O que é o Vector Search?
Os desenvolvedores estão migrando para a pesquisa vetorial para tornar seus aplicativos mais adaptáveis aos usuários. Como o termo pesquisa implica que a pesquisa vetorial serve para localizar e comparar objetos usando um conceito conhecido como vetores. Simplificando, ele ajuda você a encontrar similaridade entre objetos, permitindo que você encontre relações complexas e contextualmente conscientes em seus dados. É uma tecnologia que está por trás e potencializa os aplicativos relacionados à pesquisa de última geração.
A pesquisa vetorial é um recurso de pesquisa com tecnologia de IA em plataformas de dados modernas, como bancos de dados vetoriaisque ajuda os usuários a criar aplicativos mais flexíveis. Você não está mais limitado à pesquisa básica de palavras-chave; em vez disso, pode encontrar semanticamente semelhantes informações em qualquer tipo de mídia digital.
Em sua essência, ele é um dos muitos sistemas de aprendizado de máquina alimentados por modelos de linguagem grandes (LLMs) de vários tamanhos e complexidades. Eles estão disponíveis por meio de bancos de dados e plataformas tradicionais e estão até mesmo sendo levados para o borda para execução em dispositivos móveis.
Para saber mais sobre a pesquisa vetorial, os termos relacionados, os recursos e como ela se aplica às inovações tecnológicas dos bancos de dados modernos, consulte inteligência artificial (IA), continue lendo.
O que significa vetor?
Um vetor é um estrutura de dados que contém uma matriz de números. No nosso caso, isso se refere a vetores que armazenam um resumo digital do conjunto de dados ao qual foram aplicados. Pode ser considerado como uma impressão digital ou um resumo, mas formalmente é chamado de incorporação. Aqui está um exemplo rápido de como um deles pode se parecer:
|
1 |
"blue t-shirts": [-0.02511234 0.05473123 -0.01234567 ... 0.00456789 0.03345678 -0.00789012] |
Benefícios da pesquisa vetorial
A pesquisa vetorial oferece uma série de novos recursos aos bancos de dados e aos aplicativos que os utilizam. Em resumo, a pesquisa vetorial ajuda os usuários a encontrar mais correspondências contextualmente conscientes em uma grande coleção de informações (também conhecida como corpus). A ideia de proximidade é importante - a pesquisa vetorial agrupa itens estatisticamente para mostrar o quanto são semelhantes ou relacionados. Isso se aplica a muito mais do que apenas texto, embora muitos de nossos exemplos sejam baseados em texto para ajudar na comparação com os sistemas de pesquisa tradicionais.
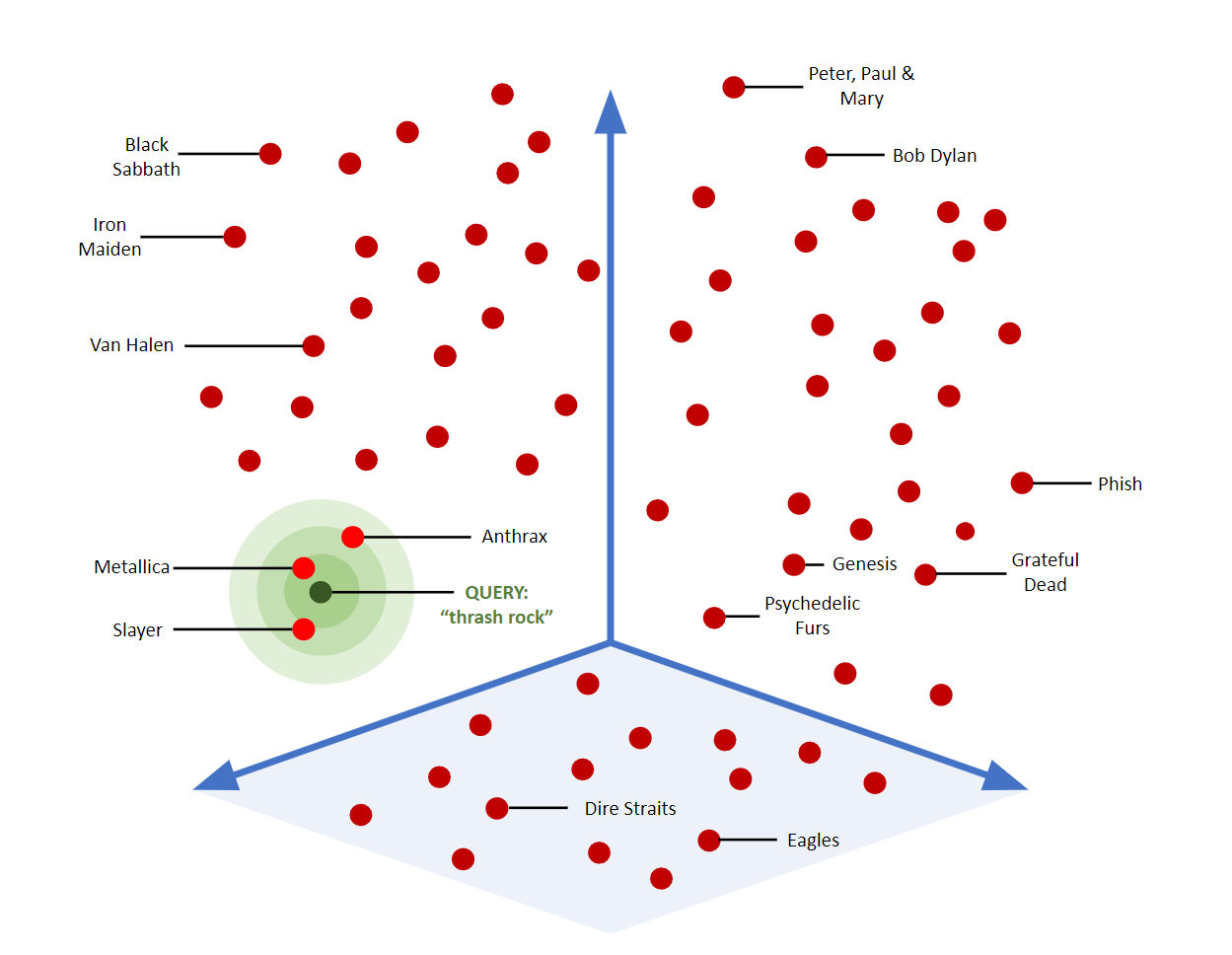
Esse gráfico mostra um exemplo visual de como a pesquisa vetorial pode mapear, localizar e agrupar objetos "semelhantes" no espaço 3D.
Acesso a um vasto conhecimento geral
A pesquisa vetorial também é uma ótima estratégia para introduzir ferramentas de inteligência artificial em um aplicativo, proporcionando flexibilidade adaptativa impossível apenas com as ferramentas de pesquisa tradicionais. Devido ao grande volume de LLMs públicos disponíveis, qualquer empresa pode adotar um e usá-lo como base para a pesquisa em seus aplicativos. Como os LLMs armazenam muitas informações, os resultados da pesquisa podem agregar um valor exponencial ao seu aplicativo sem a necessidade de escrever um código complexo. Essa é uma maneira pela qual muitos aplicativos estão sendo atualizados com novos recursos avançados.
Pesquisa superpoderosa vs. tradicional
Felizmente, a pesquisa vetorial também é uma abordagem de pesquisa mais rápida em cenários mais complexos. Os sistemas tradicionais de pesquisa baseados em palavras-chave podem ser otimizados para encontrar texto correspondente em documentos, mas quando você precisa aplicar algoritmos complexos de correspondência difusa ou soluções alternativas extremas de predicados booleanos (muitas cláusulas WHERE, por exemplo), eles começam a ficar mais lentos e complexos.
As várias compensações necessárias para pesquisar com sucesso em ambientes complexos podem ser evitadas com a pesquisa vetorial. No entanto, a compensação precisará de uma API de nível de serviço (por exemplo, OpenAI) com recursos adequados para ajudá-lo a fazer a interface dos aplicativos com um LLM. Você também terá opções e limitações dependendo do LLM que está por trás do seu sistema de pesquisa vetorial.
Qual é a diferença entre a pesquisa tradicional e a pesquisa vetorial?
Os benefícios acima se sobrepõem a algumas das diferenças técnicas entre as abordagens de pesquisa tradicional e vetorial. Nesta seção, investigamos o que realmente importa entre essas diferentes abordagens.
Pesquisa semântica e de contexto
Muitos sistemas diferentes relacionados à pesquisa usaram a pesquisa de palavras-chave ou frases otimizadas para encontrar preciso correspondências textuais ou para encontrar documentos que usam uma palavra-chave com mais frequência. O desafio é que isso pode carecer de contexto e flexibilidade. Por exemplo, uma pesquisa de texto por "árvore" pode nunca corresponder a dados com nomes reais de espécies de árvores, mesmo que isso seja altamente relevante. Esse tipo de correspondência contextual é uma forma de pesquisa semântica-onde o contexto e a relação entre as palavras são importantes.
Similaridade
No entanto, a pesquisa vetorial não se refere apenas a relações semânticas. Por exemplo, em um aplicativo baseado em texto, ela vai além do uso de palavras e frases individuais para encontrar semelhante correspondência de documentos usando palavras de entrada, frases, parágrafos ou mais - procurando exemplos de texto que correspondam à semântica e ao contexto em um nível muito profundo.
A busca por similaridade também funciona para imagens. Se você tivesse que escrever um aplicativo que comparasse duas imagens, como faria isso? Se você apenas comparasse cada pixel de uma com cada pixel de outra, encontraria apenas imagens que são idêntico em cor, resolução, codificação, etc. Mas se você puder analisar suas imagens e produzir uma incorporação vetorial para o conteúdo, poderá compará-las e encontrar correspondências. Aplicado ao exemplo das imagens, uma incorporação vetorial descreve o conteúdo de cada imagem e, em seguida, permite que você as compare - uma maneira muito mais robusta de comparar e encontrar "proximidade" entre elas.
Você pode saber mais sobre incorporação de vetores em nossa outra postagem do blog em detalhes, ou continue lendo para ter uma visão geral básica.
Como funciona a pesquisa vetorial
A pesquisa de vetores cria e compara embeddings de vetores. Ela funciona com base no princípio de que os dados podem ser transformados em uma representação vetorial numérica (incorporação) e comparados a outros dados catalogados com uma representação digital semelhante (usando LLMs).
Ele indexa diferentes tipos de conteúdo digital (texto, áudio, vídeo, etc.) em uma linguagem comum que as redes neurais entendem. Veja nossa guia para IA generativa que discute as redes adversárias generativas (GANs) para saber mais sobre as abordagens de redes neurais.
Os modelos criados pelos LLMs contêm os vetores que representam os dados nos quais o modelo foi treinado. Por exemplo, cada parágrafo da Wikipedia poderia ser resumido e indexado como vetores. Em seguida, um usuário pode enviar um vetor de seus próprios dados (geralmente criado por meio de um processo de incorporação) a um sistema de pesquisa de vetores para encontrar parágrafos semelhantes.
Há muito trabalho pesado por trás dessas etapas, mas essa é a essência.
Três etapas para criar um aplicativo de pesquisa vetorial
Há três estágios para criar ou usar um aplicativo de pesquisa vetorial. Elas incluem:
-
- Criação de embeddings para seus dados ou consultas personalizados
- Comparando os resultados com um mecanismo de vetor treinado em modelos de linguagem grandes (LLMs) para encontrar a melhor correspondência de dados semânticos com o corpus de dados no modelo
- Comparar os resultados do LLM com seus dados de aplicativos personalizados ou banco de dados para encontrar correspondências mais relevantes
Etapa 1 - Criar embeddings de uma solicitação
Os embeddings funcionam como a impressão digital de um dado em aplicativos vetoriais, de forma semelhante a uma chave que pode ser usada em um índice posteriormente. Um dado (texto, imagens, vídeo etc.) é enviado a um aplicativo de incorporação vetorial que o transforma em uma representação numérica como uma lista de números (um vetor). Essa incorporação vetorial representa o objeto que foi fornecido ao aplicativo de incorporação. Nos bastidores, um mecanismo de modelo de linguagem grande (LLM) é usado para criar a incorporação para que ela possa ser usada para recuperar correspondências do mesmo LLM na próxima etapa.
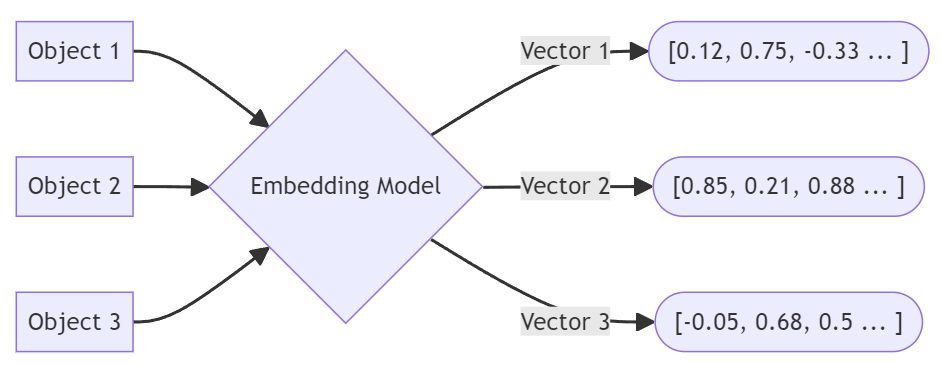
Os objetos são submetidos a um incorporação de vetores processo.
No mundo do banco de dados, o texto de uma coluna da tabela poderia ser executado pelo mecanismo de incorporação, e o objeto vetorial poderia ser salvo em uma propriedade para essa linha ou objeto JSON. As incorporações de cada documento ou registro são então indexadas para futuras comparações internas durante uma solicitação de pesquisa.
Vamos considerar um aplicativo da Web que permite pesquisar um catálogo de varejo. Um usuário pode inserir um texto descrevendo um tipo de roupa e uma cor para pesquisar a disponibilidade. A partir daí, o aplicativo envia a solicitação do usuário a um LLM como parte do processo de incorporação de vetor. O LLM é usado para computar uma representação vetorial para uso na próxima etapa. "Camisetas azuis" pode se tornar um vetor com a seguinte aparência em uma matriz de alta dimensão, como mostrado aqui armazenado em JSON:
|
1 2 3 4 |
{ "word": "blue t-shirt", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] } |
Esse é um exemplo excessivamente simplificado, mas, em sua raiz, as incorporações de vetores são simplesmente matrizes multidimensionais que resumem uma parte dos dados analisados por um determinado processo de aprendizado de máquina. Os embeddings vêm em diferentes tipos e tamanhos e são baseados em uma ampla gama de LLMs diferentes, mas isso está além do escopo deste artigo.
Etapa 2 - Encontrar correspondências de um LLM
Agora, considere que um LLM criou essencialmente embeddings para todos os dados sobre os quais foi construído. Se a Wikipédia foi usada para treinar o LLM, talvez cada parágrafo tenha produzido seus próprios embeddings. Muitos embeddings!
O estágio de pesquisa é o processo de encontrar incorporações que mais se aproximam umas das outras. Um mecanismo de pesquisa vetorial pode usar uma incorporação existente ou criar uma em tempo real a partir de uma consulta de pesquisa. Por exemplo, ele pode receber a entrada de texto do usuário em uma consulta de aplicativo ou banco de dados e usar o LLM para encontrar conteúdo semelhante no modelo. Em seguida, ele retorna as correspondências mais relevantes para o aplicativo.
Continuando com nosso exemplo de varejo, a incorporação do vetor "camisetas azuis" pode ser usada como uma chave para encontrar dados semelhantes. O aplicativo enviaria esse vetor a um LLM central para encontrar o conteúdo mais semelhante e semanticamente relacionado com base nas descrições de texto ou imagens analisadas ao criar o LLM.
Por exemplo, você pode receber de volta uma lista de cinco documentos que correspondem à similaridade em seus embeddings vetoriais. Como você pode ver, cada um tem sua própria representação vetorial.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "embeddings": [ { "word": "blue t-shirt", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] }, { "word": "navy shirt", "embedding": [0.71, -0.42, 0.85, 0.15, -0.68, 0.29, 0.53, 0.78] }, { "word": "azure top", "embedding": [0.73, -0.46, 0.87, 0.11, -0.64, 0.33, 0.56, 0.74] }, { "word": "cobalt blouse", "embedding": [0.75, -0.41, 0.89, 0.14, -0.67, 0.28, 0.54, 0.77] }, { "word": "sapphire tee", "embedding": [0.72, -0.44, 0.86, 0.13, -0.66, 0.30, 0.55, 0.76] }, { "word": "denim shirt", "embedding": [0.70, -0.43, 0.84, 0.16, -0.69, 0.27, 0.52, 0.79] } ] } |
Etapa 3 - Encontre correspondências para seus próprios dados
Se tudo o que você está procurando são correspondências com informações armazenadas em um LLM, então está tudo pronto. No entanto, os aplicativos realmente adaptáveis desejarão obter correspondências e informações de fontes de dados internas, como um banco de dados corporativo.
Suponha que os documentos ou registros no banco de dados já tenham embeddings vetoriais salvos neles, além de ter as correspondências do LLM. Agora, você pode pegá-los, enviá-los ao recurso de pesquisa vetorial do seu banco de dados e encontrar documentos relacionados no banco de dados. Operacionalmente, isso se pareceria com outro campo indexado, mas daria uma sensação mais qualitativa aos resultados da pesquisa.
Como o Vector Search encontra correspondências?
A pesquisa vetorial combina três conceitos: dados gerados pelo usuário (uma solicitação), um LLM corpus que inclui modelos que representam uma fonte de dados (um modelo) e dados personalizados em um banco de dados (correspondência personalizada). A pesquisa vetorial permite que esses três fatores trabalhem juntos.
O que o Vector Search pode suportar?
A pesquisa vetorial encontrará similaridade entre qualquer tipo de dados, desde que possa criar embeddings e compará-los com outros criados da mesma forma (a partir do mesmo LLM).
Dependendo do LLM usado, os resultados podem variar drasticamente devido aos dados de origem nos quais o LLM foi treinado. Por exemplo, se você quiser pesquisar imagens semelhantes, mas usar um LLM que inclua apenas literatura clássica, obterá respostas inutilizáveis (embora, se forem fotos de escritores clássicos, possa haver alguma esperança).
Da mesma forma, se você estiver criando um caso jurídico e seu LLM for treinado apenas com dados do Reddit, você estará se preparando para um cenário único que poderá dar um ótimo filme algum dia (depois que você for expulso da Ordem, é claro).
É por isso que é preciso ter certeza de que o LLM que está impulsionando sua experiência está direcionado para o público-alvo correto. Caso de uso de pesquisa vetorial e as informações de que você precisa são importantes. Os LLMs gerais muito grandes terão mais contexto, mas os LLMs especializados em seu setor terão informações mais precisas e diferenciadas para sua empresa.
Como a pesquisa de vetores é conduzida em escala
Qualquer sistema empresarial que realize pesquisa vetorial deve ser capaz de ser dimensionado quando entrar em produção (consulte nosso guia para replicação de dados na nuvem). Isso faz com que os sistemas de pesquisa de vetores que podem replicar e fragmentar seus índices particularmente crucial.
Quando o sistema precisa pesquisar o índice para encontrar correspondências, a carga de trabalho pode ser distribuída entre vários nós.
Da mesma forma, a criação de novas incorporações e a indexação delas também se beneficiarão do isolamento de recursosAssim, outras funções do aplicativo não são afetadas. O isolamento de recursos significa que as funções relacionadas à pesquisa vetorial têm seus próprios recursos de memória, CPU e armazenamento.
Em um contexto de banco de dados, é essencial que todos os serviços tenham recursos alocados adequadamente para que não concorram entre si. Por exemplo, as consultas de tabela, a análise em tempo real, o registro em log e os serviços de armazenamento de dados precisam de seu próprio espaço para respirar, além dos serviços de pesquisa de vetores.
APIs distribuídas para acesso ao LLM também são importantes. Como muitos outros serviços podem estar solicitando embeddings, as APIs e os sistemas que produzem os embeddings também devem ser capazes de crescer com mais tráfego. Para serviços de LLM baseados em nuvem, certifique-se de que seus requisitos de produção possam ser atendidos pelos contratos de nível de serviço antes de iniciar a criação de protótipos.
O uso de serviços externos muitas vezes pode ser ampliado de forma rápida e eficiente, mas exigirá financiamento adicional à medida que for ampliado. Certifique-se de que as escalas de preços deslizantes sejam claramente compreendidas ao avaliar as opções.
O futuro da pesquisa vetorial
O desenvolvimento adaptativo de aplicativos será viabilizado por pesquisa híbrida cenários. Um único método de pesquisa ou consulta não será mais suficiente para a flexibilidade necessária no futuro. Os recursos de pesquisa híbrida significam que você pode usar a pesquisa vetorial para obter correspondências semânticas, mas restringir os resultados usando predicados SQL básicos e até mesmo consultas geográficas usando um índice espacial.
O acoplamento desses elementos em uma única experiência de pesquisa híbrida facilitará aos desenvolvedores extrair o máximo de flexibilidade de seus aplicativos. Isso incluirá a extensão de todos os recursos de pesquisa de vetores para a borda com dispositivos móveis integração de banco de dados, bem como na nuvem e no local.
Geração aumentada por recuperação (RAG) permitirá que o desenvolvedor adicione ainda mais consciência contextual personalizada sobre o LLM. Isso reduzirá a necessidade de treinar novamente um LLM e, ao mesmo tempo, dará aos desenvolvedores a flexibilidade de manter a incorporação e a correspondência atualizadas.
A pesquisa de vetores também será definida por um tipo de módulo de conhecimento plugável que permite que as empresas tragam uma ampla gama de informações com base em LLMs de várias fontes. Imagine um aplicativo de campo móvel que ajude a fazer a manutenção de postes de energia. Uma pesquisa de imagem semântica pode ajudar a identificar problemas com a estrutura física de um poste, mas com outro módulo de conhecimento sobre plantas, ele também pode alertar o usuário sobre uma planta tóxica vista nas proximidades.
Recursos de IA do Couchbase
Para continuar lendo sobre pesquisa de vetores, estratégias e outros tópicos relacionados a inteligência artificialConfira os seguintes recursos:
-
- O que são Vector Embeddings?
- Desbloqueando a pesquisa de próximo nível: O poder dos bancos de dados vetoriais
- Uma visão geral da geração aumentada por recuperação
- Couchbase apresenta um novo serviço de nuvem de IA, o Capella iQ
- Explicação dos modelos de idiomas grandes
- Um guia para o desenvolvimento de IA generativa
- Como a IA generativa funciona com o Couchbase
- GenAI: uma nova ferramenta na caixa de ferramentas do desenvolvedor
- Tenha contato prático com a pesquisa vetorial:
Perguntas frequentes sobre o Vector Search
Por que a pesquisa vetorial é importante?
A pesquisa vetorial é importante porque oferece uma nova maneira de encontrar similaridade e contexto entre dados digitais, usando as mais recentes técnicas de aprendizado de máquina e IA.
O que são embeddings de pesquisa vetorial?
As incorporações de vetores são vetores que armazenam uma representação numérica exclusiva de uma parte dos dados analisados. Os modelos de linguagem ampla (LLMs) são usados por aprendizado de máquina (ML) ferramentas para analisar os dados de entrada e produzir as incorporações de vetores que descrevem os dados. A incorporação do vetor é então armazenada em um banco de dados ou arquivo para outra ocasião.
Qual é a diferença entre a pesquisa tradicional e a pesquisa vetorial?
A principal diferença é que a pesquisa tradicional é otimizada para encontrar correspondências precisas e exatas de palavras-chave ou frases, enquanto a pesquisa vetorial é projetada para encontrar conceitos semelhantes em um contexto de significado mais definido.
Quais são os desafios da pesquisa de vetores?
O principal desafio é que os aplicativos devem contar com grandes modelos de linguagem (LLMs) para ajudar a criar incorporações e encontrar correspondências contextuais. Essa é uma nova peça na arquitetura de informações atual e exige uma avaliação cuidadosa da segurança, do desempenho e da escalabilidade.