
[This blog was syndicated from https://damienkatz.net/]
I’m glad to report we are now pretty much going into full-on stabilization and resource optimization mode for Couchbase Server 2.0. It’s taken us a lot longer than we planned. Creating a high performance, efficient, reliable, full-featured distributed document database is a non-trivial matter ;)
In addition to the same “simple, fast, elastic” memcached and clustering technology we have in previous versions of Couchbase, we’ve added 3 big new features to dramatically extend it’s capabilities and use cases, as well as its performance and reliability.
Couchstore: High Throughput, Recovery Oriented Storage
One of the biggest obstacles for 2.0 was the Erlang-based storage engine was too resource heavy compared to our 1.8.x release, which uses SQLite. We did a ton of optimization work and modifications, stripping out everything we could to make it as a fast and efficient as possible, and in the process making our Erlang-based storage code several times faster than when we started, but the CPU and resource usage was still too high, and without lots of CPU cores, we couldn’t get total system performance where our existing customers needed it.
In the end, the answer was to rewrite the core storage engine and compactor in C, using a format bit for bit compatible with our Erlang storage engine, so that updates written in one process could be read, indexed, replicated, and even compacted from Erlang. It’s the same basic tail-append, recovery oriented MVCC design, so it’s simple to write to it from one OS process and read it from another process. The storage format is immune to corruption caused by server crashes, OOM killers or even power loss.
Rewriting it in C let us break through many optimization barriers. We are easily getting 2x the write throughput over the optimized Erlang engine and SQLite engines, with less CPU and a fraction of the memory overhead.
Not all of this is due to C being faster than Erlang. A good chunk of the performance boost is just being able to embed the persistence engine in-process. That alone cut out a lot of CPU and overhead by avoiding transmitting data across processes and converting to Erlang in-memory structures. But also it’s C, which provides good low level control and we can optimize much more easily. The cost is more engineering effort and low-level code, but the performance gains have proven very much worth it.
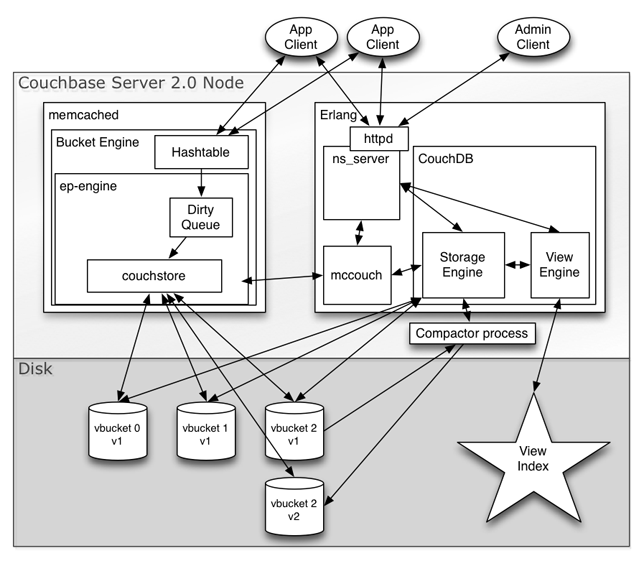
 And so now we’ve got the same optimistically updating, MVCC capable, recovery oriented, fragmentation resistant storage engines both in Erlang and C. Reads don’t block writes and writes don’t block reads. Writes also happen concurrently with compaction. Getting all or incremental changes via MVCC snapshotting and the by_sequence index makes our disk io mostly linear for fast warmup, indexing, and cluster rebalances. It allows asynchronous indexing, and it also powers XDCR.
And so now we’ve got the same optimistically updating, MVCC capable, recovery oriented, fragmentation resistant storage engines both in Erlang and C. Reads don’t block writes and writes don’t block reads. Writes also happen concurrently with compaction. Getting all or incremental changes via MVCC snapshotting and the by_sequence index makes our disk io mostly linear for fast warmup, indexing, and cluster rebalances. It allows asynchronous indexing, and it also powers XDCR.
B-Superstar: Cluster Aware Incremental Map/Reduce
Another big item was bringing all the important features of CouchDB incremental map/reduce views to Couchbase, and combining it with clustering while maintaining consistency during rebalance and failover.
We started using an index per virtual partition (vbucket), merging across all indexes results at query time, but quickly scrapped that design as it simply wouldn’t bring us the performance or scalability we needed. We needed a system to support MVCC range scans, with fast multi-level key based reductions (_sum, _count, _stats, and user defined reductions), and require the fewest index reads possible.
What we came up with uses the proven CouchDB-based view model, same javascript incremental map/reduce, same pre-indexed, memoized reductions stored in inner btree nodes for low cost range queries, yet can instantly exclude invalid partitions results when partitions are rebalanced off a node, or are partially indexed on a new node.
We embed a bitmap partition index in each btree node that is the recursive OR of all child reductions. Due to the tail append index updates, it’s a linear write to update modified leaf nodes through to root while updating all the bitmaps. Now we can tell instantly which subtrees have values emitted from a particular vbucket.
Click on the image to enlarge
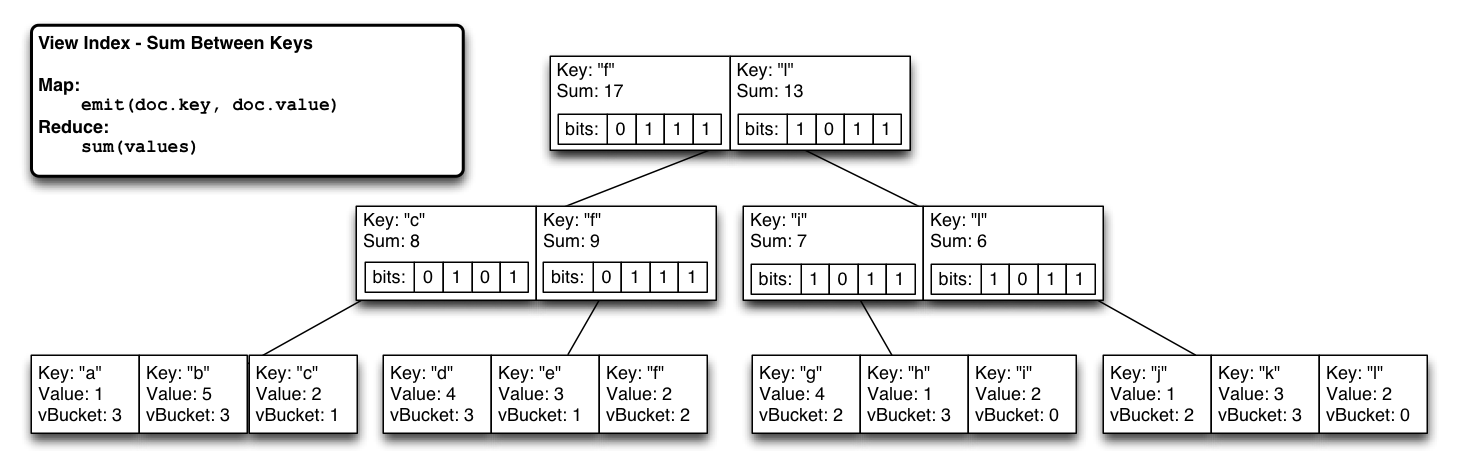
During steady state we have a system that performs with nearly the same efficiency as our regular btrees (just the extra cost of 1 bit per btree node times the number of virtual partitions).
Click on the image to enlarge
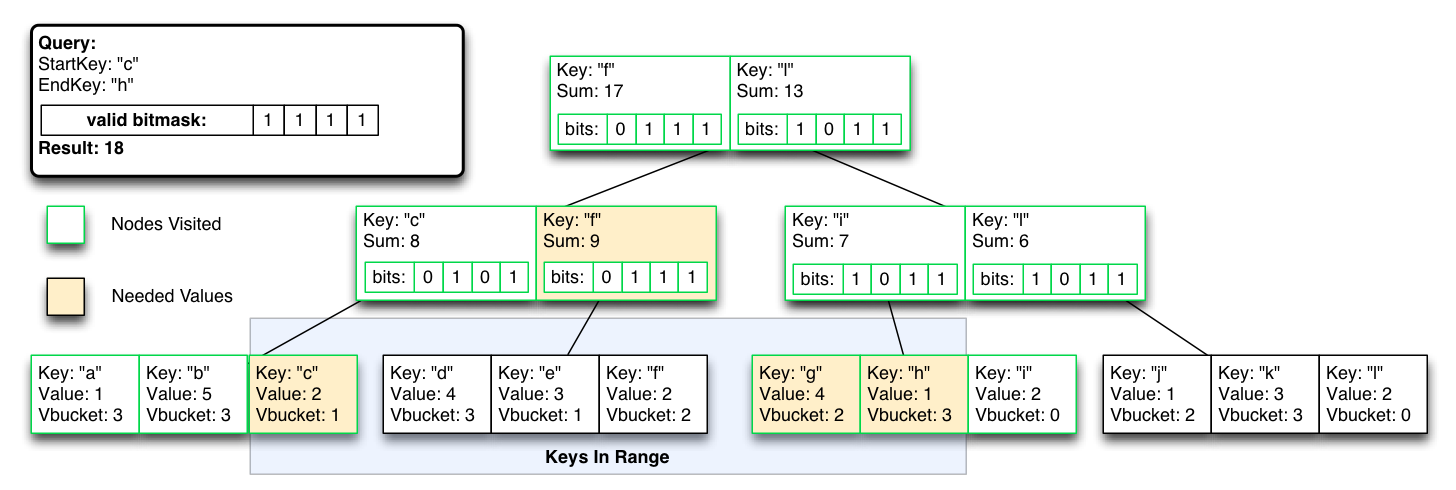
But can exclude vBucket partitions by flipping a single bit mask, for rebalance/failover consistency, with temporary higher query-time cost until the indexes are re-optimized.
Click on the image to enlarge
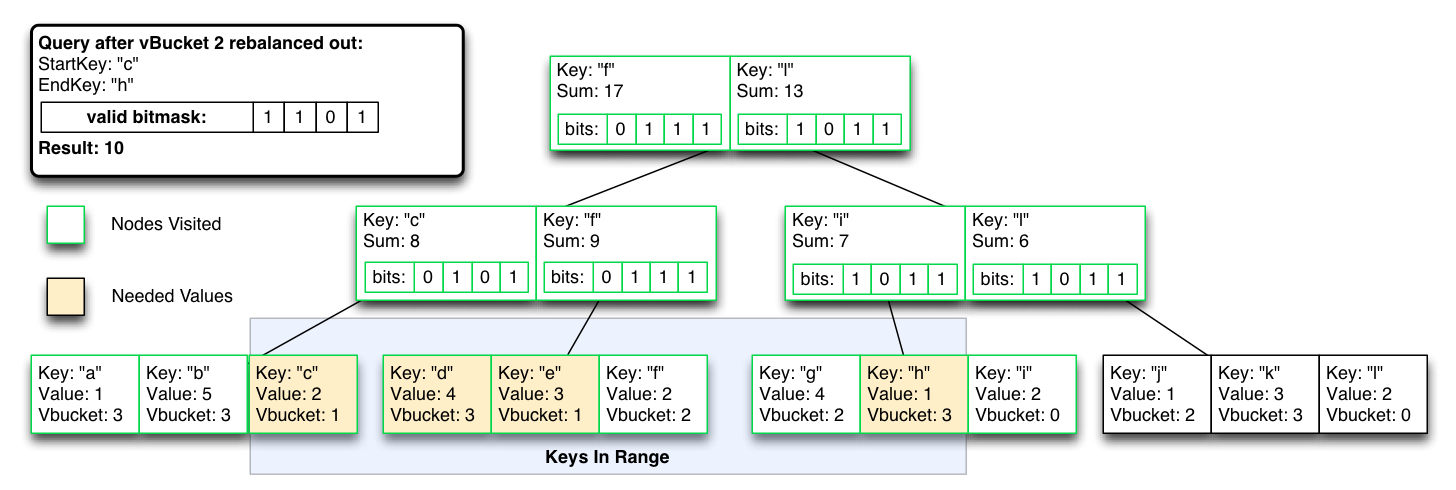
In the worst case, O(logN) operations become O(N) until the excluded index results are removed from the index.
Click on the image to enlarge
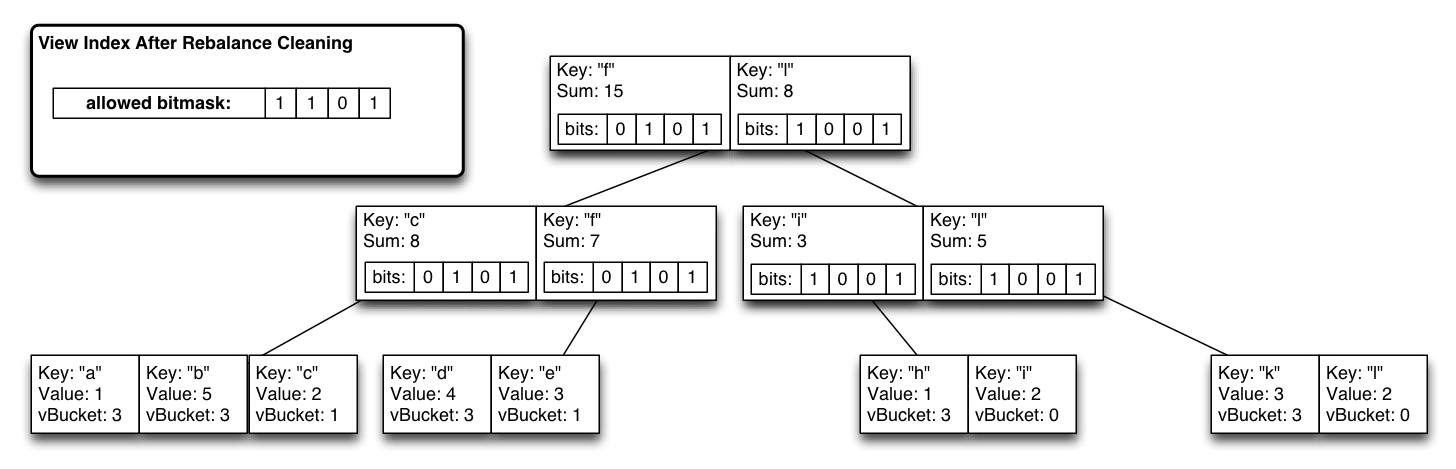
The index is once again the steady state, and queries are 0(logN).
Click on the image to enlarge
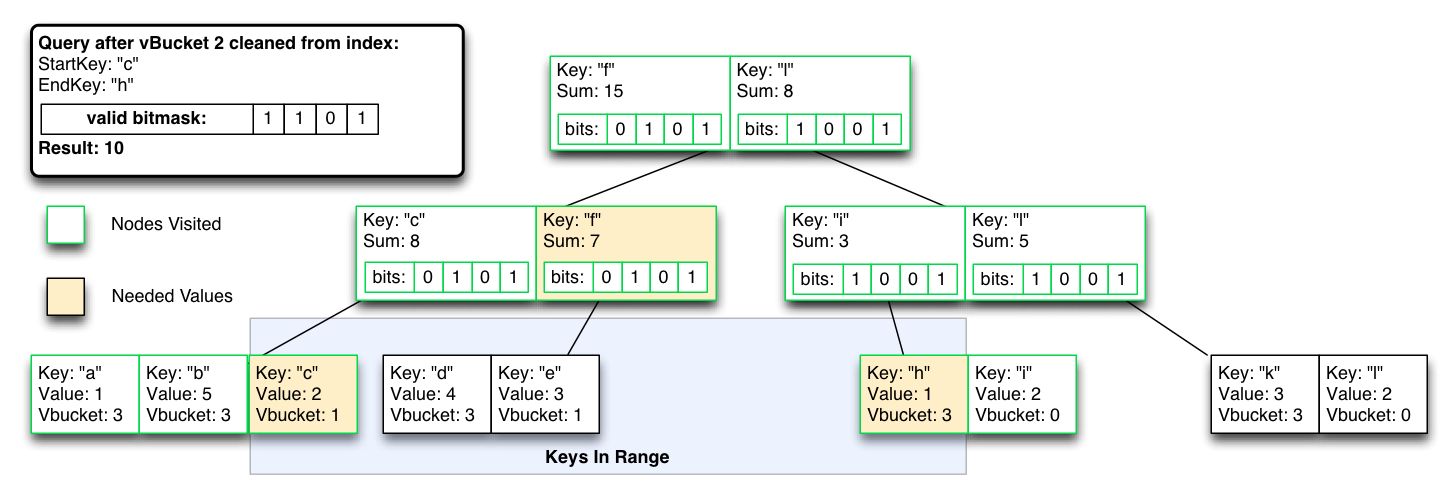
The really cool thing is this also works in reverse, so we can start inserting into a vBucket’s new node’s view index as it rebalances, but exclude the results until the rebalance is complete. The result is consistent view indexes and queries both during steady state and while actively failing-over or rebalancing.
Cross data center replication (XDCR)
Couchbase 2.0 will also have multi-master, cluster aware replication. It allows for geographically dispersed clusters to replicate changes incrementally, tolerant of transient network failures and independent cluster topologies.
If you have a single cluster and geographical dispersed users, latency will slow down applications for distant users. The further away and more network hops a user faces the more inherent latency they will experience. The best way to lower latency for far-away users is to bring the data closer to the user.
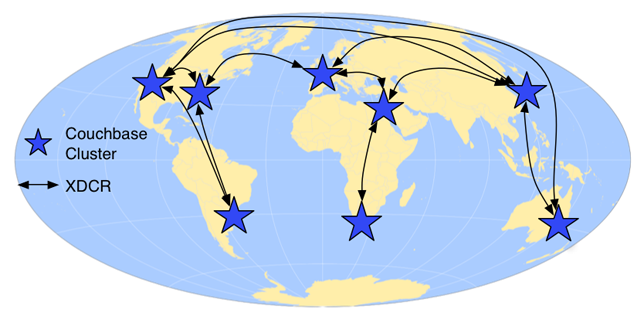
 With Couchbase XDCR, you can have clusters in multiple data centers, spread across regions and continents, greatly reducing the application latency for users in those regions. Data can be updated at any cluster, replicating changes to remote clusters either on a fixed schedule or continuously. Edit conflicts are resolved by using a “most edited” rule, allowing all clusters to converge on the same value.
With Couchbase XDCR, you can have clusters in multiple data centers, spread across regions and continents, greatly reducing the application latency for users in those regions. Data can be updated at any cluster, replicating changes to remote clusters either on a fixed schedule or continuously. Edit conflicts are resolved by using a “most edited” rule, allowing all clusters to converge on the same value.
Solid Foundation
I feel like we are just getting started. There is a still a ton of detail and new features I haven’t gone into, these are just some of the highlights. I’m really proud and excited not just by what we have for 2.0, but what’s possible on the fast, reliable and flexible foundation we’ve built and the future features and technology we can now easily build. I see a very bright future.
Author
Una respuesta
-
This sounds really good guys. It’s interesting to hear what caused the delay, and I’m glad you made that (no doubt) difficult choice. Could you guys perhaps share some performance metrics?
Deja un comentario
Lo siento, debes estar conectado para publicar un comentario.