Este blog foi publicado originalmente no blog pessoal de Cecile Le Pape&apos. Para ver a postagem original do blog, clique em aqui.
Em minha post anteriorEm meu artigo, falei sobre como configurar um serviço de gerenciamento de conteúdo flexível usando o Couchbase como repositório de metadados, em cima de um servidor Apache Chemistry. Os blobs em si (pdf, pptx, docx, etc.) são armazenados em um sistema de arquivos separado ou em um armazenamento de blobs. Hoje, gostaria de mostrar como o Couchbase pode ser usado para armazenar os próprios blobs, usando um gerenciador de pedaços personalizado. A ideia é armazenar não apenas os metadados de um documento (data de criação, criador, nome etc.), mas também o próprio blob.
O objetivo dessa nova arquitetura é reduzir o número de sistemas diferentes (e as licenças a serem pagas) e também se beneficiar diretamente dos recursos de replicação oferecidos pelo Couchbase.
Primeiro, vamos lembrar que o Couchbase não é um armazenamento de blob. Trata-se de um armazenamento de documentos baseado em memória, com um gerenciamento de cache adhoc ajustado para que a maioria dos dados armazenados no Couchbase esteja na RAM para consultas rápidas. Os dados também são replicados entre os nós (se a replicação estiver ativada) dentro do cluster e, opcionalmente, fora do cluster, se o XDCR for usado. É por isso que os dados armazenados no Couchbase não podem ser maiores que 20 MB. Esse é um limite rígido e, na vida real, 1 MB já é um documento grande para ser armazenado.
Sabendo disso, a questão é: como posso armazenar dados binários grandes no Couchbase? A resposta é simples: dividindo-os em pedaços!
A nova arquitetura tem a seguinte aparência:
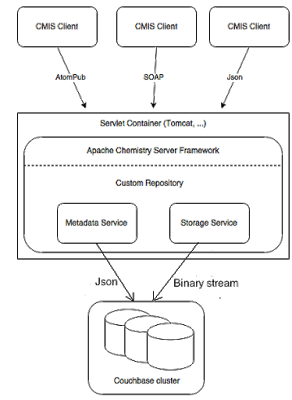
Agora há 2 buckets no Couchbase:
- cmismeta : usado para armazenar metadados
- cmisstore Usado para armazenar blobs
Quando uma pasta é criada, somente o compartimento cmismeta é modificado com uma nova entrada porque, obviamente, uma pasta não está associada a nenhuma bolha. Essa é simplesmente uma estrutura usada pelo usuário para organizar os documentos e navegar na árvore de pastas. As pastas são virtuais. O ponto de entrada da estrutura é a pasta raiz, conforme descrito anteriormente.
Quando um documento (por exemplo, um pdf ou um pptx) é inserido em uma pasta, três coisas acontecem:
- Um documento json contendo todos os seus metadados é inserido no bucket cmismeta, com uma chave exclusiva. Digamos, por exemplo, que o documento tenha a chave L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=.
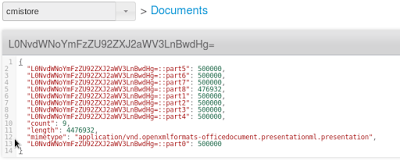
- Um novo documento json com a mesma chave é criado no bucket do cmisstore. Esse documento contém o número de blocos, o tamanho máximo de cada bloco (o mesmo para todos os blocos, exceto para o último, que pode ser menor) e o tipo de mime do aplicativo.
- A bolha anexada ao documento é dividida em partes binárias (o tamanho depende de um parâmetro que você pode definir nas propriedades do projeto). Por padrão, um pedaço tem 500 KB de tamanho. Cada pedaço é armazenado no bucket do cmisstore como um documento binário, com a mesma chave "L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=" como prefixo e um sufixo "::partxxx", em que xxx é o número do bloco (0, 1, 2, ...).
Por exemplo, se eu inserir um pptx chamado CouchbaseOverview.pptx, cujo tamanho é 4476932 bytes, no Couchbase, obtenho o seguinte:
- No bucket cmismeta, um documento json chamado L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
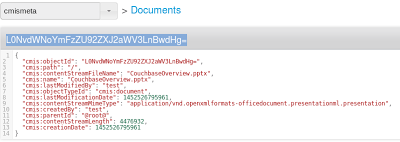
- No bucket cmisstore, um documento json também chamado L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=
-
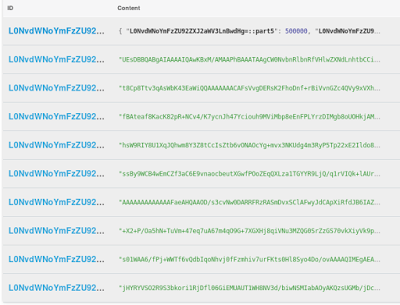
9 blocos contendo dados binários e denominados L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part0, L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part1, ... , L0NvdWNoYmFzZU92ZXJ2aWV3LnBwdHg=::part8
O CouchbaseStorageService é a classe que implementa a interface StorageService já usada para armazenamento local ou armazenamento S3, como mostrei em meu blog anterior. A primeira diferença é a reutilização da mesma instância do CouchbaseCluster usada para o MetadataService porque apenas um ambiente do Couchbase deve ser instanciado para economizar muitos recursos (RAM, CPU, rede etc.).
Agora vamos ver o método writeContent propriamente dito:
*/
público vazio writeContent(String dataId, ContentStream fluxo de conteúdo)
JsonDocument jsondoc = JsonDocument.create(dataId, doc);
Agora, o que fazer para recuperar o arquivo do Couchbase? A ideia principal é obter cada parte, concatenar cada uma delas na mesma ordem em que foram cortadas e enviar a matriz de bytes para o fluxo. Provavelmente há muitas maneiras de fazer isso, mas eu simplesmente implementei uma maneira direta usando uma única matriz de bytes na qual escrevo cada byte.
lançamentos StorageException {
JsonDocument doc = balde.get(dataId);
JsonObject json = doc.content();
Inteiro nbparts = json.getInt("count" (contagem));
Inteiro comprimento = json.getInt("length" (comprimento));
balde.get(dataId + PARTE_SUFFIX + i,BinaryDocument.classe);
Por fim, vamos ver o que acontece na ferramenta de bancada fornecida pelo Apache Chemistry? Posso ver o documento na pasta raiz e, se eu clicar duas vezes nele, o conteúdo será transmitido do Couchbase e exibido no visualizador associado (aqui, o PowerPoint) com base no tipo de mime.
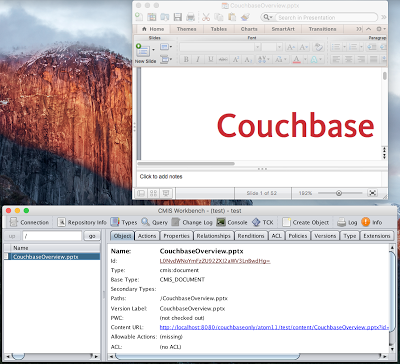
Workbench e documento abertos no PowerPoint após um clique duplo
Esse é um ótimo artigo, mas gostaria de saber se ele também serve para formatos de vídeo.