In this blog post we’ll introduce an exciting new feature of the upcoming Couchbase Server version 4.5 (codename Watson), now in Beta.
We are talking about the Sub-Document API (shortened to subdoc).
Edit: This blog post has been edited with updates from the 4.5 Beta and Java SDK 2.2.6.
For other features of Couchbase 4.5, see Don Pinto’s blog posts about the Developer Preview and the Beta.
What Is It About?
Sub-document is a server-side feature that adds to the Memcached protocol that powers Couchbase Key-Value operations. It adds a few operations that act on a single JSON document, but rather than forcing you to retrieve the full content of the document, it allows you to specify the path inside the JSON that you are interested in either retrieving or mutating.
Let me show you why that is interesting with the following scenario: say you have a large (and I mean laaaarge) JSON document stored under the ID K in Couchbase. Inside the document, in the dictionary sub there’s a some field that you want to update. How would you go and do that with Couchbase 4.1?
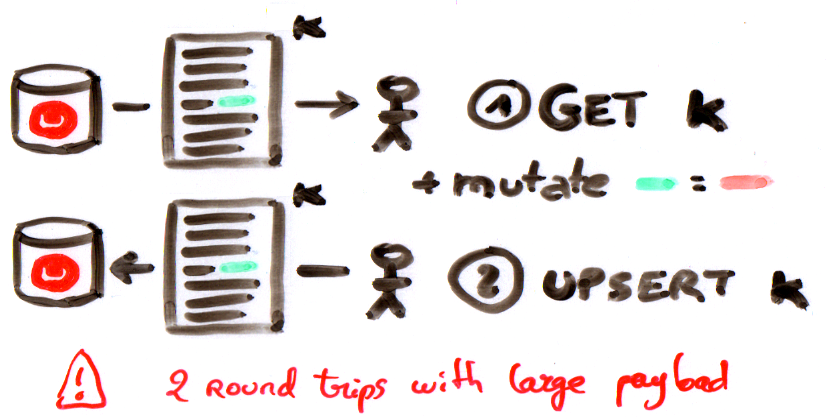
That’s right, you have to perform a get(k) of the whole document, modify its content locally and then perform an upsert (or a replace). You not only transmit the whole large document over the network when you are only interested in a small part of it, but you transmit it twice!
The subdoc API allows for leaner operations in such cases. Choose the operation you want to perform on your document and provide the key, the path inside the JSON and optionally the value that you want use for that operation, and voilà!
In our previous example, the path would be “sub.value“. This is pretty natural and is consistent with the path syntax used in our query language, N1QL. Here is what it looks like, not drawn to scale :)
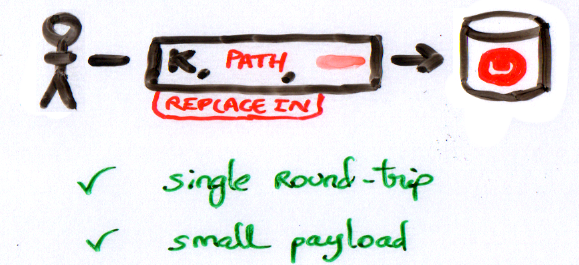
The message is actually just a few bytes, so the larger the original enclosing JSON document is, the greater the benefit.
The Client API
Now I bet I have your attention. But what are the offered operations, and what does the API look like?
We’ll take the example of the Java API, as offered by the 2.2.6 Java SDK.
For each example, we’ll consider that a “subdoc” JSON document exists in database and that it has the following content:
|
1 2 3 4 5 6 7 8 9 |
{ "fruits": [ "apple", "banana", "ananas" ], "sub": { "value": "someString", "bool": false }, "counter": 1, "junk": [ ... ] //a very very long array } |
We also consider that a Bucket instance, bucket, is available.
Lookup Operations
Without even talking about mutations inside a JSON, sometimes you just want to read a single value hidden deep into your document. Or just want to check if an entry is there. Subdoc offers two operations (get and exists) to do just that, which are made available through the bucket.lookupIn(String key) method.
The lookupIn method actually gives you a builder targeting a single JSON document (“key“), which you can in turn use to fluently describe which operations you want to perform. Once you’ve got the whole set of lookup specifications ready, you can execute the operation by calling the builder’s execute() method. Of course it can also be used for a single lookup.
This method returns a DocumentFragment in Java, representing the result. Note that multi-lookups always return such a result provided no document-level error occurs (ie. the document does not exist or is not JSON).
You can get each operation’s individual result by calling result.content(String path) or result.content(int operationIndex) (if you have multiple operations targeting the same path, in which case the former will always return the result of the first one). If there was an error, you get the appropriate child class of SubDocumentException. If not, you get the value (or “true” in the case of exists).
There’s also a exists method, similar to content but returning true only if the result object contains a result for that path/index and the corresponding operation was a success.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DocumentFragment result = bucket .lookupIn("subdoc") .get("sub.value") .exists("fruits") .exists("sub.foo") .execute(); String subValue = result.content("sub.value", String.class); boolean fruitsExist = result.content("fruits", Boolean.class); boolean fooExist = bucket.exists("sub.foo"); System.out.println(subValue + ", " + fruitsExist + ", " + foExist); |
The code above prints:
|
1 |
someString, true, false |
Mutation Operations
There are more varieties of mutation operations. Some are tailored to deal with arrays, while other are more adapted to dealing with dictionaries.
Once again we provide a builder to target mutations on a specific JSON document through bucket.mutateIn(String key). You chain in the operations that you want to perform and eventually call execute() to perform the set of mutations.
Mutations can take the CAS of the enclosing document into account, checking the provided CAS against the current one before applying the whole set of mutations. To do that, provide the CAS to check against, by calling .withCas(long cas) once in your builder chain.
Other with methods (which need only be called once) are:
withDurability(PersistTo p, ReplicateTo r): allows to observe a durability constraint on the whole set of mutations.withExpiry(int ttl): allows to give the document an expiry when successfully mutating it.
Also, some mutations allow to create deeper objects (eg. create the entry at path newDict.sub.entry, despite newDict and sub not existing). This is represented with the createParents parameter in the builder methods.
Taking the example above and using some of the mutation operations, we can efficiently do the following:
- Replace the fruit
ananas(which is incorrectly a french word) withpineapple. - Add a new fruit,
pearat the front of the fruits array. - Add a new entry to
subcallednewValue. - Increment a
counterby a delta of100. - Get rid of the
junklarge array. - Wait for cbserver to confirm data has been written to disk on master.
- Abort all if CAS on the server is not
1234.
Here’s how to do that using the Java SDK:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
boolean createParents = false; DocumentFragment result = bucket .mutateIn("subdoc") .replace("fruits[2]", "pineapple") .arrayPrepend("fruits", "pear", createParents) .insert("sub.newValue", "theNewValue", createParents) .counter("counter", 100L, createParents) .remove("junk") .withDurability(PersistTo.MASTER, ReplicateTo.NONE) .withCas(1234L) .execute(); |
Other available mutation operations are:
upsertarrayInsert(specialized in inserting a value in an array, at a specific index)arrayAppend(specialized in inserting a value at the end of an array)- arrayInsertAll (same as arrayInsert but inserting each element of a collection in the array)
- arrayPrependAll (same as arrayPrepend but adding each element of a collection to the front of an array)
- arrayAppendAll (same as arrayAppend but adding each element of a collection to the back of an array)
arrayAddUnique(specialized in inserting a value in an array if the value isn’t already present in the array)
After applying these 5 mutations, here’s what the document looks like in the database:
|
1 2 3 4 5 6 7 8 9 |
{ "fruits": [ "pear", "apple", "banana", "pineapple" ], "sub": { "value": "someString", "bool": false, "newValue": "theNewValue" }, "counter": 101 } |
Contrary to when you do multiple lookups, if any of the mutations fails then the whole set of operations is skipped and no mutation is performed. In this case, you will receive a MultiMutationException which you can check for the index of the first failing operation (as well as the corresponding error status).
Error Handling
Each subdocument operation can lead to subdocument related errors: what if the document that corresponds to the given key isn’t JSON? What if you provide a path that doesn’t exist? Or if the path contains an array index on an element that isn’t an array (eg. sub[1])?
All subdoc-specific errors have both a corresponding ResponseStatus in the Java SDK and a dedicated subclass of SubDocumentException. These exceptions are consistent in the SDKs that offer an API for subdocument:
The complete list in the Java SDK is:
- PathNotFoundException
- PathExistsException
- NumberTooBigException
- PathTooDeepException
- PathMismatchException
- ValueTooDeepException
- DeltaTooBigException
- CannotInsertValueException
- PathInvalidException
- DocumentNotJsonException*
- DocumentTooDeepException*
- MultiMutationException*
The last 3 are document-level (meaning that they apply to the whole document, without even considering the individual paths) so they’ll always be thrown directly by the builders’ execute() methods.
The others can also be thrown when calling DocumentFragment‘s content methods, in the cases where you have specified multiple lookup operations.
As said in the previous section, multiple mutate operations where at least one fails trigger a MultiMutationException being thrown. This exception has a firstFailureIndex() and firstFailureStatus() method to get information on which spec caused the whole operation to fail.
Conclusion
We hope that you’ll find great use cases for this brand new feature and that you will love it! So go grab the Couchbase 4.5 Beta, play with the API, and don’t hesitate to give us feedback!
In the meantime, Happy Coding! – the Java SDK Team
Thanks for the post. However I have a question regarding array handling: Is there a possibility to address array elements besides there position in the array, thus ids in sub documents cannot be used to access the elements?
I am using this code
DocumentFragment result = couchbaseBucket.async().lookupIn(docId).get(subDocId).execute().
toBlocking().singleOrDefault(null);
I am not sure why but result.rawContent(subDocId) returns null, whereas result.content(subDocId) returns proper value.
Couldn’t you point to the are which might be causing this issue>