Se você deseja migrar seus dados de um banco de dados relacional para NoSQL, então agora é um momento melhor do que nunca.
O recente lançamento do Couchbase 7.0 introduziu Scopes e Collections - uma nova maneira de organizar seus Dados JSON. Acima de tudo, os escopos e as coleções simplificam e facilitam a migração do seu modelo de dados relacional atual para o modelo de dados de documentos do Couchbase. Como resultado, sua empresa se beneficia da arquitetura distribuída sem compartilhamento do Couchbase, da alta disponibilidade e da escalabilidade horizontal.
E se você for um cliente ou usuário de longa data do Couchbase - Os escopos e as coleções têm muito a oferecer em termos de gerenciamento e organização de dados.
Mas não importa se você é novo no NoSQL ou se é um veterano do Couchbase, suas consultas ao banco de dados - usando a linguagem de consulta N1QL - se beneficiam do novo modelo de dados Scopes e Collections. Se quiser simplificar suas consultas N1QL, você precisará migrar seus dados do Couchbase do modelo antigo Bucket para o novo modelo Collections. Felizmente, a migração é um processo fácil de cinco etapas.
Vamos começar com uma revisão dos escopos e das coleções. (Ou pule direto para o guia de migração se você estiver pronto.)
Espere, o que são escopos e coleções?
Um escopo é equivalente a um esquema em um banco de dados relacional (RDBMS). Ele é um contêiner lógico para as coleções do Couchbase. Cada Bucket do Couchbase contém um escopo padrão. Você pode usar esses contêineres padrão diretamente ou definir o seu próprio.
Uma coleção é análoga a uma tabela em um RDBMS. Todo escopo tem uma coleção padrão. Enquanto uma Collection pode ser usado para armazenar tipos semelhantes de registros (como uma tabela RDBMS), não há restrições de esquema sobre o que pode ser armazenado em uma coleção. Depende inteiramente de você.
Abaixo está uma ilustração de como vários conceitos de banco de dados relacional são mapeados para esses novos recursos do Servidor Couchbase 7.0:
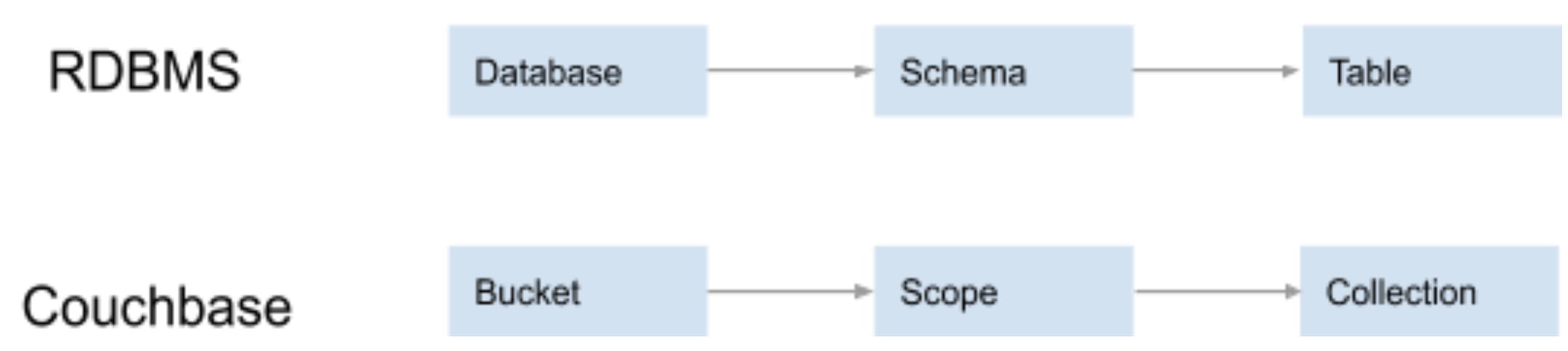
Como você pode ver, agora há um mapeamento de um para um entre os sistemas relacional e Modelos de dados NoSQL ao usar Scopes e Collections em Couchbase.
Espaços-chave do sistema em Escopos e coleções
| Espaço-chave | Descrição |
system:all_scopes |
Uma lista de todos os Escopos, incluindo objetos do sistema, como os Escopos padrão |
sistema:escopos |
Todos os Escopos disponíveis, exceto os Escopos do sistema |
system:all_collections |
Uma lista de todas as coleções, incluindo objetos do sistema, como as coleções padrão |
sistema:coleções |
Todas as coleções disponíveis, exceto as coleções do sistema |
Como os escopos e as coleções otimizam suas consultas N1QL
Uma das principais consequências de Escopos e Coleções é que a linguagem de consulta N1QL agora é mais simples. Isso ocorre porque um tipo não é mais necessário em todos os documentos. Como resultado, tanto a linguagem de definição de dados (DDL) quanto a linguagem de manipulação de dados (DML) das instruções N1QL são mais fáceis de escrever e entender.
As consultas N1QL agora são mais simples e intuitivas
As coleções do Couchbase fornecem a você o equivalente a uma tabela relacional. A força dessa semelhança - sem nenhuma de suas fraquezas - preenche a lacuna entre a lógica e a modelo de dados físicos com o qual muitos RDBMS estão acostumados.
Dê uma olhada nessas consultas N1QL lado a lado abaixo usando o amostra de viagem conjunto de dados.
| Modelo de caçamba | Modelo de coleção | ||||
|
|
A consulta nos saltos à esquerda ilustra como você teve que especificar o documento tipo no modelo antigo do Bucket. A consulta à direita é mais simples porque o documento tipo não é mais necessário no novo modelo de coleção introduzido no Couchbase 7.0.
As condições N1QL JOIN também são mais simples
Os JOINs no N1QL também ficaram mais fáceis. Dê uma olhada na comparação entre as consultas antigas e as novas abaixo.
| Modelo de caçamba | Modelo de coleção | ||||
|
|
No novo modelo de coleção, a sintaxe JOIN não exige que você use o tipo para restringir sua consulta a uma tabela específica de documentos dentro do Bucket.
As consultas N1QL mantêm a compatibilidade com versões anteriores do modelo de balde
A introdução do novo modelo Collection não significa o fim dos Buckets. O N1QL Query Service ainda suporta o modelo de Bucket como antes.
A única mudança é que agora os dados do seu Bucket são armazenados no escopo padrão que, por sua vez, contém uma coleção padrão.
| Modelo de caçamba | Modelo de coleção | ||||||
|
Você pode usar:
ou
|
Observe que o prefixo do namespace é obrigatório e deve ter o valor padrão: para todas as referências ao escopo padrão ou à coleção padrão.
Uma alteração importante nas consultas N1QL com coleções
Com o modelo Collection, o mecanismo de consulta precisa estar ciente do caminho completo do nome da coleção. Isso ocorre porque um nome de coleção não precisa ser exclusivo em um Bucket, mas apenas em seu próprio escopo.
Um nome de coleção totalmente qualificado tem o seguinte formato:
Formato:
|
1 |
namespace:bucket.scope.collection |
Exemplo:
|
1 |
namespace:`travel-sample`.booking.hotel |
No entanto, você pode fazer referência a uma coleção com seu caminho relativo, definindo o contexto_de_consulta
O Interface do usuário do Query Workbench permite que você defina o contexto da consulta selecionando o Bucket e o Scope na caixa suspensa (no canto superior direito da captura de tela abaixo).

O contexto de consulta também é suportado em SDKs do Couchbase, a API REST e concha cbq.
Tenho que migrar para as coleções?
Não, você não precisa migrar para o modelo Collections se não quiser.
Veja o que permanece igual se você optar por não migrar:
-
- Dados: Todos os dados existentes permanecem no mesmo Bucket. Você pode fazer referência aos seus documentos usando a sintaxe de consulta do Bucket ou usando o novo escopo e coleção padrão.
- Consultas: A sintaxe de consulta N1QL para DDL e DML continua sendo compatível com o modelo Bucket.
- Índices: Seus índices existentes permanecerão no nível do Bucket e continuarão disponíveis para todas as suas consultas como antes.
Migração de bucket para coleções no Couchbase 7.0
Se você estiver pronto para migrar do modelo antigo de Bucket para o novo modelo de Escopos e Coleções agora disponível no Couchbase 7.0, aqui estão as cinco etapas principais que você precisa concluir.
Para este guia de migração, usarei o amostra de viagem Bucket como um conjunto de dados de exemplo.
Etapa 1: Migração de dados
Se seus documentos já tiverem um campo para identificar seus grupos, use esses agrupamentos para criar suas coleções.
Para o amostra de viagem vamos usar o respectivo conjunto de dados tipo como os nomes das coleções. Além disso, também criaremos um inventário Escopo para todas as coleções no conjunto de dados.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE SCOPE `travel-sample`.inventory; CREATE COLLECTION `travel-sample`.inventory.route; CREATE COLLECTION `travel-sample.inventory.landmark; CREATE COLLECTION `travel-sample`.inventory.airline; CREATE COLLECTION `travel-sample`.inventory.hotel; CREATE COLLECTION `travel-sample`.inventory.airport; |
No exemplo acima, criamos um arquivo inventário Escopo e adicionou novas coleções dentro do mesmo amostra de viagem Balde.
Etapa 2: Garantir chaves de documento exclusivas
As chaves do documento precisam ser exclusivas.
A chave do documento que você tem atualmente para o(s) seu(s) Bucket(s) existente(s) já deve ser exclusiva porque todos os seus documentos existem no mesmo Bucket. Por esse motivo, sua chave de documento existente deve ser adequada para uso como a nova chave de documento da coleção.
Etapa 3: Copie seus dados
No exemplo de código abaixo, usaremos INSERT SELECT para copiar os dados do Bucket para cada coleção individual. Também usamos o META().id Chave do compartimento para a chave da coleção.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
INSERT INTO `travel-sample`.inventory.landmark (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='landmark' ; INSERT INTO `travel-sample`.inventory.airline (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='airline' ; INSERT INTO `travel-sample`.inventory.hotel (KEY k, VALUE val) ELECT META().id k, t val FROM `travel-sample` t WHERE t.type='hotel' ; INSERT INTO `travel-sample`.inventory.airport (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='airport' ; INSERT INTO `travel-sample`.inventory.route (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='route' ; |
Etapa 4: Conversão do índice
É muito provável que você precise modificar seus índices de Bucket existentes para que eles sejam eficazes com o novo modelo de Coleção.
As três subseções abaixo listam os padrões mais comuns para índices Bucket e mostram as etapas para convertê-los em um índice baseado em coleção.
Conversão de índice: Índice de Bucket com um tipo Predicate
Para um índice de Bucket com um tipo (ou seja, um índice parcial), você pode simplesmente recriar o novo índice na coleção específica para o tipo.
Compare os dois exemplos abaixo:
| Modelo de caçamba | Modelo de coleção | ||||
|
|
Conversão de índice: Índice de Bucket sem um Predicado de tipo
Você pode criar um índice Global Secondary Index (GSI) para campos que podem ou não existir no documento.
Por exemplo, um índice pode incluir o icao mas nem todo documento pode ter o campo icao campo. Para esse índice, o indexador inclui apenas os documentos que têm o campo icao nelas. Se estiver usando esse tipo de índice, talvez seja necessário ser mais específico e criar um índice para a coleção em que esse campo está sendo usado.
Novamente, compare os dois exemplos de código abaixo entre os modelos antigo e novo:
| Modelo de caçamba | Modelo de coleção | ||||
|
|
Conversão de índices: Índice de Bucket para um campo comum
Você também pode criar um índice Bucket sem especificar o tipo específico, mesmo que o campo exista em vários tipos de documentos.
Considere o exemplo em que o campo cidade existe em vários tipos de documentos - por exemplo, documentos de aeroportos, pontos de referência e hotéis. O modelo Bucket tem apenas um único def_city que pode abranger todos os três tipos de documentos. Entretanto, no novo modelo de coleção, você precisará criar um índice separado para cada coleção para esse tipo de índice.
Você pode ver as diferenças nos exemplos de código abaixo:
| Modelo de caçamba | Modelo de coleção | ||||
|
|
Etapa 5: Conversão de consulta
Como o modelo de dados subjacente mudou de um Bucket compartilhado para uma Collection individual, você precisará modificar as consultas N1QL existentes.
Além disso, depois de modificar suas consultas, você precisa verificar novamente se essas consultas usam os novos índices baseados em coleções.
Você pode ver as consultas antigas e atualizadas nos exemplos de código abaixo:
| Modelo de caçamba | Modelo de coleção | ||||||
|
A consulta reescrita sem os filtros de tipo:
|
Conclusão
É isso aí! Você terminou de migrar do antigo modelo Bucket para o novo modelo Scopes and Collections no Couchbase 7.0.
Espero que você ache o novo modelo de dados Collections mais avançado e intuitivo e que, como resultado, suas consultas N1QL sejam simplificadas e otimizadas.
Se você quiser saber mais sobre a versão 7.0 do Couchbase Server, Confira o que há de novo e/ou As notas da versão 7.0.