
Data replication and synchronization may seem redundant at first glance. They both refer to copying data from one persistent repository to another for consistency in a distributed architecture. But for Couchbase, each term has a different meaning and each is used for different purposes.
This post is an overview of Couchbase Cross Datacenter Replication (XDCR), which provides data replication between database clusters, and Couchbase Sync Gateway/Capella App Services, which enables data synchronization for mobile, IoT and edge applications.
Cross Datacenter Replication (XDCR)
XDCR Overview
Couchbase’s Cross Datacenter Replication (XDCR) enables the replication of data across clusters located in different datacenters. Inter-cluster replication is used to ensure even distribution and high availability of data. The protocol used for XDCR is called DCP (data change protocol). DCP is also used for inter-cluster replication and, in both cases, is used for low-latency memory-to-memory replication.
XDCR is designed for global replication: replicating data between multiple regions, multiple datacenters, multiple cloud providers, or any combination. Multiple clusters are needed if you want to replicate data across different regions. Unlike other databases, Couchbase’s multi-datacenter functionality is not provided by stretching a single cluster across multiple datacenters. Due to high network latencies, nodes/servers in different regions cannot be part of the same cluster. Each cluster is independent.
XDCR can be very simple to start with, but many powerful features and options are available. It supports unidirectional and bidirectional operation and active-active replication with automatic conflict resolution. Use filtered replication for replicating subsets of documents.
XDCR Nuts and Bolts
XDCR replicates data from a source bucket to a target bucket (XDCR also supports scope/collection replication, both implicit and explicit). Replication is from memory to memory and asynchronous, and both existing and modified data are replicated.
Multiple data streams are shuffled across all shards (vBuckets) to move data in parallel to the destination cluster for additional latency reduction.
Source and destination clusters can have different numbers of servers (nodes), and XDCR is resilient to topology changes.
XDCR Use cases
Unidirectional (one-way) and bidirectional (two-way) configurations each have their own use cases.
Unidirectional Replication
One-way replication is great for:
- Disaster Recovery – Latest data is always available in the event of a disaster. This enables quick failover and recovery without loss of data or downtime.
- Dev/test copies – Provision copies of production data for testing and development purposes. This reduces the need for manual data copying and reduces the risk of errors or inconsistencies between the environments. XDCR provides near real-time replication, meaning that test data is always up-to-date with production data.
- Reporting/Archival – Replicating data to a dedicated reporting or archival cluster allows for efficient reporting and analysis without impacting the performance of the production environment. XDCR enables real-time or near real-time replication of data, so reporting or archival cluster is always up-to-date with the latest data. This makes it a solution for organizations that need to maintain historical data for compliance or analysis purposes.
Bidirectional Replication
Two-way replication can be used for use cases such as:
- Multiple “hot” active clusters – By replicating data across multiple datacenters, XDCR can help provide efficient load balancing and high data availability. XDCR enables real-time or near-real-time data replication, ensuring all active clusters are always in sync. Suitable for organizations that need to serve large volumes of traffic or have a globally distributed user base.
- Data locality – With XDCR, you can create geographically distributed clusters, allowing data to be stored closer to the users and reducing latency. XDCR can automatically replicate data across multiple datacenters, ensuring that data is always up-to-date at the nearest location.
- Geofencing – XDCR can be configured to replicate certain data only to specific clusters, ensuring that data is only available within designated geographic regions. This can be used by organizations that must comply with data privacy regulations or enforce geofencing restrictions on their data.
XDCR Options
Conflict resolution resolves conflicts that arise when different nodes in the cluster attempt to update the same data simultaneously. Sequence-based conflict resolution resolves conflicts based on the order in which updates are received. In contrast, timestamp-based conflict resolution uses the timestamp of the updates to determine which update is more recent and should be applied. Depending on the specific use case, one type of conflict resolution may be more appropriate, and Couchbase’s XDCR allows for flexibility in choosing the appropriate method.
Filtering allows users to specify which documents should be included or excluded from replication between clusters. This can be based on criteria such as document type, attribute values, or other metadata. XDCR filtering provides greater control over which documents are replicated, reducing the amount of unnecessary network traffic and storage overhead while improving replication efficiency and overall system performance.
Document deletion in one cluster will trigger the deletion of the corresponding document in the other cluster. However, this behavior can be filtered, allowing organizations to maintain historical data for archival or reporting use cases. By filtering out document deletions, organizations can ensure that data remains available in their reporting or archival clusters, even if the corresponding documents have been deleted in the production cluster. This can help organizations comply with data retention policies and ensure that important data is always available for analysis and reporting.
XDCR can also support migration scenarios, such as infrastructure-agnostic migration from on-prem to the cloud.
XDCR Summary
Couchbase’s XDCR feature is one of the primary features that first attracts Couchbase customers and users. It’s a simple and flexible tool for replicating data across different clusters located in different datacenters.
The following table lists the primary use cases for XDCR in a Couchbase Server or Couchbase Capella deployment:
|
XDCR |
| Disaster recovery |
| Dev/Test Copies |
| Reporting, auditing, archival |
| Datacenter locality |
| Geo-fencing |
| Cloud data migration |
See a live demo of Couchbase XDCR in action, below:
Sync Gateway/Capella App Services
Overview of the Couchbase Mobile product stack
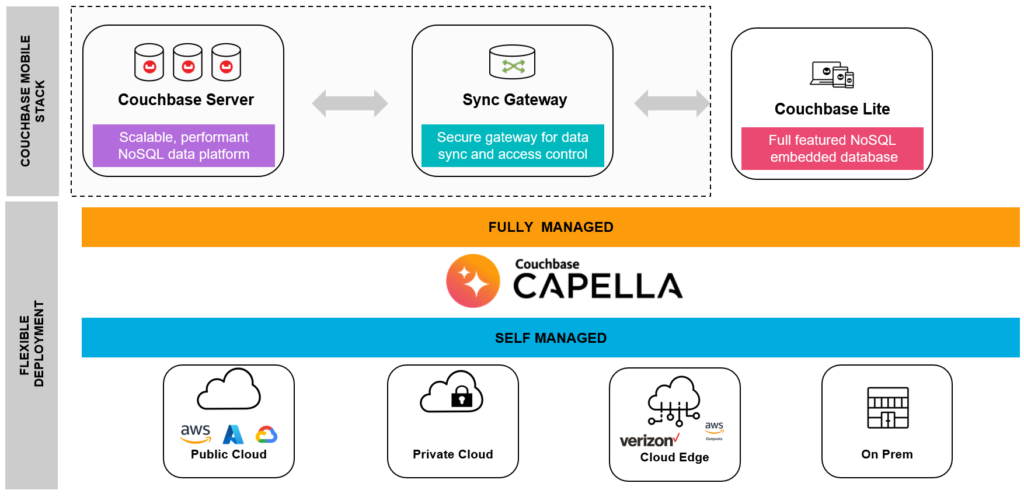
To understand the role of synchronization in a Couchbase-powered application, we start by examining the Couchbase Mobile product stack. Couchbase Mobile is explicitly designed to enable offline first mobile and edge applications. The stack consists of the following:
- Couchbase Server – our flagship modern database server with SQL, analytics, FTS and eventing support.
- Couchbase Lite – the embeddable version of Couchbase for mobile and custom embedded devices.
- Sync Gateway – sits between the cloud and edge databases and is responsible for secure data sync, routing and access control between mobile clients and server tiers.
These capabilities can be deployed in two ways:
- Fully managed with Couchbase Capella, the database-as-a-service hosted by Couchbase.
- Self-managed, where you install and manage the Couchbase Mobile products yourself on public or private clouds, on a cloud edge service or on-prem.
About Sync Gateway
Sync Gateway is built specifically for synchronizing data and providing authorization and authentication for large-scale mobile and IoT applications.
It is designed, first and foremost, to provide cloud-to-edge data sync. This is the ability to synchronize data using a WebSockets protocol between Couchbase in the cloud and devices running Couchbase Lite and between individual Sync Gateway deployments – including between Sync Gateway and App Services.
Sync Gateway also provides:
- REST APIs that allow web clients to access sync data.
- Administrative APIs for remotely working with deployment configurations.
- Monitoring performance and event statistics.
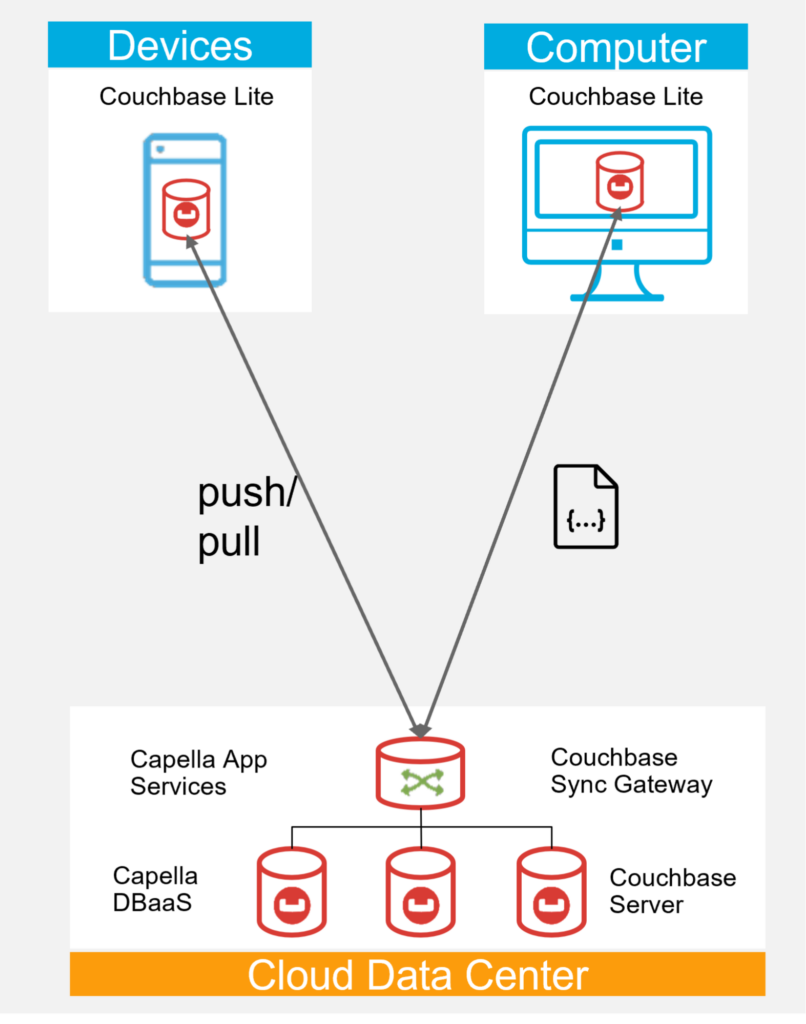
Cloud to edge data sync
Sync with Couchbase Lite
Syncing between Couchbase Server/Capella and Couchbase Lite is bi-directional and initiated by the edge device in a push or pull manner. Replication can be one-time, continuous, or performed on demand, supporting many conditions and use cases.
The sync payload is JSON data or binary attachments. In the case of binary/blob attachments, payloads under 20MB are replicated. If the blob is over 20MB, the document itself is replicated but not the blob.
Couchbase Lite allows applications to leverage fine-grained filters on the replicator to determine what documents are synced and where to route them. This controls when and what documents get synced.
Replications are sent using WebSockets to enable full-duplex messaging between remote hosts over a single TCP connection. Hence, it is a faster protocol, reducing bandwidth use and socket resources compared to REST-based protocols over HTTP.
Sync Gateway/App Services is responsible for maintaining appropriate consistency for these replications.
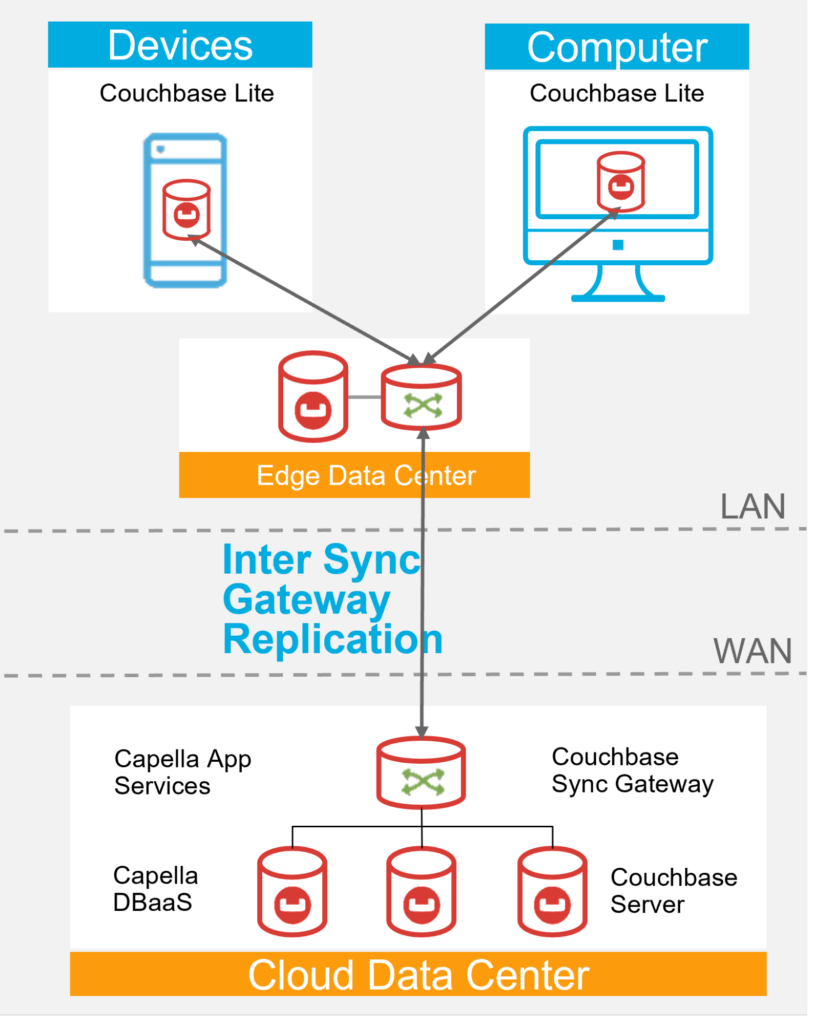
Inter-Sync Gateway Replication
Along with synchronizing data directly from Couchbase Lite to Couchbase Server or Capella, Sync Gateway can replicate to other Sync Gateway instances and/or Capella App Services using a feature called Inter-Sync Gateway Replication.
Like Couchbase Lite sync, Inter-Sync Gateway Replications are bidirectional and based on WebSockets.
Inter-Sync Gateway Replications automatically attempt to restart in case of interruption or whenever a node restarts and can be configured to decrease restart attempts in cases of an extended network interruption.
Inter-Sync Gateway Replication provides built-in high availability and uses node distribution to ensure all running replications are uniformly distributed across the available nodes, regardless of the originating node.
The ability to sync data between Sync Gateway deployments allows you to architect multi-tiered, hierarchical, edge topologies that support extremely high availability, low latency, data privacy and efficient bandwidth usage.
- For more information about using Inter-Sync Gateway Replication with App Services, check out this blog.
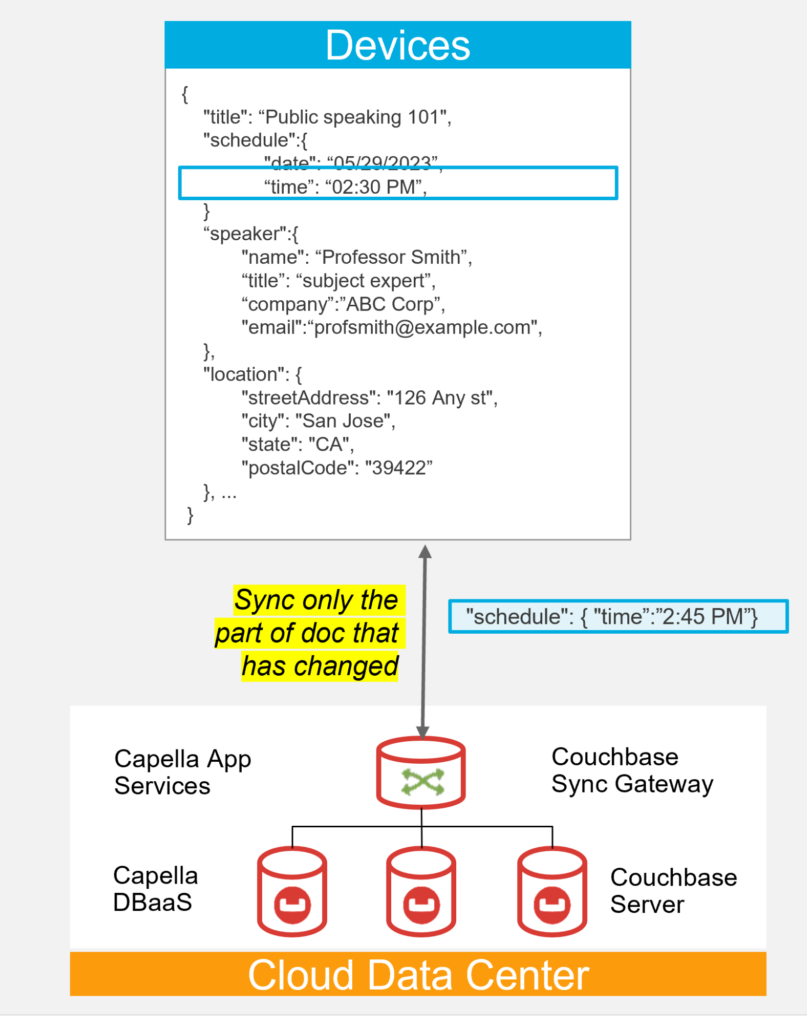
Delta Sync
Sync Gateway / App Services can track and replicate the parts of a document that have changed without sending the entire document. This allows less data to be sent over bandwidth constrained networks, making apps faster and more efficient.
Conflict Resolution
For mobile apps that utilize decentralized data writes, the same data can be simultaneously modified on multiple devices, creating a conflict. For resolving conflicts, you can apply one of the built-in conflict resolver policies, which can be easily included in your own replications. The goal of automatic conflict resolution is to return a winning revision based on the consistent application of the configured conflict resolver policy.
Sync Gateway/App Services conflict resolution uses revision trees and a default resolution rule of most active branch wins. This way conflicts are resolved logically based on activity, vs. system clock-based conflict resolution that takes a most recent change wins approach, which are problematic due to the issues around clock differences across devices.
- Read more about working with Couchbase Lite conflict resolution and how to use Inter-Sync Gateway Replication conflict resolution.
Access Control
Model
Channels are a key to understanding how Sync Gateway shares and controls access to documents. Channels are basically intermediaries between documents and users.
As illustrated in the following diagram, every document in the database belongs to a set
of channels, and every user is allowed to access a set of channels.
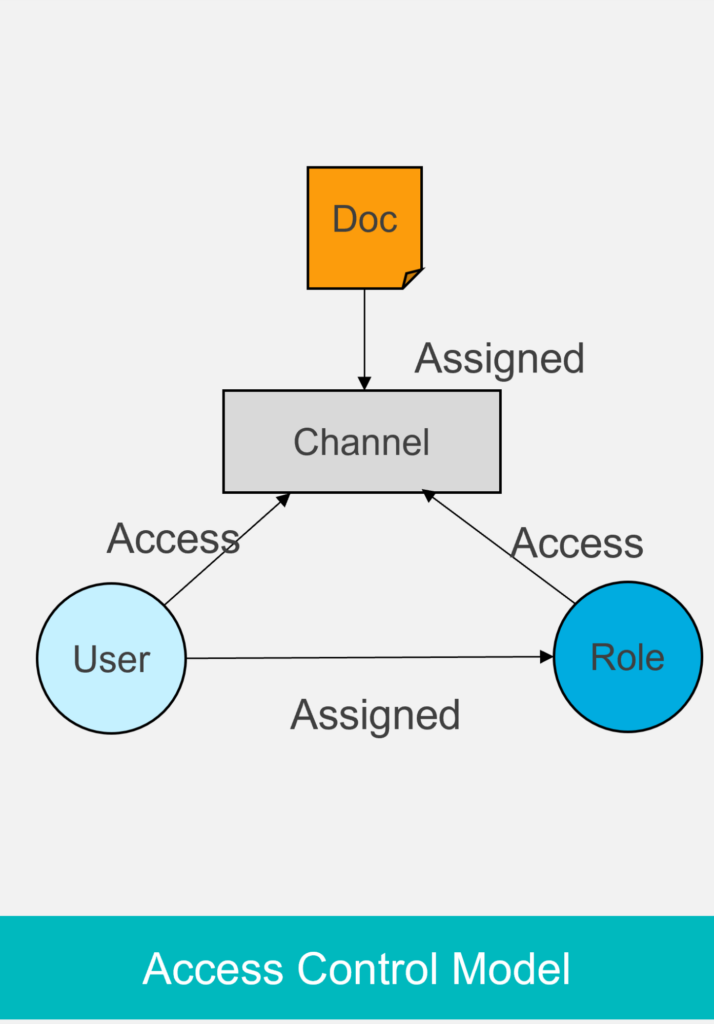
Once a user creates a document, it is assigned to one or more channels. Users can only access documents assigned to channels that they have been granted access for, authorization is handled by Sync Gateway.
For example, documents added to a public channel are visible to any user. A channel can also be private and restrict access to a single user or provide shared access between multiple users,
Roles are named collections of channels. A user is assigned to a role and thus inherits the channel access assigned to the role. This control can be changed at any time and even revoked to prevent improper access.
- Learn more about Sync Gateway Access Control.
Sync Function
The sync function is a JavaScript function that is called every time a new revision or update is made to a document.
The sync function can be used to:
- Validate documents
- Authorize changes
- Grant user access to channels
- Assign documents to channels
The sync function can provide access control at the document level for reads, and at the field level for writes.
- Learn more about the Sync Gateway Sync Function.
Sync Gateway/Capella App Services Summary
The data sync capabilities of Couchbase Sync Gateway and Capella App Services are ideally suited for mobile and IoT applications – where data changes rapidly and updates need to be instantly reflected across a distributed ecosystem of users and devices.
The following table provides an at-a-glance list of applicable use cases, if your application requires any of these capabilities, then Sync Gateway/App Services is the solution:
|
Sync Gateway / App Services |
| Cloud-to-edge data sync |
| Built for multi-tier edge topologies |
| Authentication, authorization |
| Precise data routing |
| Customizable conflict resolution |
| Channel access revocation |
Check out this live demo of Couchbase Sync Gateway in an airline baggage scenario:
Conclusion
Couchbase is unmatched in its ability to replicate and synchronize data across a globally distributed application ecosystem to provide consistency, integrity and disaster recovery for critical applications, from the cloud to the edge.
We hope this post clarifies the role and uses of Couchbase XDCR and Couchbase Sync Gateway/Capella App Services so know which one to leverage for your specific requirements.
Leave a comment
You must be logged in to post a comment.