
Almost everything we do, both online and offline, is powered by the cloud. Whether it’s buying groceries at your local supermarket, streaming your favorite TV show or opening an email – you are using the cloud. The computation power, storage capabilities and unparalleled convenience of cloud ecosystems is spurring incredible adoption. Today, 50% of the world’s corporate data is stored in the cloud with $178 billion dollars in revenue being generated this year alone.
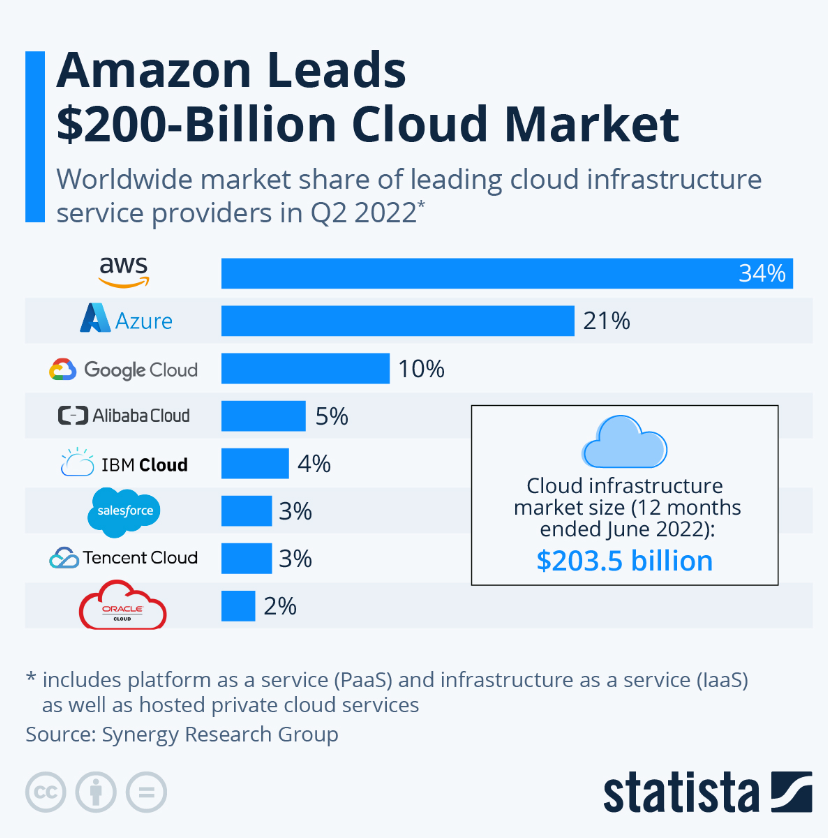
As cloud computing becomes increasingly ubiquitous, it is equally becoming increasingly competitive, with the main three providers — Amazon Web Services (AWS), Google Cloud Platform (GCP) and Microsoft Azure – fighting for a bigger slice of the pie. AWS holds the lion’s share of the market at 34%, but its closest rivals are growing quickly. This has required strategic offering enhancements to capture more of the market.
In its infancy, the field existed mainly as a form of Infrastructure as a Service (IaaS), enabling users to easily access ostensibly limitless hardware resources without the hassle of maintaining complex and expensive technology. Since then, the major cloud providers have become as much software solution providers as hardware providers, releasing more and more closed application solutions that run within their cloud, positioning their Software as a Service (SaaS) offerings over their IaaS offerings. The different SaaS solutions on offer answer an overly broad selection of technical requirements, to which the trinity each have their own custom implementations that compete with one another.
How we got here
Historically, while information has been quite opaque, the underlying hardware between the major platforms has remained largely homogenous, simply due to what Intel, AMD and Nvidia have on offer. This left cost-based differentiation as the main revenue strategy, driving innovations like spot and preemptible instances. But, the providers needed new ways to attract growth, and bundling in and releasing custom platform-specific software provided an exciting route to compete.
Customers now have to pick between seemingly similar software solutions that are beholden to a specific cloud provider, or alternatively a third-party non-locked-down software solution.
A selection of NoSQL database offerings
The traditional risks of lock in
On the surface, it makes sense for an existing GCP customer to choose Bigtable as the infrastructure and billing are already there. With Bigtable, they get a familiar consolidated experience. Yet, this obscures the hidden costs of cloud lock-in. Many of these drawbacks are familiar to most:
-
- Performance: It is easy to overlook performance and feature excellence in the pursuit of simplicity.
- Price: Once you are dependent on a single cloud vendor, you no longer can leverage competing infrastructure for cost savings.
- Quality: The cloud providers are big and have tens of SaaS offerings. Generally, they cannot dedicate as many development resources to any single offering when compared to a dedicated cloud-agnostic product house.
- Single point of failure: The over-reliance on a single vendor exposes you to incredible risk if something were to affect the availability of the cloud’s infrastructure and software.
However, industry trends are leading us back to differentiated hardware, presenting a new unmatched performance risk when working with a single provider: Next-generation silicon.
Where we are going
With the release of Apple’s M1 chips, a new paradigm of silicon was unveiled. Using ARM architecture, Apple designed and built completely custom silicon that excels exactly where its customers needed it to:
-
- Incredible performance per watt = Unparalleled battery life
- Video encoder/decoder engine = Creatives can spend more time creating
- Purpose-built ML engine = Accelerated artificial intelligence (AI) experiences
This functionality was specific to Apple silicon and the M Series is only available in Apple’s products. We have entered the era of specialized compute engines designed to excel at specific workloads.
The trend continued with Google’s consumer phones that now are powered by their new Tensor line of silicon enabling incredible performance for machine learning (ML) workloads. Also, this year, Intel, Nvidia and AMD have released GPUs with specialized AV1 encoding engines all custom designed to excel at one specific workload. These hardware efficiencies can be accessed only on these products.
The pattern is accelerating quickly in the cloud ecosystem as well. AWS is already on its second-generation machine learning-specialized virtual machines, known as Trainium. And at Google Cloud Next 2022, Google revealed its new virtual machine family: C3, dubbed as the first VM in the public cloud to run on the 4th Gen Intel Xeon Scalable processor and the custom infrastructure processing unit (IPU) named E2000 that Google co-designed with Intel. This chip is only available on GCP and is the latest release in what they call workload-optimized infrastructure.
GCP has also led the charge in introducing specialized hardware that goes beyond compute engines, with the introduction of Hyperdisk, offering incredible storage performance. You do not need to be a prophet to see where this trend is going. The cloud providers will certainly continue rapid development of specialized hardware, targeting a range of workload requirements.
The end result is clear: To maximize the performance of your own applications, you will need to leverage the right resource for the right job. This new paradigm could allow enormous performance boosts to existing applications, but only if you can access the right instance set. If you are already committed to AWS DynamoDB, you cannot leverage GCPs new Hyperdisk storage technology. Likewise, if you are fully locked in to GCP, you cannot use AWS’s Trainium instances. Over the next few years, those locked into a specific cloud ecosystem will miss out on vital performance gains, ultimately costing their business revenue and opportunity by undermining their products.
How to react to the new paradigm
Cloud lock-in has never been more dangerous. To avoid exposing your business to undue risk, consider implementing the following two-pronged strategy:
Kubernetes
Kubernetes (K8s) is the leading open source container orchestration platform. A favorite of DevOps teams around the industry, it allows you to bring your own compute and easily scale up/down nodes and pods (one or more containers) to accommodate application load. Kubernetes is 100% cloud agnostic, meaning you can use any compute you want from any of the cloud providers, giving you access to the most suitable compute and hardware for your requirements.
It has never been easier to get started with Kube, with thousands of online free and paid resources that will teach you the basics. You can also get certified through the CKA and CKAD programs to ensure you have all the knowledge you need to develop cloud native applications.
Cloud-agnostic Software/SaaS
With Kubernetes set up, the next step is to deploy the best software stack on it. Most of your software stack likely already natively supports Kubernetes and has a Docker container ready to go. If not, there is definitely a suitable replacement that will free you from the chains of a specific cloud ecosystem.
Couchbase supports multi-cloud strategies
With Couchbase Autonomous Operator, you get the market leading NoSQL database that runs on any compute. You can get Couchbase production ready with the Autonomous Operator in just a matter of weeks.
Couchbase’s memory-first architecture enables incredible performance. In a recent third-party benchmark against MongoDB and DataStax, Couchbase dramatically outperformed the competition with throughput on a 20 node cluster with 50 million records reaching almost 100k ops/sec at less than 10ms latency. Read the report here.
Try Couchbase for yourself today with our free trial.