The Query Workbench is an indispensable tool for developers who are working with Couchbase Server, especially those working with N1QL.
Sure the cbq command line tool is helpful, but the Query Workbench has a nice UI and also shows off the new Bucket Analysis schema inference feature.
To get to the Query Workbench, just point your browser to the Couchbase Console and click the new “Query” tab at the top of the page.

I’ve been a Microsoft-oriented developer for a while, and I use SQL Server Management Studio all the time. This new Query Workbench tool feels comfortable to me.
There are three main areas I want to draw your attention to:
-
The N1QL Editor area
-
The Results area
-
The Bucket Analysis area
N1QL Editor area
In this area, you can type/paste/edit adhoc N1QL queries.

Notice that you get some nice syntax highlighting with your N1QL. Click “Execute” to run a query. As an example, I just did a simple SELECT * from the travel-sample bucket.
As you continue to execute queries, you’ll build up a history. You can go back to these queries using the the arrow navagation at the top of the area, and clear the history at any time.
There’s also a convenient button to save a query to a text file.
Results area
In this area, you’ll see the results of the N1QL query that you executed.
Assuming the query was successful, you’ll see the results of it here. For example, here are the results of the above pictured query.
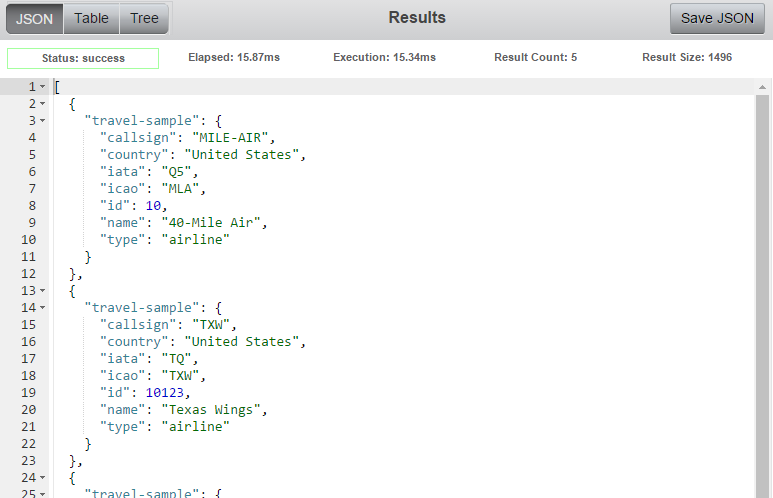
Sometimes it helps to visualize the results in a different way. You can switch between the default JSON, a Table view (which attempts to table-ize the results as best it can), and a tree view (which is a slightly more concise version of the JSON view). Here is the same query results, displayed three different ways.
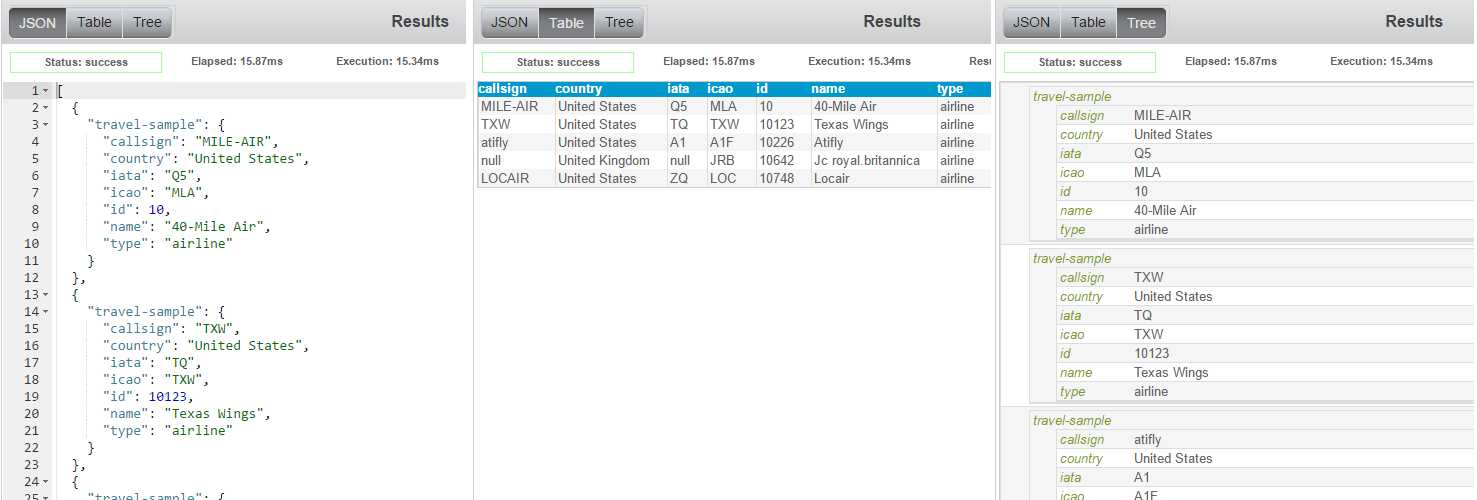
There is a button to save the JSON result to a text file.
Also notice that some information about the results is displayed: Status (success or otherwise), Elapsed time, Execution time, Result Count, and Result Size.
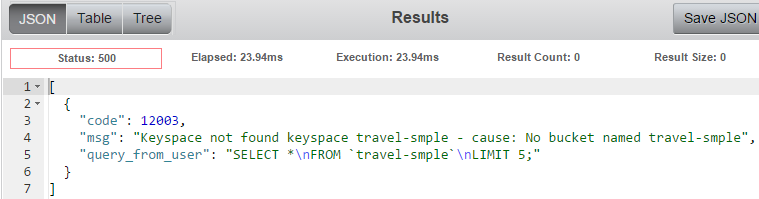
If your query is not successful, you’ll get a result with some information that might help you to fix the query you’re working on.
For example, if I made a typo in the bucket name:
Bucket Analysis
I saved the best for last. Couchbase Server is a schema-less document database. There are no constraints to the structure of the JSON documents you enter, and the fields in that document. If you wanted, every single document could be completely unique.
However, it is often the case that documents will tend to take on a regular form. Some percentage of the documents will share roughly the same fields and structure. With this in mind, if we were to take a random sample of all the documents in a bucket and examine them, we could “infer” a schema. That is exactly what you can do in the Bucket Analysis area.
Note that this is an Enterprise Edition feature, and is not available in Couchbase Community Edition. If you get a message like “Not Implemented INFER”, this means that you are probably using the Community Edition.
Click to expand a bucket, and Couchbase will take a sample (default of 1000 documents) and construct an implied schema. The bucket analysis will list each “flavor” of document that it finds, and what percentage of documents it sampled that match that flavor. For instance, in the travel-bucket, I see 5 flavors listed. You can also use a N1QL command like INFER ; the get the raw results.travel-sample

In the travel-sample, the flavors that Bucket Analysis found conveniently correspond to the documents' 'type' field values: airport, airline, landmark, route, and hotel. Now that I know these types exist, I can construct N1QL queries and/or indexes that use the type field. For instance: SELECT * FROM .travel-sample WHERE type='route' LIMIT 5;
Bucket Analysis can be very helpful when constructing N1QL queries or just figuring out the shape of the data within a bucket.
Summary
I don’t know how I’d get by without Query Workbench, personally. It’s my go-to tool when working with N1QL, creating indexes, and experimenting with Couchbase Server.
So, what do you think about Query Workbench? What kind of cool stuff do you plan to do with it? Ping me on Twitter, leave a comment, or email me (matthew.groves AT couchbase DOT com).