Se você for um desenvolvedor que trabalha com o Couchbase ou o Capella, vai querer saber sobre Capella DataStudio. É uma ferramenta gratuita, apoiada pela comunidade, com uma interface de usuário simples e elegante para gerenciar Capella Operacional, Capella Columnare Clusters do servidor Couchbase. Isso não apenas aumenta a produtividade do desenvolvedor, mas também torna sua experiência muito mais suave (e mais legal).
Agora, ele vem com um recurso totalmente novo: Gerador de dados sintéticos.
Gerador de dados sintéticos do Capella DataStudio foi projetado para capacitar os desenvolvedores com uma maneira simples e sem código de criar dados realistas e significativos para seus projetos. Esteja você testando aplicativos, treinando modelos de aprendizado de máquina ou simulando sistemas de grande escala, esse recurso oferece flexibilidade e potência inigualáveis.
O que são dados sintéticos?
Os dados sintéticos não são apenas dados "falsos"; eles são projetados para imitar as propriedades, as distribuições e os relacionamentos dos dados do mundo real. Enquanto os dados falsos podem gerar valores aleatórios sem contexto, os dados sintéticos têm o objetivo de:
-
- Manter relações lógicas entre os campos (por exemplo, cidade e estado são consistentes)
- Seguir distribuições realistas, como a geração de valores que aderem a distribuições normais ou ponderadas
- Ser estatisticamente relevante para testes, análises e simulações
- Isso torna os dados sintéticos incrivelmente úteis em cenários em que os dados reais não estão disponíveis, são confidenciais ou insuficientes
Continue lendo para se aprofundar na geração de dados sintéticos ou assista a este vídeo para vê-lo em ação.
Principais recursos do Gerador de dados sintéticos do Capella DataStudio
Dados realistas e correlacionados
Nosso gerador garante que os relacionamentos de dados sejam significativos. Por exemplo, os endereços incluem valores correspondentes de cidade, estado, código postal, latitude e longitude. Os nomes e os dados demográficos são logicamente consistentes.
Conjuntos de tipos incorporados, totalmente configuráveis
Escolha entre uma ampla variedade de conjuntos de tipos incorporados para iniciar sua geração de dados. Cada tipo pode ser personalizado para atender às suas necessidades específicas, sejam elas nomes, locais, datas ou campos numéricos.
Extensível: traga seus próprios conjuntos tipográficos
Tem seus próprios conjuntos de dados ou requisitos específicos? Importe conjuntos de tipos personalizados para ampliar os recursos do gerador e criar dados personalizados que se ajustem ao seu caso de uso exclusivo.
Relacionamento de chave primária/chave estrangeiras
Modele conjuntos de dados complexos com facilidade, definindo relações entre campos. As chaves estrangeiras podem fazer referência a dados de chave primária, permitindo estruturas de dados relacionais realistas.
Tratamento de expressões com funções avançadas
Aproveite as funções incorporadas para criar expressões complexas sem escrever uma única linha de código. Combine e manipule campos dinamicamente para obter o máximo controle sobre os dados.
Sem restrições quanto ao tamanho dos dados
Gere dados em qualquer escala, desde algumas linhas para pequenos testes até milhões de documentos para simulações em grande escala. Não há limites para o que você pode criar.
Integração perfeita com o Capella Operational e o Couchbase Server
Leve seus dados sintéticos mais longe, importando-os diretamente para o Capella Operational ou para o Couchbase Server. Isso garante um fluxo de trabalho simplificado, desde a geração até a implementação.
Por que escolher o Capella DataStudio para a geração de dados sintéticos?
Com sua interface de usuário intuitiva e um conjunto robusto de recursos, o Synthetic Data Generator do Capella DataStudio é a ferramenta definitiva para a criação de conjuntos de dados significativos e de alta qualidade. Quer você seja um desenvolvedor, cientista de dados ou testador, esse recurso economizará tempo, reduzirá a complexidade e aprimorará seus projetos com dados realistas. Explore suas infinitas possibilidades e redefina sua experiência de criação de dados.
Geração de dados sintéticos
Vejamos como funciona o Gerador de dados sintéticos.
Criador de esquemas
O esquema é criado campo a campo, uma linha de cada vez. Cada linha tem um mínimo de dois atributos:
-
- O nome do campo
- O tipo de dados do campo - tsua poderia vir do núcleo ou usuário typeset
Dependendo do tipo de dados, mais atributos podem ser expostos:
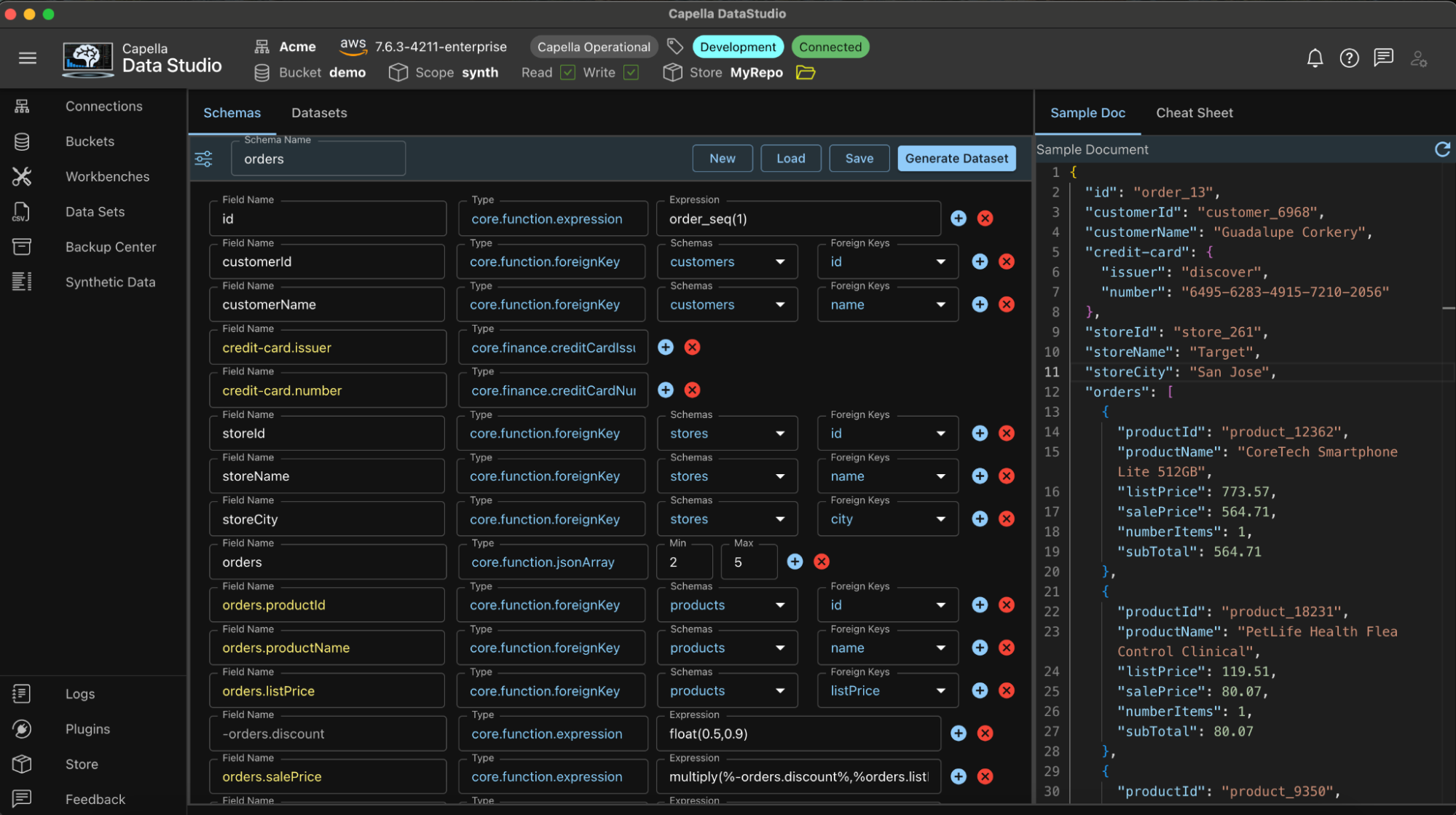
Exemplo do esquema de pedidos
Nome do campo
-
- Os nomes de campo podem ser qualquer nome de campo compatível com JSON
- Os objetos JSON aninhados são especificados pelo formato pontilhado
- Suporte a JSON profundamente aninhado
- Os nomes de campo com um prefixo de traço duplo serão tratados como uma chave primária
- Ao gerar conjuntos de dados, essas chaves também serão exportadas e salvas como localStore/SyntheticData/DataSets/schemaName.pk arquivo
- As chaves primárias podem ser especificadas somente nos campos do documento raiz
- Objetos JSON, campos aninhados e campos ocultos não podem ser chaves primárias
- Os nomes de campo com um único prefixo de traço serão tratados como um campo oculto
- Os campos ocultos são usados como armazenamento temporário usado na referência de campo
- Os campos ocultos não podem ser chave primária
- Os campos ocultos não aparecerão no documento JSON
- Os objetos JSON não podem ser ocultados
- Os campos aninhados podem ser ocultados
Tipo de dados
O tipo de dados é selecionado em uma caixa de diálogo:

A imagem mostra os conjuntos de tipos principais e um conjunto de tipos fornecido pelo usuário (acme.pizzas)
Conjuntos de tipos principais
Fornecido pelo Capella DataStudio:

Conjuntos de tipos de usuário
Fornecido por você para ampliar a funcionalidade do Gerador de dados. Você precisa fornecer dois arquivos:
-
- Um arquivo CSV com dados
- Um arquivo de manifesto que descreve o Typeset
Processo de composição do usuário
Quando um documento é gerado com a composição do usuário, acontece o seguinte:
-
- Uma linha aleatória é lida do arquivo
- A linha é armazenada em um cache de linha
- Os campos são então lidos a partir desse cache de linhas
- Quando um campo é lido, ele é anulado no cache de linha
- Se o campo for nulo, todo o cache de linha será invalidado e uma nova linha aleatória será lida
- Os campos são lidos do cache de linhas e, para um determinado documento, os dados são correlacionados
- Cada documento começa com um novo cache de linha
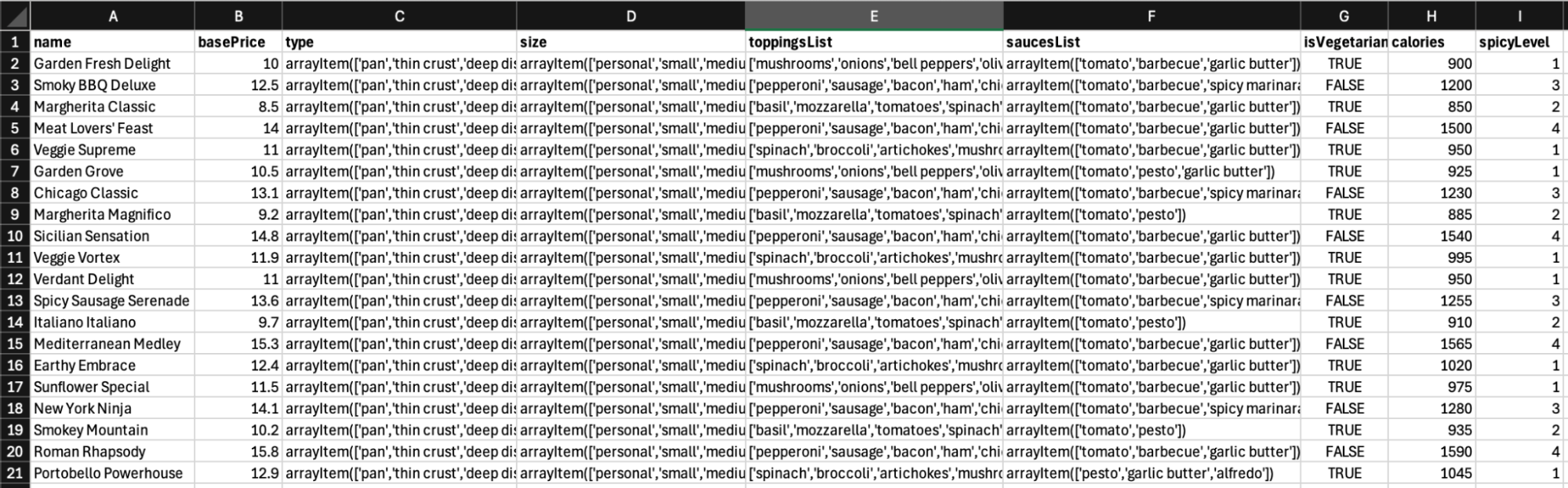
Exemplo de tipografia de pizzas

Função principal
Há três tipos de dados especiais:
-
- expressão
- foreignKey
- jsonArray
1. core.function.expression
As expressões são uma forma eficiente de personalizar o esquema:
-
- As expressões são apenas cadeias de caracteres
- Eles podem ter incorporado referências (incluído em %%) e funções
Arquitetura de documentos e expressões
Vamos ver como o documento é criado:
-
- O documento é criado de cima para baixo, linha por linha.
- Sempre temos um documento parcial em cada estágio da linha.
- Primeiro, a expressão é uma string
- Ele vai para um Avaliador de expressões
- O documento parcial, com seus campos e valores, é fornecido ao avaliador.
- Isso significa que os campos anteriores e seus valores avaliados estão agora disponíveis.
- O documento parcial, com seus campos e valores, é fornecido ao avaliador.
- A string é então examinada para referências
- As referências são nomes de campos, usados anteriormente, e seus valores, do documento parcial.
- As referências são substituídas pelos valores
- Isso significa que as referências também podem estar dentro de funções
- A string é então examinada para funções
- As funções são então executadas e seus valores são substituídos no documento parcial.
- Por fim, o Evaluator retorna o resultado.
- O documento é criado de cima para baixo, linha por linha.
2. core.function.foreignKey
Chaves estrangeiras e correlação de dados
Ao trabalhar com dados relacionais, é fundamental manter a integridade referencial por meio de chaves estrangeiras. Veja como nosso gerador de dados sintéticos lida com relacionamentos de chave estrangeira:
Como funcionam as chaves estrangeiras
Primeiro, você precisará gerar seu conjunto de dados primário. Digamos que você tenha um esquema para Departamentos que gera um arquivo CSV contendo IDs e nomes de departamentos. Esses IDs de departamento servem como chaves primárias no conjunto de dados Departments.
Quando você cria outro esquema, por exemplo, para FuncionáriosSe você tiver uma chave primária, poderá especificar campos que fazem referência a essas chaves primárias existentes. O construtor de esquemas oferece dois menus suspensos:
-
- Um menu suspenso para selecionar o conjunto de dados de origem (por exemplo, "Departments")
- Um menu suspenso para selecionar o campo de chave primária a ser referenciado (por exemplo, "id")
Processo de geração de dados
Ao gerar dados com referências de chave estrangeira, o sistema:
-
- Seleciona aleatoriamente uma linha do conjunto de dados de origem
- Lê o(s) valor(es) da chave primária dessa linha
- Usa esses valores no novo conjunto de dados que está sendo gerado
Manutenção da correlação de dados
Um recurso importante é como lidamos com várias referências de chave estrangeira. Se o seu esquema fizer referência a várias colunas do mesmo conjunto de dados de origem, os valores serão extraídos da mesma linha para manter a correlação lógica.
Por exemplo, se o esquema Employee fizer referência a department_id e department_location do conjunto de dados Departments, ambos os valores virão do mesmo registro de departamento. Isso garante que os dados sintéticos mantenham relações realistas entre os campos relacionados.
Essa abordagem ajuda a criar conjuntos de dados sintéticos mais realistas, preservando a integridade referencial e as relações lógicas presentes nos dados do mundo real.
3. core.function.jsonArray
Configuração da matriz JSON
Ao configurar um campo de matriz JSON, você pode especificar:
-
- Número mínimo de objetos na matriz
- Número máximo de objetos na matriz
Em seguida, o gerador criará matrizes com um número aleatório de objetos dentro do intervalo especificado.
Estrutura e limitações
As matrizes JSON seguem essas regras:
-
- Cada matriz contém objetos JSON simples e planos
- O aninhamento de matrizes não é suportado (não há matrizes dentro de matrizes)
- Cada objeto da matriz segue a mesma estrutura
Geração de dados
Depois que o esquema tiver sido criado de forma satisfatória, é hora de gerar dados.
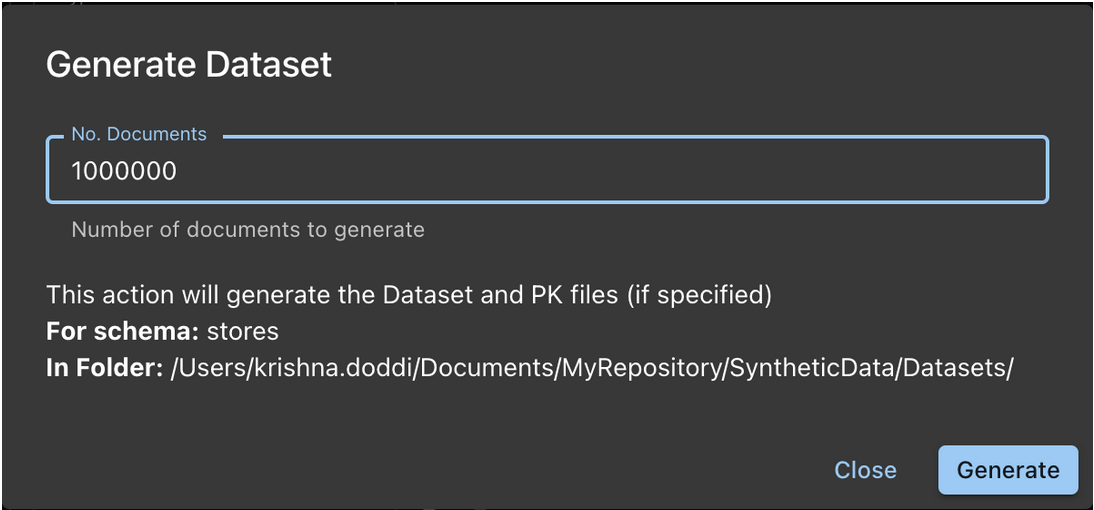
A imagem mostra a geração de um conjunto de dados sintéticos
-
- O conjunto de dados é gerado e gravado em LocalStore/SyntheticData/DataSets/
- O nome do arquivo do conjunto de dados é schemaName.json
- Este é um Linhas JSON arquivo
- Se o documento tiver campos marcados como Chave primária (prefixados com traço duplo), então, um schemaName.pk também é produzido
- O arquivo .pk é um arquivo CSV
- Se algum campo tiver o seq() as sequências são incrementadas em 1
- Não há limite para o número de documentos
Exemplos de conjuntos de dados
cliente.json
|
1 2 3 4 5 6 7 8 9 |
[ {"id":"customer_1","name":"Lula Kuhic","gender":"Demi-man","age":65,"email":"Electa29@yahoo.com","address":{"street":"46938 VonRueden Village Suite 474","city":"Los Angeles","state":"California","zip":"90001","geo":{"latitude":33.7423,"longitude":-117.4412}},"phones":{"home":"(310) 788-5382","cell":"(310) 923-5319"}}, {"id":"customer_2","name":"Chelsea Wilderman","gender":"Transsexual female","age":58,"email":"Augusta_Mann27@yahoo.com","address":{"street":"8409 Jesse Mill Apt. 289","city":"Sacramento","state":"California","zip":"95814","geo":{"latitude":38.8607,"longitude":-121.0356}},"phones":{"home":"(916) 879-6009","cell":"(916) 503-2269"}}, … ] |
cliente.pk
|
1 2 3 4 |
id,name "customer_1","Lula Kuhic" "customer_2","Chelsea Wilderman" … |
Visualização do conjunto de dados
Você pode visualizar os conjuntos de dados gerados. O painel de visualização suporta a visualização dos dados no formato JSON ou no formato de tabela.
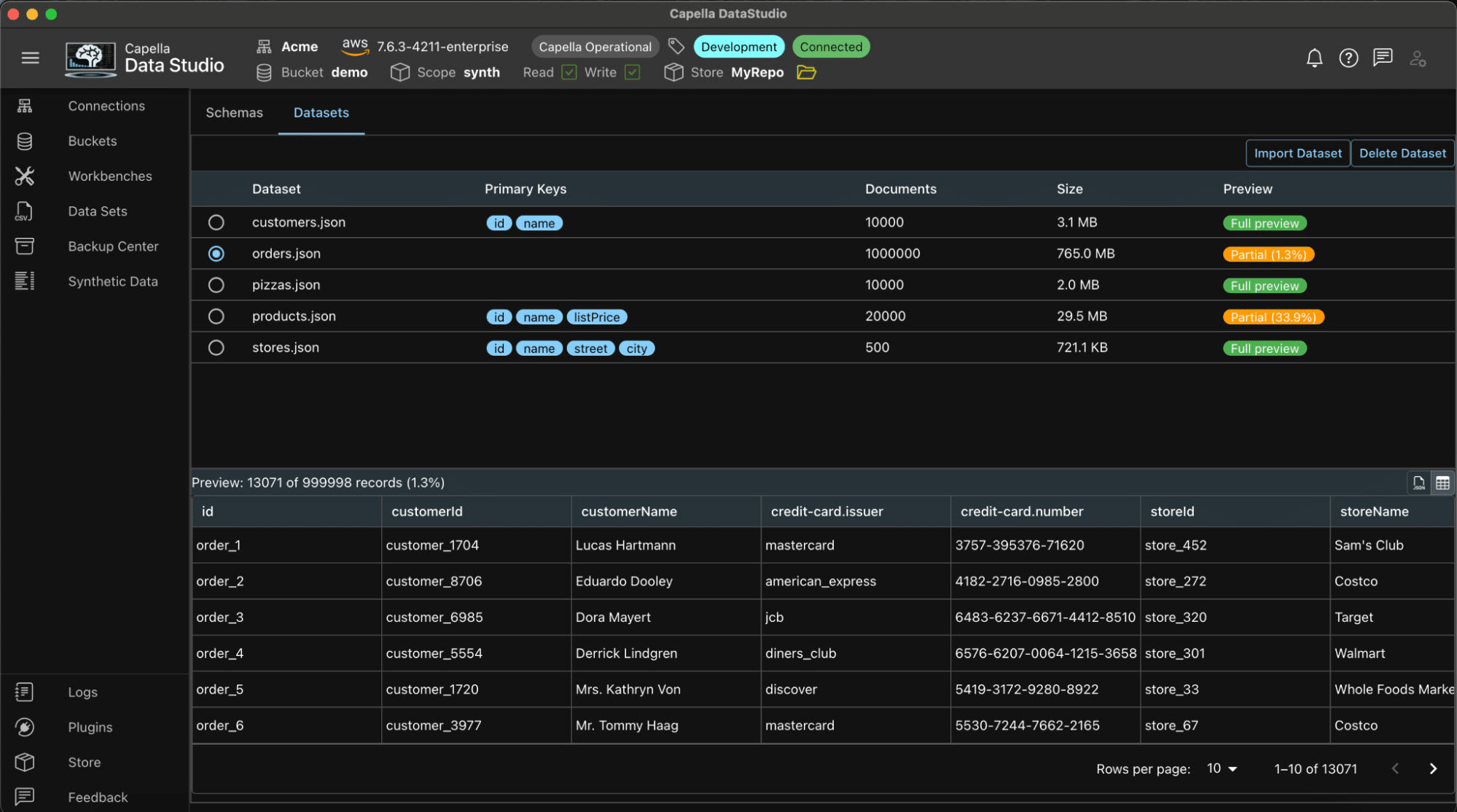
A imagem mostra o painel de visualização e a visualização da tabela
Importação
Você pode importar o conjunto de dados gerado para sua coleção do Couchbase:
-
- A importação usa o utilitário cbimport e oferece todas as suas opções de importação
- Não há limite de arquivos para importação
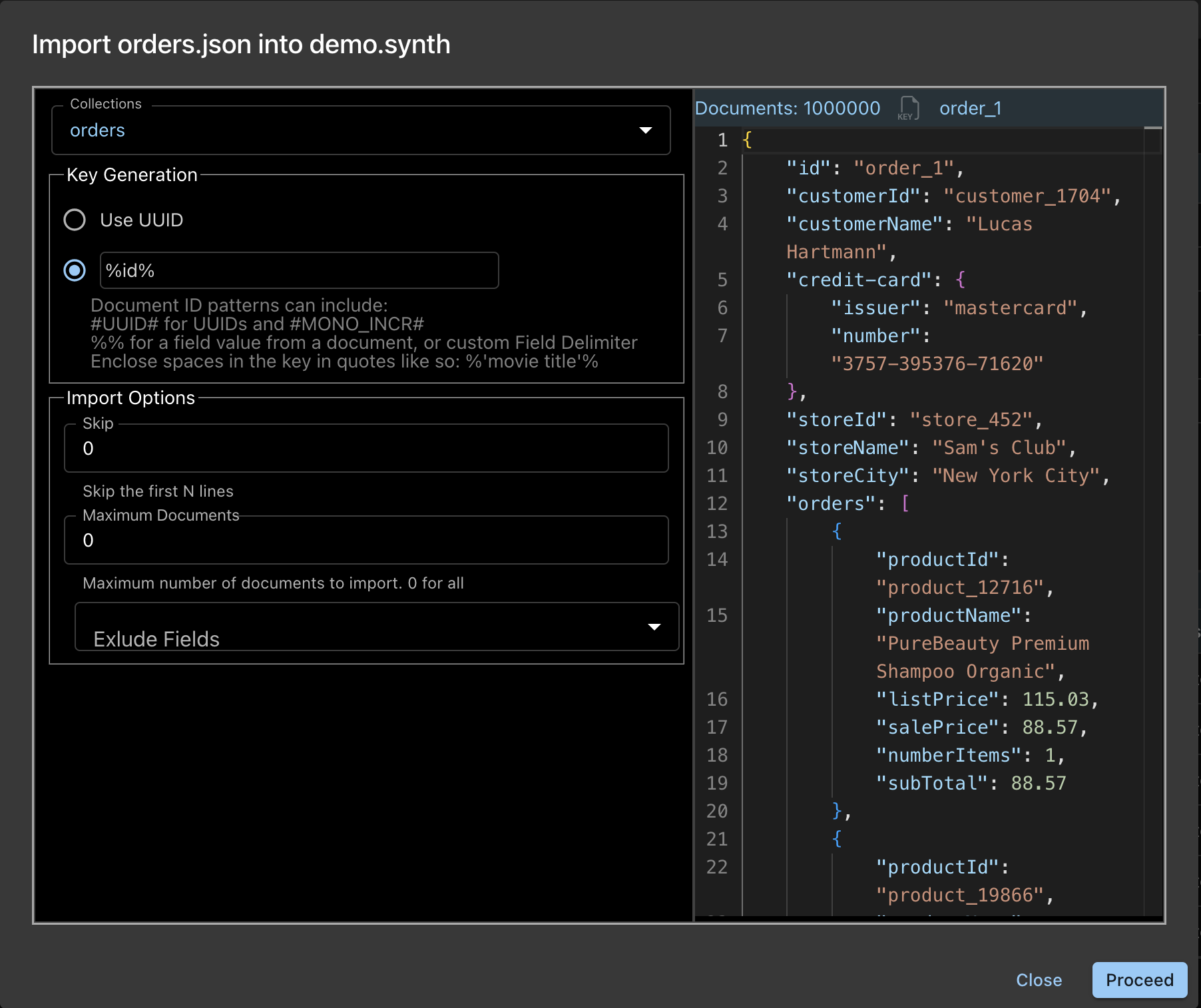
A imagem mostra a caixa de diálogo e as opções de importação
Pronto para aumentar sua produtividade?
O Capella DataStudio é a ferramenta que os desenvolvedores estavam esperando. Esteja você gerenciando clusters do Couchbase Server, do Capella Operational ou do Capella Columnar, este aplicativo torna seu trabalho mais fácil, mais rápido e, sim, mais legal.
Tente Capella DataStudio de graça e dê uma olhada em nosso vídeos tutoriais:
Com o Capella DataStudio, o gerenciamento de dados nunca foi tão divertido ou produtivo!
Apêndice - ffunções suportadas em expressões
A tabela mostra a lista de funções disponíveis para uso em expressões:
| Tipo | Exemplo | Saída |
| int(min,max) | int(1,10) | 6 |
| float(min,max) | float(1.234,10.587) | 5.824 |
| float(min,max,dec) | float(1,10,2) | 5.82 |
| normal(mean,std,dec) | normal(50,10,3) | 56.48 |
| bool() | bool() | FALSO |
| bool(bias) | bool(0,8) | VERDADEIRO |
| date(from,to) | date(01/01/2024,12/31/2024) | “02/02/2024” |
| time(from,to) | horário(08:00 am, 5:00 pm) | "08:47 AM" |
| arrayItem(array) | arrayItem(["cat", "mouse", "dog"]) | "gato" |
| arrayItem(array) | arrayItem(["cat:2″, "mouse:1″, "dog:7"]) | "cachorro" |
| arrayItems(array,length) | arrayItems(["cat", "mouse", "dog"],2) | ["gato", "rato"] |
| arrayItems(array,length) | arrayItems(["cat:2″, "mouse:1″, "dog:7"]) | ["cat", "dog"] |
| arrayKV(array,field) | arrayKV(["cat:2″, "mouse:1″, "dog:7″], "cat") | 2 |
| gps(latitude,longitude) | gps(37.3382,-121.8863) | gpsObject |
| gpsNearby(gps,radius) | gpsNearby(%gps%,20) | gpsObject |
| seq(startNumber) | seq(1000) | 1030 |
| uuid() | uuid() | "e46b493a-..." |
| add(num1,num2) | add(1.23,3.45) | 4.68 |
| subtrair(num1,num2) | subtrair(1.23,3.45) | -2.22 |
| multiply(num1,num2) | multiplicar(1.23,3.45) | 4.24 |
| porcentagem(num,den) | porcentagem(1.23,3.45) | “35.65%” |
| accumulate(num,name) | accumulate(%orders.subTotal%,sale) | 1304.84 |