muestra-viaje en los que la clave del documento empiece por "landmark_". En nuestro caso, el recuento es de 4.495 documentos.
2. Pongamos en marcha nuestro conector.
Abra una nueva ventana de terminal y vaya a BASE_DIR/cbes y tEscriba el siguiente comando
|
1 |
bin/cbes |
El conector debería empezar a copiar documentos (donde la clave del documento empieza por "landmark_") de Couchbase viaje-muestra en Elasticsearch. Mientras esto ocurre, la canalización del nodo Ingest convertirá los valores de name a mayúsculas y también creará un campo last_update_time.
3. Ahora vamos a comprobar si se aplicaron las transformaciones deseadas al replicar los documentos.
Abra un nuevo navegador y navegue hasta Kibana en https://localhost:5601
-
-
-
- Vaya a Descubrir -> Patrones de índice y Definir un patrón de índice. Debería ver la opción landmark.
- A continuación, vaya a Gestión de índices en Descubrir -> Gestión de índices. Debería mostrarle el recuento de documentos deseado (4495).
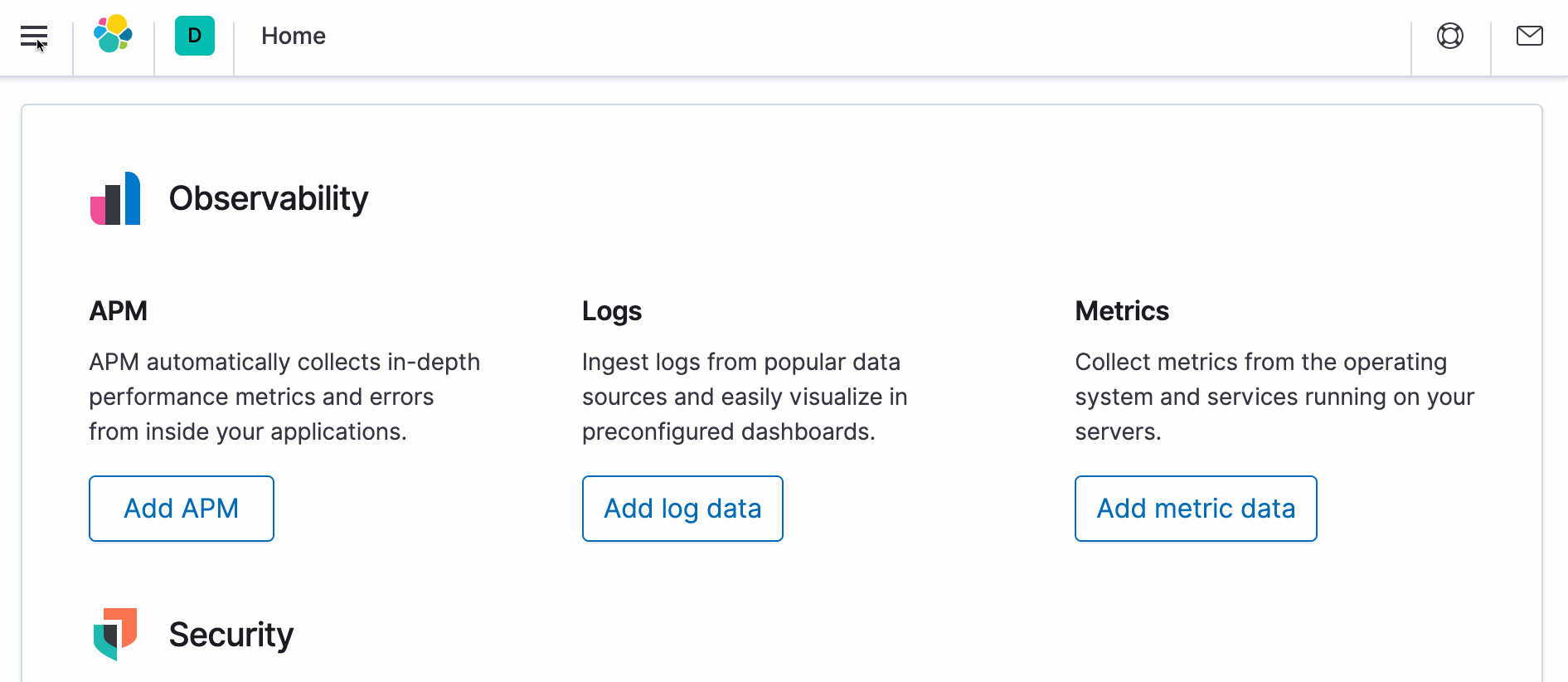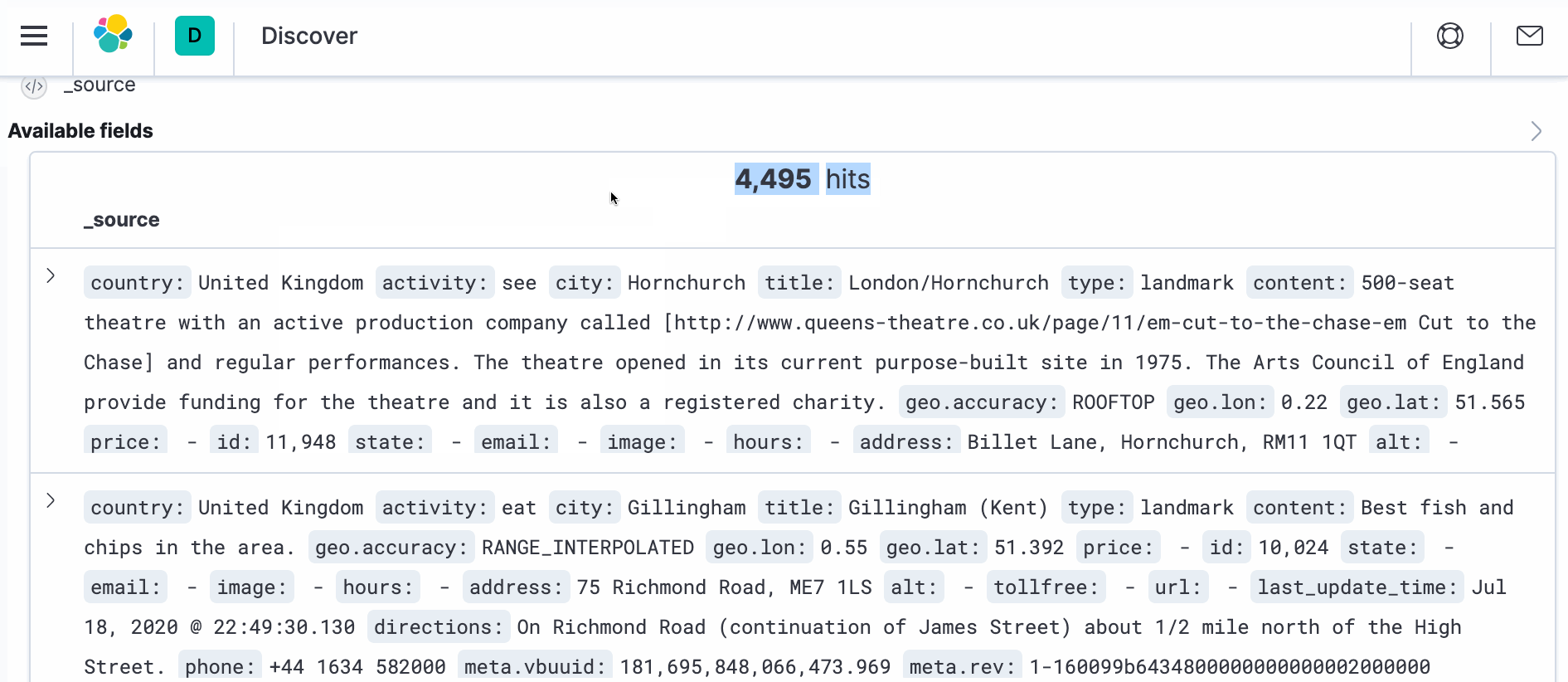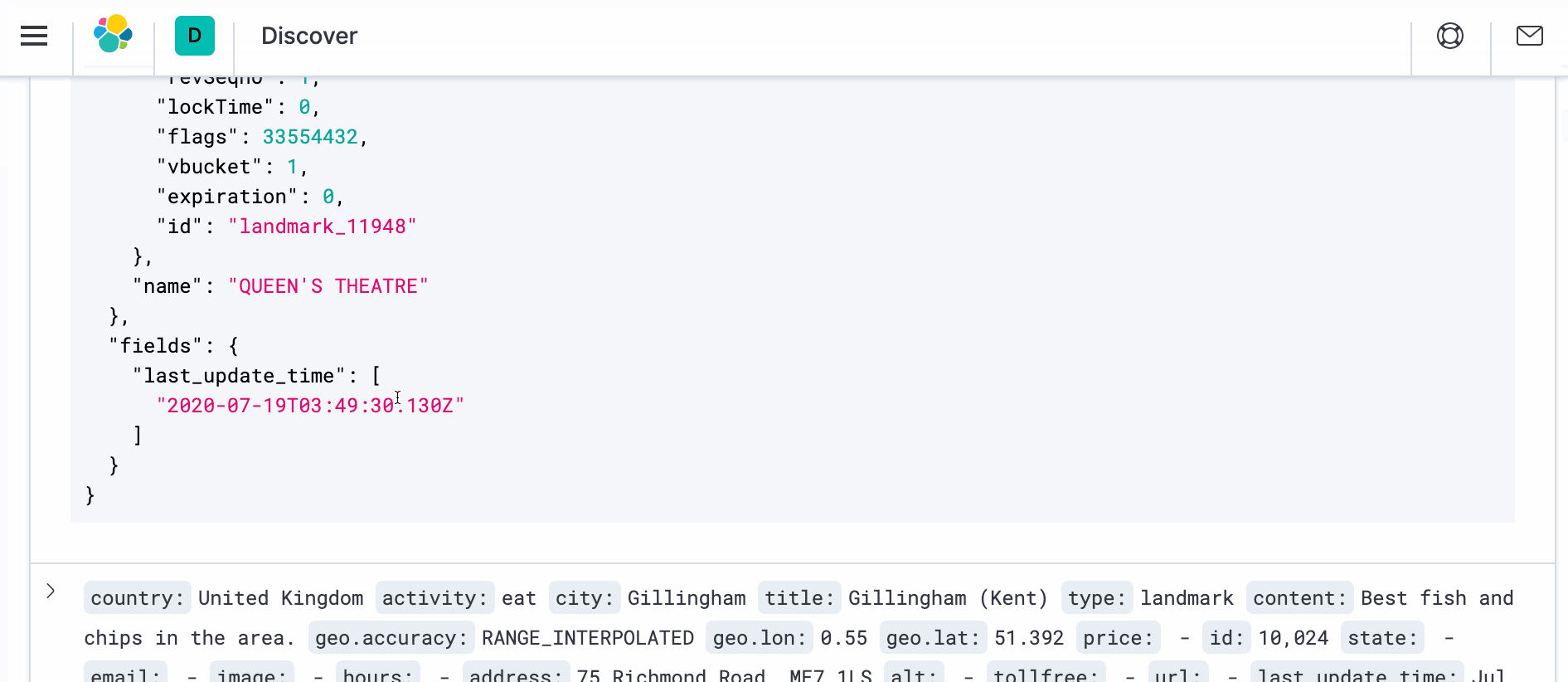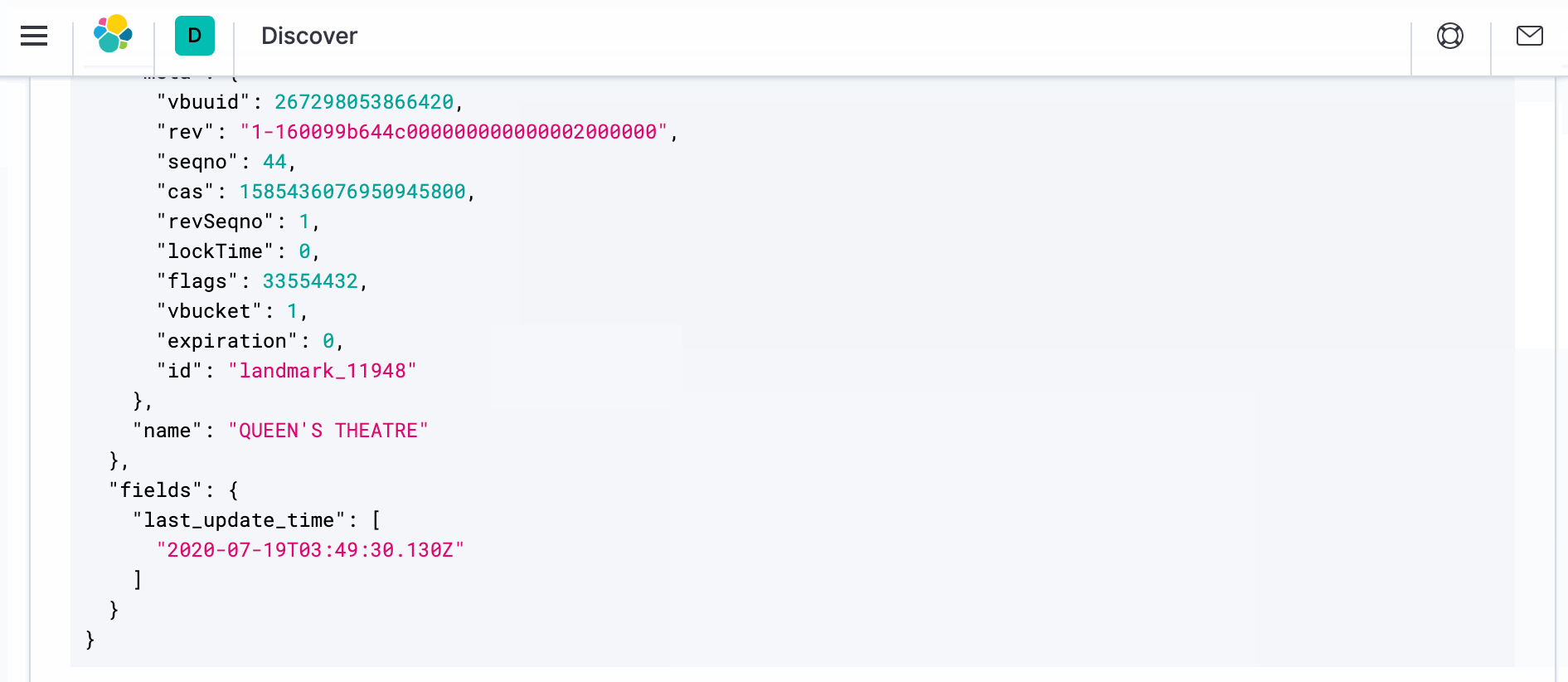
- Para ver el documento real con la transformación, abra una nueva ventana del navegador y navegue hasta Kibana en https://localhost:5601. Vaya a Discover y en la parte derecha, en _source, debería ver ">" símbolo. Haga clic en él y luego en JSON. Debería ver el documento como se indica a continuación
-
-
Repita
Si quieres probar el mismo ejemplo con el mismo conjunto de datos pero con un procesador diferente, o si te has encontrado con un error y quieres empezar de nuevo, es muy sencillo. Todo lo que tienes que hacer es
-
-
-
Detener el proceso que ejecuta Kibana (pulse control + C)
-
Borrar todos los datos de Elasticsearch lanzando un nuevo terminal y escribiendo el siguiente comando
-
-
|
1 |
curl -X DELETE 'https://localhost:9200/_all' |
3. Detener el proceso que ejecuta el conector Elasticsearch (pulse control + C)
4. Clear punto de control del conector lanzando un nuevo terminal y escribiendo el siguiente comando
|
1 |
cbes-checkpoint-clear |
5. Reinicie Kibana, modifique el pipeline , modifique la configuración del conector como desee y reinicie el conector.
Conclusión
Hemos examinado cómo utilizar el conector Couchbase Elasticsearch, para replicar un conjunto de datos de Couchbase a Elasticsearch en modo solitario utilizando un pipeline de nodo Ingest. Ahora estás listo para explorar diferentes procesadores de Pipeline y ajustes de configuración dentro del conector Elasticsearch.
Por fin un "MUCHAS GRACIAS" ¡a mis colegas Matt Ingenthron, David Nault y Jared Casey por ayudarme a llegar a la meta de este blog !
Si te ha gustado este post o tienes alguna pregunta, déjanos tus comentarios.