Couchbase 6.5 release includes an extensive list of Enterprise Grade Database Query capability that allows customers to expand the adoption of NoSQL database into traditional database applications. The release has added transactional capability, Analytical Window functions, user defined JS functions, as well as Index Advisor to improve query performance. As performance is one of the most important aspects of the Couchbase platform, the new release also includes a set of new enhancements to further strengthen the Couchbase Index Service and improve operational efficiency. These features are grouped together under the general heading of Reliability, Manageability, and Serviceability – Index Service RMS.
1. ALTER INDEX to change index replica count
In 6.5.0, we have added the much asked-for support for changing the number of replicas for an index using the ALTER INDEX command. The replica count can be changed using ALTER command as in below example –
|
1 |
ALTER INDEX `travel-sample`.airlines_idx WITH {"action":"replica_count","num_replica": 3}' |
action for ALTER INDEX is replica_count and the parameter num_replica specifies the new number of replicas for the index. If num_replica value in the ALTER statement is greater than the current count of replicas, additional replicas are created; if it is lesser than current replica count, replicas are removed.
2. ALTER INDEX to drop an index replica
ALTER INDEX command has further been enhanced to drop an individual index replica using syntax as below:
|
1 |
ALTER INDEX `travel-sample`.airlines_idx WITH {"action":"drop_replica","replicaId": 2}' |
action is drop_index and replicaId is the ID of the replica which is a number identifying a replica. The replicaId of a replica and host it resides in can be obtained from REST API getIndexStatus.
What are the benefits: Better manageability of index replicas – easier way to increase/decrease replica count or drop a specific index replica. Find more information at:
https://docs.couchbase.com/server/6.5/n1ql/n1ql-language-reference/alterindex.html
3. Improve DCP Rollback handling
DCP rollback happens in the index service when one of the data node gets failed over, and a data replica gets promoted to active. Not every failover leads to rollback. This situation only happens when the index service has more data/recent vbuuid than the data replica before failover. If the data replica becomes active after a failover, the index service will receive a rollback. Please refer to the DCP documentation for more details. In worst case scenario, DCP could ask index service to rollback to 0.
With this enhancement, DCP rollback handling for the index service has been made more robust.
When the index service receives a DCP rollback to 0, it will try to revert to its most current index snapshots, instead of rebuilding the entire index.
What are the benefits:
- Index service will no longer need to rebuild its indexes from scratch when the data node is auto failover.
- Index service will continue servicing the query clients without any interruption using its most current snapshot.
- Since index disk snapshots are taken once every 10mins, it could therefore be serving up stale data during the period that index is catching up with data service. If scan_consistency is set to request_plus, then scans will wait until a consistent snapshot is created and stale results will not be returned.
4. Optimize in-memory snapshotting
Couchbase server is designed to be eventually consistent. However application can alter this behavior by requesting for index service to include all updated documents in its indexes before processing the query, via the request_plus query consistency setting. The response time for the query is expected to have some delay as the service needs to ensure that the indexes are updated before processing the query. The frequency of generating in-memory snapshots for indexes has been increased to every 10ms to speed-up request_plus queries.
What are the benefits:
- In Couchbase 6.5, we have optimized this process by speeding up the index in-memory snapshotting. Application queries, using this setting (request_plus) , can now see the response time reduced by over 45%.
5. Improvements to projector memory usage
Projector is a process that resides in the data node that processes incoming mutations on behalf of the index service. Projector ensures that only mutations that involve the document fields, which are part of any indexes, are sent over to the Index Service. Projector memory usage can be negatively impacted with high mutation rates, large document size, slower downstream. This enhancement involves reconfiguring the various settings in the projector internals to ensure the process memory usage is kept at an optimal level.
What are the benefits:
- Performance test cases show that the peak-projector RSS(Memory Use) has decreased from 1.5GB to 176MB (for a specific workload) without affecting the index build time.
6. Improve projector response time to indexer
Under heavy load, the projector process can become slow in responding to the indexing service, which was due to the slow communication control messages on the projector channel. An optimization has been introduced to separate out Control and Data channels in projector and also to prioritize control messages over data.
What are the benefits:
- Under memory pressure, projector continues to respond to control messages from indexer and we can see a reduction in rebalance failures.
7. Build all unbuilt indexes at once
The N1QL command to BUILD index currently takes a single or a list of index names. This command has been enhanced to take the result of a query, thus allowing Administrators to submit a single command to build all unbuilt indexes. This is particularly useful after a database restore, and the Administrator needs to rebuild all indexes that are in deferred state.
|
1 2 3 4 5 6 |
BUILD INDEX ON `travel-sample` ((SELECT RAW name FROM system:indexes WHERE keyspace_id = 'travel-sample' AND state = 'deferred' )); |
What are the benefits:
- Database administrator can issue a single BUILD command to rebuild all unbuilt (deferred) indexes.
8. Allow scans during indexer warm up
When indexer restarts, the indexes are recovered from persisted storage. If the number of indexes per node is high, this can take a long time (up to a few minutes). Before this improvement, scans were disabled during indexer warm up. We have improved this behavior to allow scans for those indexes that are warmed up and have a consistent snapshot available. If a consistent snapshot is not available during warm up (this happens when Data service has moved ahead), then an error is returned so that a replica index on another indexer node can be retried.
What are the benefits:
- This improvement allows better application continuity and service availability in the case of indexer process restarts.
9. Apply settings change dynamically without indexer restarts
Before this improvement, changing settings that allow/disallow large keys, control the size of indexed keys and corresponding runtime buffers needed to process index keys required restart of indexer process, causing cluster-wide indexers restart leading to unavailability of service. We have improved the behavior to ensure these sizes apply dynamically and all buffers resize dynamically without affecting processing of mutations.
What are the benefits: Following settings can now be dynamically changed without causing indexer process restart: max_seckey_size, max_array_seckey_size and allow_large_keys.
There is no configuration change needed to enable this improvement. This allows application continuity and service availability when above settings are modified.
10. Find unused indexes
In large applications using database, there can be many indexes created but it is possible that not all are in use in recent past or not used at all. To help make it easier to identify which indexes are not used so that they can be dropped, we now provide a stat for each index that has timestamp of last known query time of that index as Unix timestamp (which is in nanoseconds). This stat does not reset upon indexer restart as it gets persisted locally on the indexer node. This stat is a heuristic to get an estimated last query time and cannot be exact as the persistence interval of the stat is 15 minutes. It can be fetched using stats REST API of the indexer, and it is also available in the index definition UI.
|
1 |
curl -u <username>:<password> <hostname>:9102/api/v1/stats | json_pp | grep last_known_scan_time "travel-sample:airlines_idx:last_known_scan_time" : 1579179249769780000, |
You can also use N1QL to query for the unused indexes
|
1 2 3 4 5 |
SELECT ARRAY { "index_name":a.name, "last_scan_time":millis_to_str(a.val.last_known_scan_time/1000000) } FOR a IN OBJECT_PAIRS(results) END FROM curl("https://<hostname>:9102/api/v1/stats", {"user":"<username>:<password>"}) results |
11. Stats improvements
New stats have been added to Periodic stats logging in indexer and as well as in projector. These stats are:
| stats | Description | Available on supported REST Endpoint |
| num_scan_timeouts | Number of scan requests that timed out either waiting for a snapshot or during scan in progress. | Yes |
| num_scan_errors | Number of scan requests that failed due to any error other than timeout. | Yes |
| avg_scan_latency | Running average of scan latencies observed for a given index | No |
| last_known_scan_time | An int64 Unix timestamp representing the last known time of an index. | Yes |
| key_size_distribution | A distribution of key sizes in various size buckets | No |
| arrkey_size_distribution | key_size_distribution – A distribution of key sizes in various size buckets | No |
| num_items_flushed | Number of index keys written to the index storage. | Yes |
| initial_build_progress | Progress of initial build of an index in percentage | Yes |
| avg_drain_rate | A running average of number of items flushed to index storage | Yes |
| num_pending_requests | Number of scan requests that are currently outstanding or ongoing. | Yes |
| memory_total_storage | memory_total_storage – Size of the total jemalloc usage by the index storage. | Yes |
| projector_latency | This stat measures a running average latency of mutation processing at projector i.e. the time mutation arrives from data node to the time it is pushed to indexer node by the projector. It is maintained per data node at the indexer. This helps in identifying which projector (in a data node) is taking more time to process mutations. | No |
12. Index UI improvements
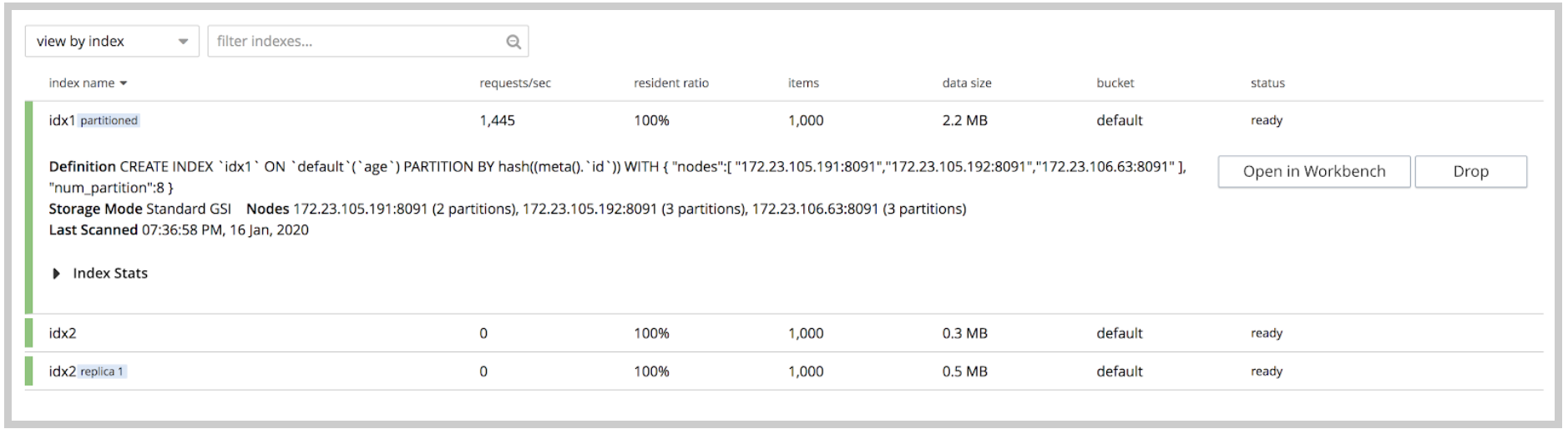
Index UI in v6.5 has been improved to include important summary information about the index such as requests/sec, resident ratio, items, data size, status. Expanding upon an individual index shows the index definition and, in case of a partitioned index, their nodes and partitions information.
Index Summary
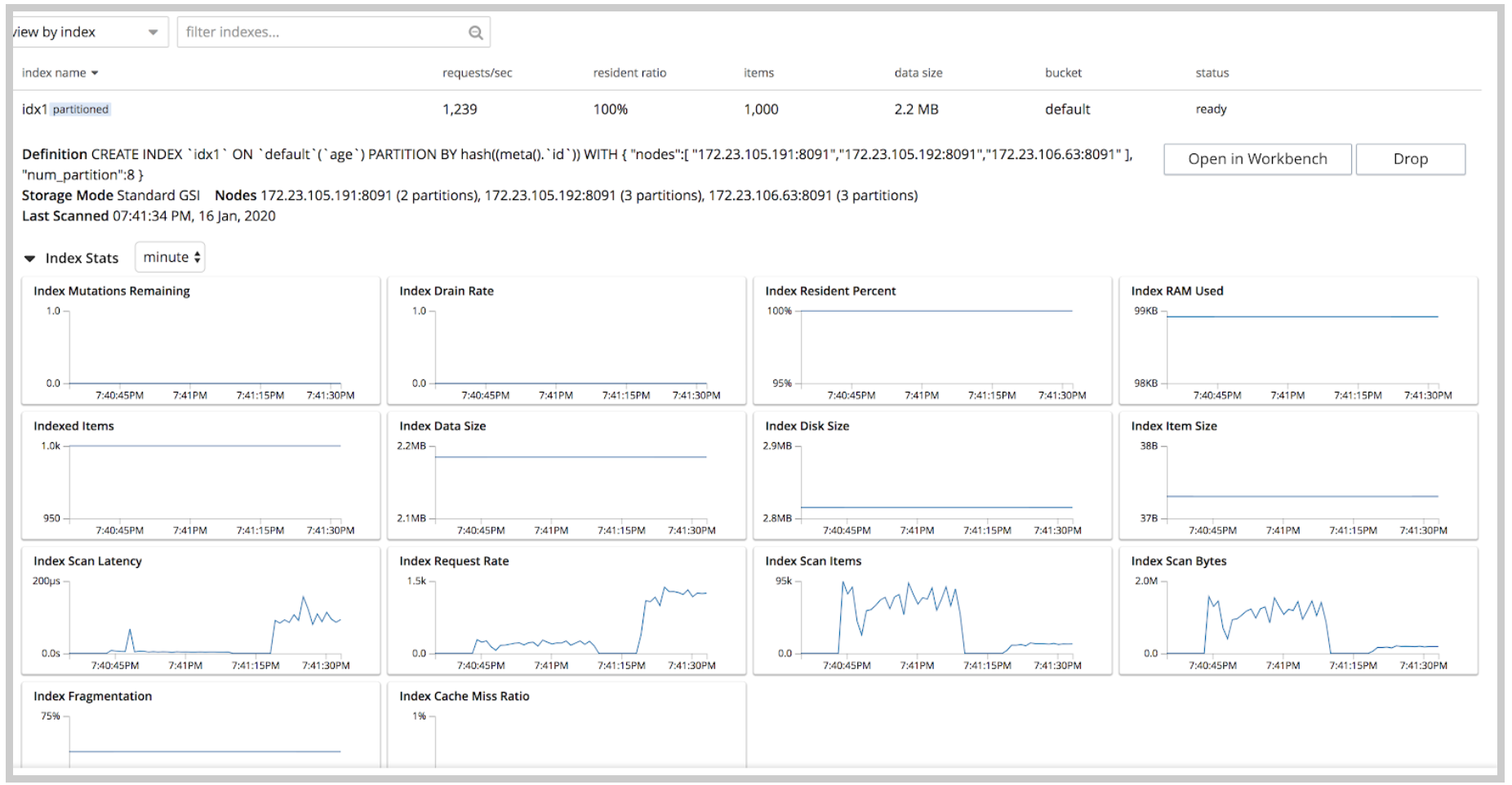
Index Stats
A significant new addition to Index UI is the Index Stats for each index which displays a graphical view of key stats like Resident Percent, Data Size, Disk Size, Index Fragmentation, Drain Rate among others. A complete summary stats of the entire index service service (across all indexes) is displayed at the bottom of the page capturing information like Index Service RAM Quota, RAM Used/Remaining, Index Service RAM Percent, Total Scan Rate and Indexes Fragmentation. These improvements to Index UI help in easier monitoring of the indexes with the most important stats readily available.
Index service summary at the bottom of the page

Summary
We are very excited about the new Index service (GSI) RMS enhancements for Couchbase v6.5, as these features will address many requests that our customers have asked for. As usual we are looking forwards to getting feedback for these enhancements,
Resources
- Download: Download Couchbase Server 6.5
- Documentation: Couchbase Server 6.5 What’s New
- All 6.5 Blogs
We would love to hear from you on how you liked the 6.5 features and how it’ll benefit your business going forward. Please share your feedback via the comments or in the forum.
Co-author: Prathibha Bisarahalli | Senior Software Engineer