La búsqueda era probablemente una de las funciones más olvidadas en las aplicaciones del pasado. Sin embargo, en los últimos años se le ha prestado toda la atención que merece, ya que por fin nos hemos dado cuenta de cómo puede aumentar las ventas o moldear el comportamiento y el compromiso de los usuarios.
En esta nueva serie de blogs, me gustaría ir de cero a experto. Como tal, al final de la misma, usted será capaz de poner en práctica las búsquedas "como un profesional".
¿Por qué "Como %" no es suficiente?
Una búsqueda bien realizada debe ser esencialmente rápida y pertinente; "Como %"no es ninguno de ellos. Veamos por qué:
El problema de la velocidad
Supongamos que queremos realizar una búsqueda de una película por su título. Una consulta SQL ingenua que buscara todas las películas de "Star Trek" tendría el siguiente aspecto:
|
1 |
Select * from Movies where title like “Star Trek%” |
Por defecto, ejecutará un escaneo completo de la tabla intentando hacer coincidir este término con todas las filas. Pero puede optimizarse con un índice, que creará probablemente una estructura de árbol B. Por lo tanto, incluso búsquedas como la siguiente aprovecharían parcialmente el índice:
|
1 2 |
Select * from Movies where title like “Star%Trek” Select * from Movies where title like “St%Trek” |
Pero, ¿y si el usuario es un gran fan de Batman y decide buscar el término "Caballero Oscuro"? Según el ejemplo anterior, nuestra consulta tendrá el siguiente aspecto:
|
1 |
Select * from Movies where title like “Dark Knight%” |
La búsqueda de arriba tiene el no traerá ningún resultado como el verdadero nombre de la película es "En Dark Knight Rises". Para solucionar este problema, añadamos un comodín al principio de nuestro término de búsqueda:
|
1 |
Select * from Movies where title like “%Dark Knight%” |
¡Arreglado! ¿Verdad? Desgraciadamente, no. La consulta anterior finalizará con un resultado como "En Dark Knight Rises", pero ya no aprovechará el índice y definitivamente no tendrá un buen rendimiento a escala. Como % no "entiende" el contenido de su campo. Más bien, trata un texto como algo único, lo que hace que no sea la mejor opción para tratar cualquier cosa que tenga algún tipo de estructura subyacente.
Una posible solución es utilizar MATCH, pero también se ha Según los informes, es lento en algunas bases de datos.
El problema de la relevancia
¿Y si quisiéramos buscar también el resumen de la película? Una solución ingenua sería añadir un nuevo campo a la consulta:
|
1 |
Select * from Movies where title like “%Dark Knight%” or overview like “%Dark Knight%” |
Este enfoque introduce un nuevo problema: cualquier película que mencione "El Caballero Oscuro" en el resumen tiene la misma relevancia que las que lo llevan en el título, y el orden de los resultados es totalmente incierto.
Un error común es pensar que UNION DISTINCT podría resolver este problema. Sin embargo, la mayoría de los planificadores de consultas de hoy en día ejecutan cada bloque de la unión en paralelo, lo que volverá a estropear el orden/relevancia.
Si realmente desea implementar algún tipo de relevancia utilizando SQL simple, una solución sencilla es ejecutar dos consultas separadas y añadir el resultado de una a la otra. Por supuesto, esta estrategia dista mucho de ser óptima y aún tendría que gestionar la duplicación manualmente.
Los ejemplos anteriores muestran una de las verdades tácitas de la búsqueda: El verdadero reto de la búsqueda no es encontrar coincidencias, sino clasificarlas.. Al fin y al cabo, emparejar un texto es una tarea muy sencilla, pero darle la puntuación adecuada es algo que debe elaborarse cuidadosamente.
Texto completo la búsqueda acude al rescate
Hay muchas formas diferentes de buscar un término, cada una centrada en una estrategia específica. Cubriremos la mayoría de ellas en los próximos artículos, pero por ahora, centrémonos en por qué FTS es mucho mejor que "Como %":
La solución para la velocidad
Para poder consultar una base de datos con FTS, primero hay que crear un índice invertido. Este índice, a grandes rasgos, es un mapa de palabras y sus ocurrencias:
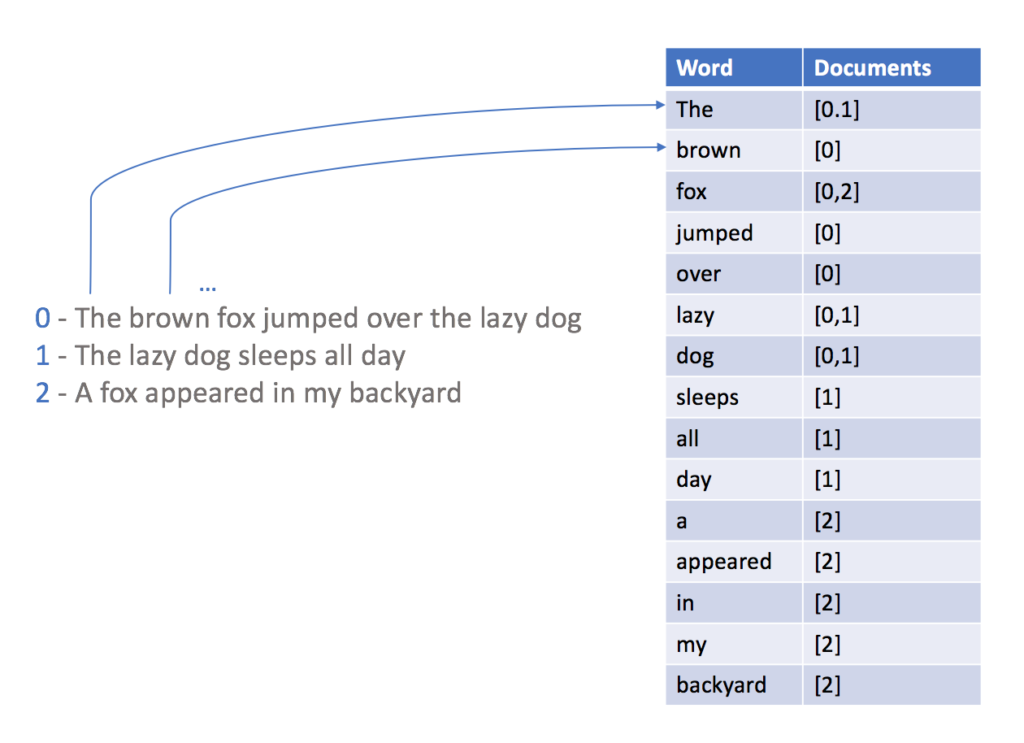
Con el índice anterior en su lugar, la búsqueda de una palabra se convierte en una tarea sencilla, ya que puede obtener fácilmente sólo los documentos que contienen el término de destino.
Tenga en cuenta que durante la creación del índice invertido, hemos convertido las frases en una matriz de palabras, por lo que los comodines no son necesarios, ya que podemos comparar directamente los términos de destino con nuestro índice invertido. No obstante, incluso el uso de comodines aquí (Ej: *estrella*) seguirá siendo más rápido a escala, ya que sólo tendrá que iterar a través de su índice para encontrar todas las coincidencias en lugar de escanear todos los documentos de su base de datos.
Aún no he mencionado nada sobre diccionarios, stemming, analizadores, tokenizadores y sinónimos. Lo haré en la segunda parte de esta serie.
La solución para la pertinencia
La estrategia para implementar un resultado de búsqueda relevante puede variar según el dominio en el que se esté trabajando. En general, la relevancia puede manipularse de múltiples maneras, la más sencilla de las cuales se denomina "boosting". A grandes rasgos, el boosting es una forma sencilla de asignar un peso a las coincidencias de campo:
Consulta:
Título:"Star Trek"^2 | Resumen:"Star Trek"
En el ejemplo anterior, la puntuación de una coincidencia para "Star Trek" en el título valdrá el doble que un partido en el visión general uno. Básicamente, así puede sugerir cómo deben ordenarse los resultados de la búsqueda.
¿Por qué no utiliza todo el mundo la búsqueda de texto completo?
Por lo general, FTS exige que se configure una infraestructura completamente nueva, se añadan nuevas dependencias, se creen varios índices y, a continuación, se envíen todos los cambios de los documentos a un sistema externo como Búsqueda elástica o Solr, incluso si sólo desea implementar una búsqueda muy simple como nuestro ejemplo anterior. Así pues, los desarrolladores tienden a evitar esta ingente cantidad de trabajo hasta que se hace estrictamente necesario.
Esa es una de las razones por las que hemos decidido incorporar un motor FTS llamado Bleve en Couchbase, entonces todo lo que necesitas hacer es crear un nuevo índice en la Consola Web:
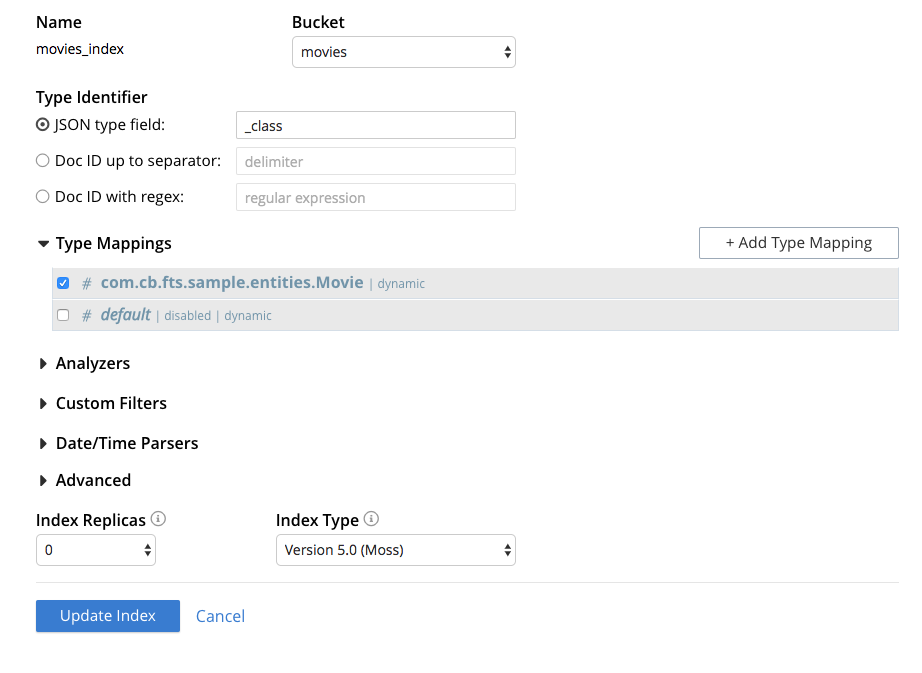
Y automáticamente podrás hacer búsquedas de texto completo usando el SDK de Couchbase por defecto:
|
1 2 3 4 |
String indexName = "movies_index"; PhraseQuery query = SearchQuery.phrase("Star Trek"); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(20)); |
La mayoría de las bases de datos relacionales ya admiten búsquedas de texto completo, ¿por qué no utilizarlas?
En realidad, podría ser una buena opción para pequeños casos de uso, y he oído algunos comentarios positivos de los desarrolladores que lo hacen. Mi recomendación personal es que consideres una herramienta adecuada, como Bleve, siempre que tengas un volumen considerable de datos, o siempre que necesites escalar masivamente.
Otra gran ventaja de utilizar un motor FTS adecuado es el lenguaje de consulta. La mayoría de las bases de datos relacionales intentan reutilizar SQL para ello, y puede resultar realmente complicado si se intentan escribir búsquedas avanzadas. Al fin y al cabo, SQL no se diseñó para tratar consultas de conjunción/disyunción, facetas, factores de clasificación complejos, etc.
Serie de búsqueda de texto completo
- Comprender los analizadores y tokenizadores - Parte 2
- Emparejamiento difuso - Parte 3