A pesquisa foi provavelmente um dos recursos mais negligenciados nos aplicativos anteriores. No entanto, nos últimos anos, ela realmente recebeu toda a atenção que merece, pois finalmente percebemos como ela pode aumentar as vendas ou moldar o comportamento e o envolvimento do usuário.
Nesta nova série do blog, eu gostaria de ir do zero ao especialista. Assim, ao final dela, você poderá implementar pesquisas "como um profissional".
Por que "Like %" não é suficiente?
Uma pesquisa bem implementada deve ser essencialmente rápida e relevante; "Como o %" não é nenhum deles. Vamos ver por quê:
O problema com a velocidade
Digamos que gostaríamos de implementar uma pesquisa de um filme de acordo com seu título. Uma consulta SQL ingênua que procurasse todos os filmes de "Star Trek" teria a seguinte aparência:
|
1 |
Select * from Movies where title like “Star Trek%” |
Por padrão, ele executará uma varredura completa da tabela tentando fazer a correspondência desse termo com todas as linhas. Mas ela pode ser otimizada com um índice, que provavelmente criará uma estrutura B-Tree. Portanto, mesmo buscas como a seguinte ainda aproveitariam parcialmente o índice:
|
1 2 |
Select * from Movies where title like “Star%Trek” Select * from Movies where title like “St%Trek” |
Mas e se o usuário for um grande fã do Batman e decidir pesquisar o termo "Dark Knight" (Cavaleiro das Trevas)? De acordo com o exemplo anterior, nossa consulta será parecida com a seguinte:
|
1 |
Select * from Movies where title like “Dark Knight%” |
A pesquisa acima tem o não trará nenhum resultado, pois o nome real do filme é "O Dark Knight Rises". Para corrigir esse problema, vamos adicionar um curinga no início do nosso termo de pesquisa:
|
1 |
Select * from Movies where title like “%Dark Knight%” |
Corrigido! Certo!? Infelizmente, não é bem assim. A consulta acima terá um resultado como "O Dark Knight Rises", mas ele não alavancará mais o índice e definitivamente não terá um bom desempenho em escala. Como o % não "entende" o conteúdo do seu campo. Em vez disso, ele trata um texto como uma coisa única, o que faz com que não seja a melhor opção para lidar com qualquer coisa que tenha algum tipo de estrutura subjacente.
Uma possível solução é usar o MATCH, mas ele também foi relatado como lento em alguns bancos de dados.
O problema da relevância
E se quisermos pesquisar também a visão geral do filme? Uma solução ingênua seria simplesmente adicionar um novo campo à consulta:
|
1 |
Select * from Movies where title like “%Dark Knight%” or overview like “%Dark Knight%” |
Essa abordagem introduz um novo problema: qualquer filme que mencione "Cavaleiro das Trevas" na visão geral tem a mesma relevância que aqueles que o mencionam no título, e a ordem dos resultados é totalmente incerta.
Um erro comum é pensar que o UNION DISTINCT poderia resolver esse problema. No entanto, atualmente, a maioria dos planejadores de consultas executa cada bloco da união em paralelo, o que bagunçará novamente a ordem/relevância.
Se você realmente quiser implementar algum tipo de relevância usando SQL simples, uma solução simples é executar duas consultas separadas e anexar o resultado de uma à outra. Obviamente, essa estratégia está longe de ser ideal e você ainda precisará lidar com a duplicação manualmente.
Os exemplos acima mostram uma das verdades não ditas sobre a pesquisa: O verdadeiro desafio da pesquisa não é encontrar uma correspondência, mas como classificá-la. Afinal, fazer a correspondência de um texto é uma tarefa muito simples, mas dar a ele a pontuação certa é algo que deve ser cuidadosamente elaborado.
Texto completo A busca vem em socorro!
Há muitas maneiras diferentes de pesquisar um termo, cada uma delas focada em uma estratégia específica. Abordaremos a maioria delas nos próximos artigos, mas, por enquanto, vamos nos concentrar em por que o FTS é muito melhor do que "Como o %":
A solução para a velocidade
Para poder consultar um banco de dados usando o FTS, primeiro você deve criar um índice invertido. Esse índice, em termos gerais, é um mapa de palavras e suas ocorrências:
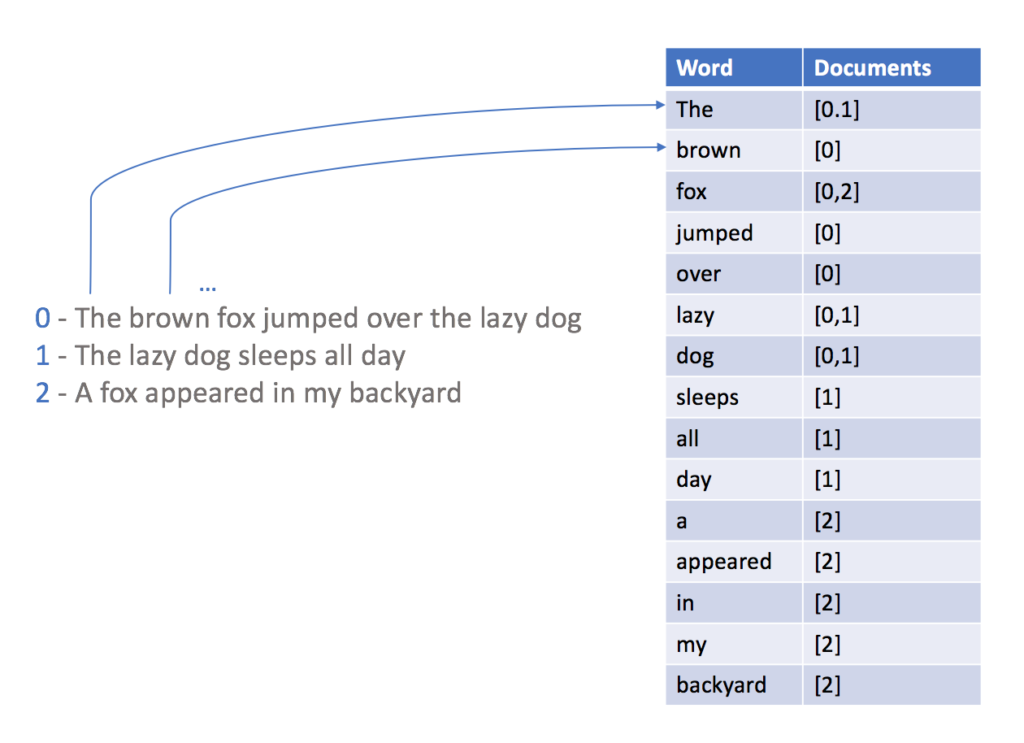
Com o índice acima em vigor, a pesquisa de uma palavra se torna uma tarefa simples, pois você pode obter facilmente apenas os documentos que contêm o termo de destino.
Observe que, durante a criação do índice invertido, convertemos as frases em uma matriz de palavras, de modo que os curingas não são necessários, pois podemos fazer a correspondência direta dos termos de destino com o nosso índice invertido. No entanto, mesmo com o uso de curingas aqui (ex.: *star*), a execução será mais rápida em escala, pois você só precisará iterar pelo índice para encontrar todas as correspondências, em vez de examinar todos os documentos do banco de dados.
Ainda não mencionei nada sobre dicionários, stemming, analisadores, tokenizadores e sinônimos. Chegarei lá na parte 2 desta série.
A solução para a relevância
A estratégia para implementar um resultado de pesquisa relevante pode variar de acordo com o domínio em que você está trabalhando. Em geral, a relevância pode ser manipulada de várias maneiras diferentes, sendo que a mais simples é chamada de boosting. Em termos gerais, o boosting é apenas uma maneira simples de atribuir um peso às correspondências de campo:
Consulta:
Título:"Star Trek"^2 Visão geral:"Jornada nas Estrelas"
No exemplo acima, a pontuação de uma correspondência para "Star Trek" na tabela título valerá o dobro do que uma partida no visão geral um. Basicamente, é assim que você pode sugerir como os resultados da pesquisa devem ser classificados.
Então, por que nem todo mundo está usando a pesquisa de texto completo?
Em geral, o FTS exige que você configure uma infraestrutura totalmente nova, adicione novas dependências, crie vários índices e, em seguida, envie todas as alterações de seus documentos para um sistema externo, como o Elastic Search ou Solr, mesmo que você queira apenas implementar uma pesquisa muito simples, como no exemplo anterior. Assim, os desenvolvedores tendem a evitar esse enorme volume de trabalho até que ele se torne estritamente necessário.
Esse é um dos motivos pelos quais decidimos incorporar um mecanismo FTS chamado Bleve no Couchbase, tudo o que você precisa fazer é criar um novo índice no Console da Web:
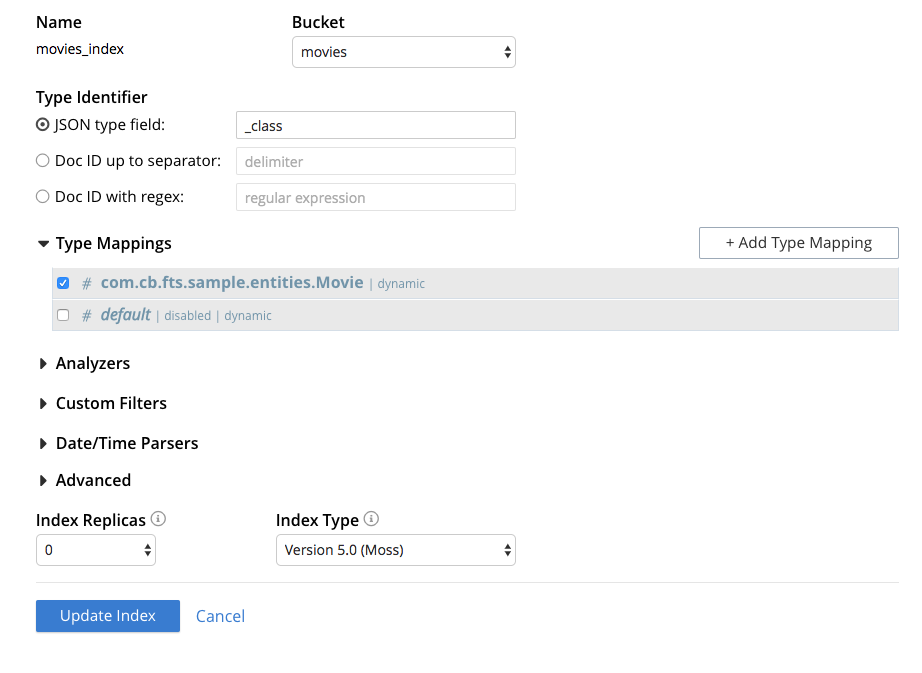
E você poderá automaticamente fazer pesquisas de texto completo usando o SDK padrão do Couchbase:
|
1 2 3 4 |
String indexName = "movies_index"; PhraseQuery query = SearchQuery.phrase("Star Trek"); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(20)); |
A maioria dos bancos de dados relacionais já tem suporte para pesquisa de texto completo, por que não usá-los?
Na verdade, pode ser uma boa opção para pequenos casos de uso, e ouvi alguns feedbacks positivos de desenvolvedores que estão fazendo isso. Minha recomendação pessoal é que você considere uma ferramenta adequada, como o Bleve, sempre que tiver um volume considerável de dados ou sempre que precisar escalonar em grande escala.
Há outra grande vantagem em usar um mecanismo FTS adequado: a linguagem de consulta. A maioria dos bancos de dados relacionais tenta reutilizar o SQL para isso, e isso pode ficar muito confuso se você tentar escrever pesquisas avançadas. Afinal de contas, o SQL não foi projetado para lidar com consultas de conjunção/disjunção, facetas, fatores de classificação complexos etc.
Série de pesquisa de texto completo
- Compreensão de analisadores e tokenizadores - Parte 2
- Correspondência difusa - Parte 3