[Este blog foi distribuído pelo site http://damienkatz.net/].
Tenho o prazer de informar que agora estamos praticamente entrando no modo de estabilização total e otimização de recursos para o Couchbase Server 2.0. Levamos muito mais tempo do que planejamos. Criar um banco de dados de documentos distribuído de alto desempenho, eficiente, confiável e com todos os recursos é uma questão nada trivial ;)
Além da mesma tecnologia de memcached e clustering "simples, rápida e elástica" que temos nas versões anteriores do Couchbase, adicionamos três grandes recursos novos para ampliar drasticamente seus recursos e casos de uso, bem como seu desempenho e confiabilidade.
Couchstore: Armazenamento de alto rendimento e orientado para a recuperação
Um dos maiores obstáculos para a versão 2.0 foi o fato de o mecanismo de armazenamento baseado em Erlang ser muito pesado em termos de recursos em comparação com a versão 1.8.x, que usa SQLite. Fizemos uma tonelada de trabalho de otimização e modificações, retirando tudo o que podíamos para torná-lo o mais rápido e eficiente possível e, no processo, tornamos nosso código de armazenamento baseado em Erlang várias vezes mais rápido do que quando começamos, mas o uso da CPU e dos recursos ainda era muito alto e, sem muitos núcleos de CPU, não conseguíamos obter o desempenho total do sistema onde nossos clientes atuais precisavam.
No final, a resposta foi reescrever o mecanismo de armazenamento principal e o compactador em C, usando um formato compatível, bit a bit, com nosso mecanismo de armazenamento Erlang, de modo que as atualizações gravadas em um processo pudessem ser lidas, indexadas, replicadas e até compactadas a partir do Erlang. É o mesmo projeto básico de MVCC orientado à recuperação e com tail-append, portanto, é simples gravar nele a partir de um processo do sistema operacional e lê-lo a partir de outro processo. O formato de armazenamento é imune à corrupção causada por falhas no servidor, OOM killers ou até mesmo perda de energia.
Reescrevê-lo em C nos permitiu romper muitas barreiras de otimização. Estamos obtendo facilmente o dobro da taxa de transferência de gravação em relação ao mecanismo Erlang otimizado e aos mecanismos SQLite, com menos CPU e uma fração da sobrecarga de memória.
Nem tudo isso se deve ao fato de o C ser mais rápido que o Erlang. Uma boa parte do aumento de desempenho se deve ao fato de poder incorporar o mecanismo de persistência no processo. Isso, por si só, reduziu muito a CPU e a sobrecarga, evitando a transmissão de dados entre processos e a conversão para estruturas Erlang na memória. Mas também é C, o que proporciona um bom controle de baixo nível e podemos otimizar com muito mais facilidade. O custo é mais esforço de engenharia e código de baixo nível, mas os ganhos de desempenho provaram valer muito a pena.
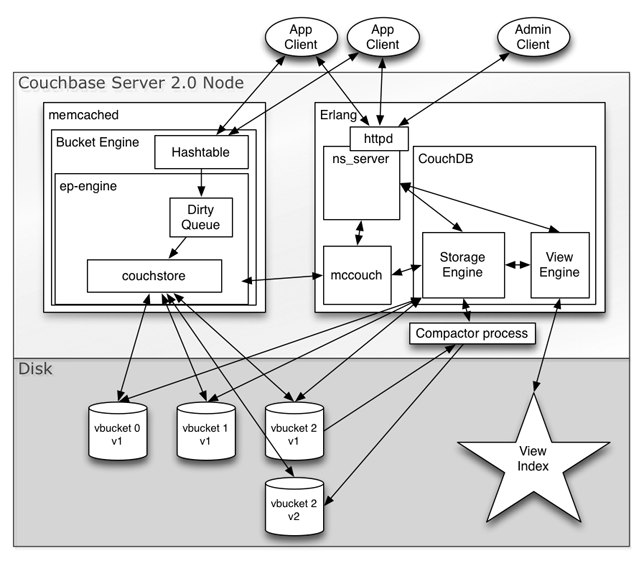
 Portanto, agora temos os mesmos mecanismos de armazenamento resistentes à fragmentação, com atualização otimista, capacidade de MVCC, orientados à recuperação, tanto em Erlang quanto em C. As leituras não bloqueiam as gravações e as gravações não bloqueiam as leituras. As gravações também ocorrem simultaneamente com a compactação. Obter todas as alterações ou alterações incrementais por meio de snapshotting MVCC e do índice by_sequence torna nosso io de disco principalmente linear para aquecimento rápido, indexação e reequilíbrios de cluster. Ele permite a indexação assíncrona e também alimenta o XDCR.
Portanto, agora temos os mesmos mecanismos de armazenamento resistentes à fragmentação, com atualização otimista, capacidade de MVCC, orientados à recuperação, tanto em Erlang quanto em C. As leituras não bloqueiam as gravações e as gravações não bloqueiam as leituras. As gravações também ocorrem simultaneamente com a compactação. Obter todas as alterações ou alterações incrementais por meio de snapshotting MVCC e do índice by_sequence torna nosso io de disco principalmente linear para aquecimento rápido, indexação e reequilíbrios de cluster. Ele permite a indexação assíncrona e também alimenta o XDCR.
B-Superstar: Mapa/Redução Incremental com reconhecimento de cluster
Outro item importante foi trazer todos os recursos importantes das visualizações de mapa/redução incremental do CouchDB para o Couchbase e combiná-los com o clustering, mantendo a consistência durante o rebalanceamento e o failover.
Começamos a usar um índice por partição virtual (vbucket), mesclando os resultados de todos os índices no momento da consulta, mas rapidamente descartamos esse projeto, pois ele simplesmente não nos traria o desempenho ou a escalabilidade de que precisávamos. Precisávamos de um sistema que suportasse varreduras de intervalo MVCC, com reduções rápidas baseadas em chaves de vários níveis (_sum, _count, _stats e reduções definidas pelo usuário), e que exigisse o mínimo possível de leituras de índice.
O que criamos usa o modelo de visualização comprovado baseado no CouchDB, o mesmo mapa/reprodução incremental em javascript, as mesmas reduções pré-indexadas e memorizadas armazenadas em nós btree internos para consultas de intervalo de baixo custo, mas pode excluir instantaneamente resultados de partições inválidas quando as partições são reequilibradas em um nó ou são parcialmente indexadas em um novo nó.
Incorporamos um índice de partição de bitmap em cada nó da btree, que é o OR recursivo de todas as reduções secundárias. Devido às atualizações do índice tail append, é uma gravação linear para atualizar os nós de folha modificados até a raiz enquanto atualiza todos os bitmaps. Agora podemos saber instantaneamente quais subárvores têm valores emitidos de um determinado vbucket.
Clique na imagem para ampliar
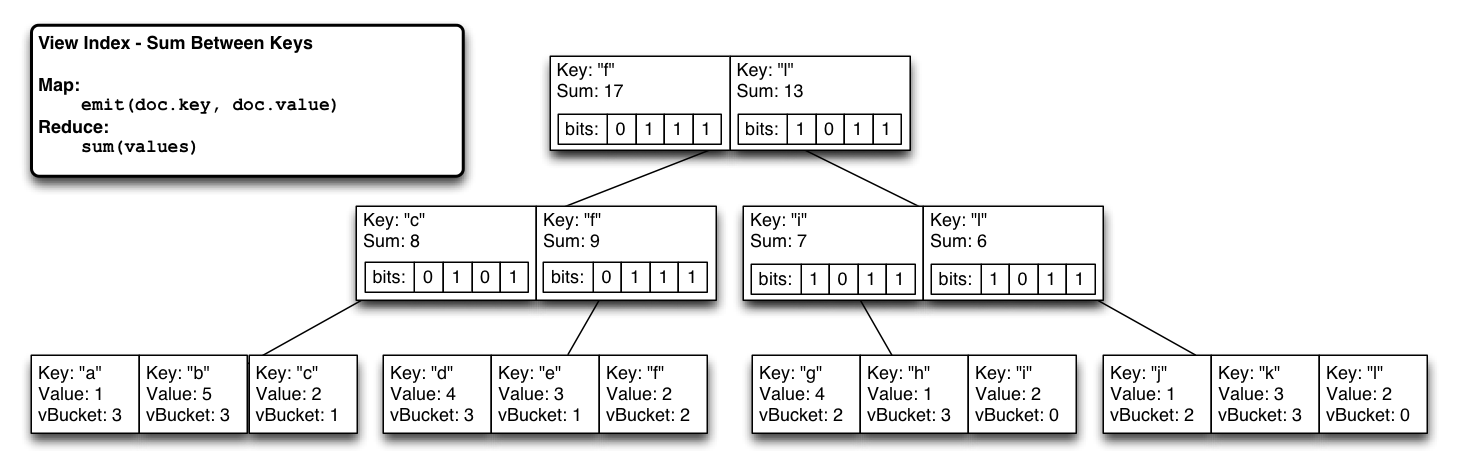
Durante o estado estável, temos um sistema que funciona com quase a mesma eficiência de nossas btrees regulares (apenas o custo extra de 1 bit por nó de btree vezes o número de partições virtuais).
Clique na imagem para ampliar
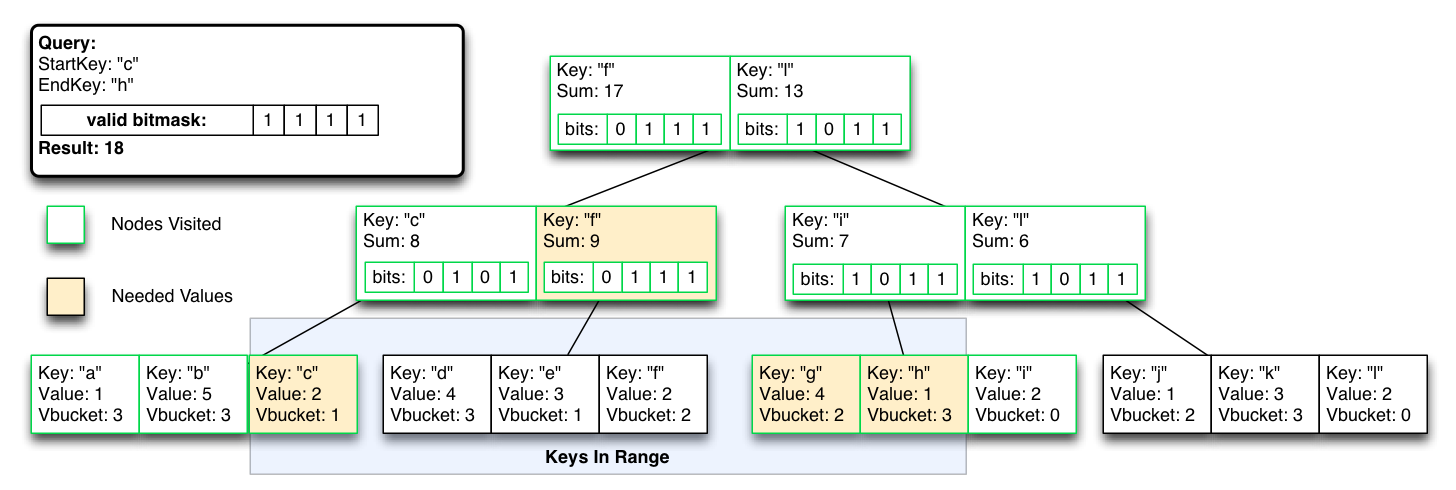
Mas pode excluir as partições do vBucket invertendo uma máscara de bit único, para reequilíbrio/consistência de failover, com custo temporário de tempo de consulta mais alto até que os índices sejam otimizados novamente.
Clique na imagem para ampliar
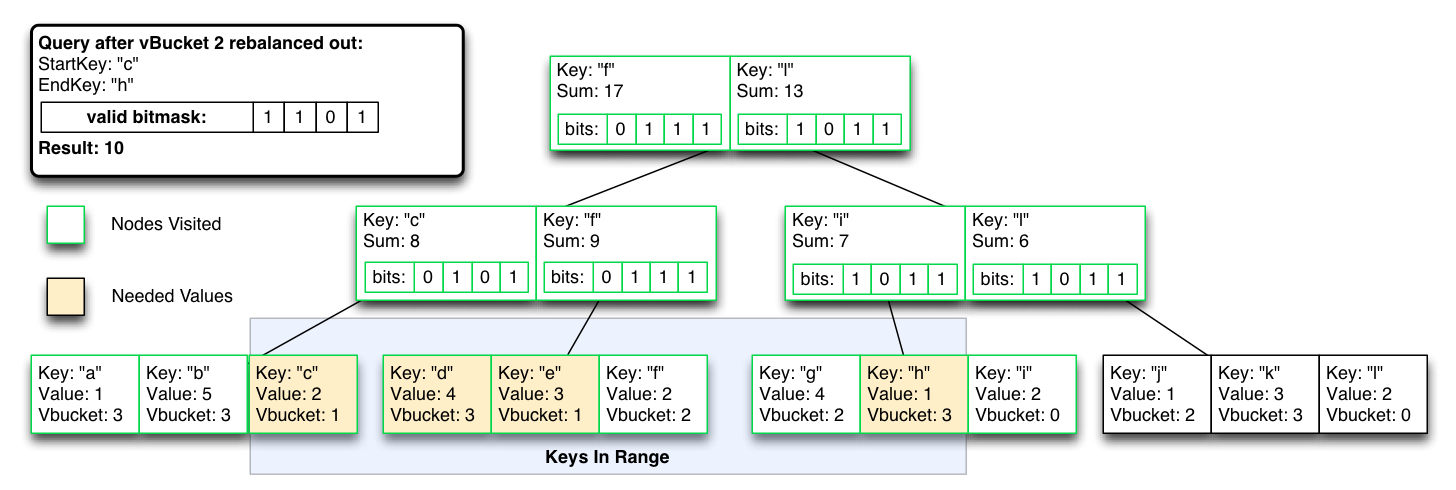
No pior caso, as operações O(logN) se tornam O(N) até que os resultados do índice excluídos sejam removidos do índice.
Clique na imagem para ampliar
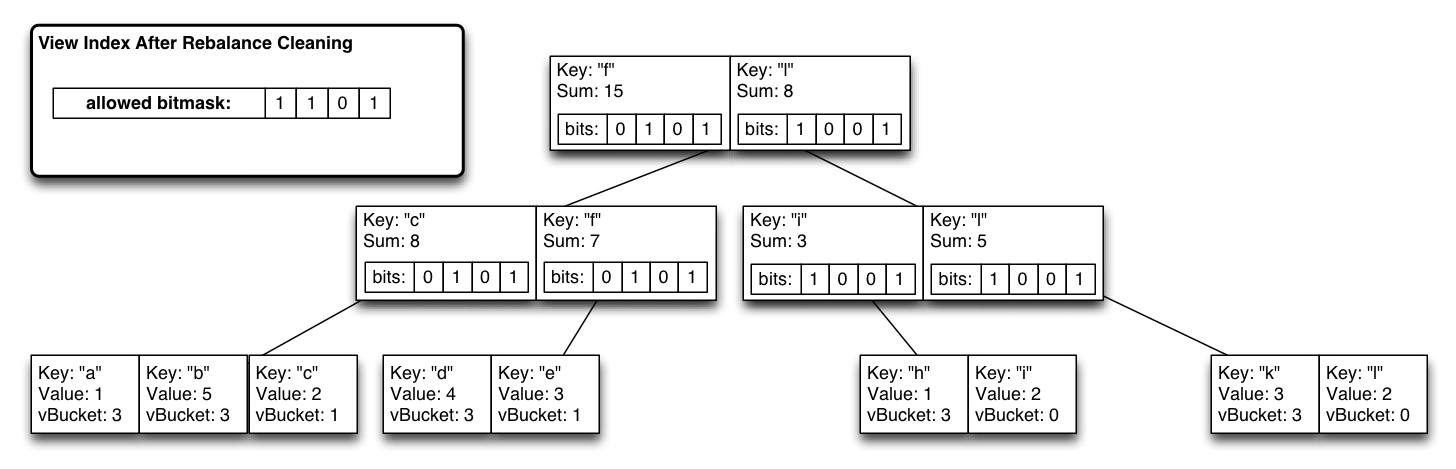
O índice é novamente o estado estável, e as consultas são 0(logN).
Clique na imagem para ampliar
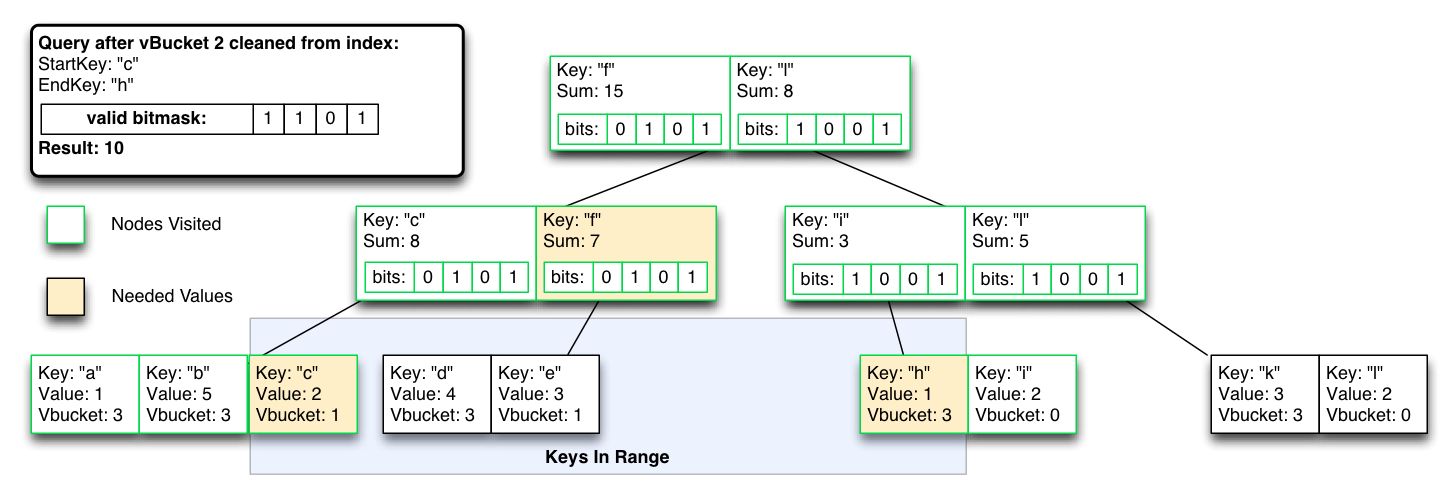
O mais interessante é que isso também funciona de forma inversa, de modo que podemos começar a inserir no índice de visualização de um novo nó do vBucket à medida que ele se reequilibra, mas excluir os resultados até que o reequilíbrio seja concluído. O resultado são índices de visualização e consultas consistentes durante o estado estável e durante o failover ou rebalanceamento ativo.
Replicação entre data centers (XDCR)
O Couchbase 2.0 também terá replicação com vários mestres e com reconhecimento de cluster. Isso permite que clusters geograficamente dispersos repliquem as alterações de forma incremental, tolerando falhas de rede transitórias e topologias de cluster independentes.
Se você tiver um único cluster e usuários geograficamente dispersos, a latência tornará mais lentos os aplicativos para usuários distantes. Quanto mais longe e quanto mais saltos de rede um usuário enfrentar, mais latência inerente ele terá. A melhor maneira de reduzir a latência para usuários distantes é aproximar os dados do usuário.
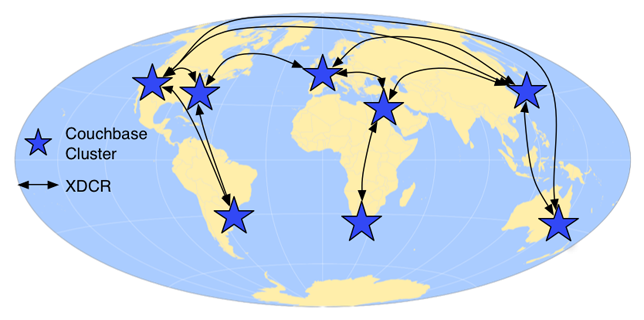
 Com o Couchbase XDCR, é possível ter clusters em vários data centers, espalhados por regiões e continentes, reduzindo consideravelmente a latência do aplicativo para os usuários dessas regiões. Os dados podem ser atualizados em qualquer cluster, replicando as alterações para clusters remotos em um cronograma fixo ou continuamente. Os conflitos de edição são resolvidos com o uso de uma regra de "mais editado", permitindo que todos os clusters convirjam para o mesmo valor.
Com o Couchbase XDCR, é possível ter clusters em vários data centers, espalhados por regiões e continentes, reduzindo consideravelmente a latência do aplicativo para os usuários dessas regiões. Os dados podem ser atualizados em qualquer cluster, replicando as alterações para clusters remotos em um cronograma fixo ou continuamente. Os conflitos de edição são resolvidos com o uso de uma regra de "mais editado", permitindo que todos os clusters convirjam para o mesmo valor.
Fundação sólida
Sinto que estamos apenas começando. Ainda há uma tonelada de detalhes e novos recursos que não mencionei, esses são apenas alguns dos destaques. Estou muito orgulhoso e empolgado não apenas com o que temos para a versão 2.0, mas com o que é possível fazer com a base rápida, confiável e flexível que construímos e com os futuros recursos e tecnologias que agora podemos desenvolver facilmente. Vejo um futuro muito brilhante.
Isso parece muito bom, pessoal. É interessante saber o que causou o atraso, e fico feliz que vocês tenham feito essa (sem dúvida) difícil escolha. Vocês poderiam compartilhar algumas métricas de desempenho?