Durante anos, as pessoas usaram o memcached para dimensionar sites grandes. Originalmente, era usado um algoritmo de hash de seleção de módulo simples. Na verdade, ele ainda é bastante usado e é muito fácil de entender (embora seja demonstrado regularmente que algumas pessoas não o entendem de fato quando aplicado ao seu sistema completo). O algoritmo é basicamente o seguinte:
server_for_key(chave) = servidores[hash(chave) Servidores %.comprimento]
Ou seja, com um algoritmo de hash, você faz o hash da chave, mapeia-a para uma posição na lista de servidores e entra em contato com o servidor para obter essa chave. Isso é realmente fácil de entender, mas leva a alguns problemas.
- Alguns servidores têm maior capacidade do que outros.
- Os erros de cache disparam quando um servidor morre.
- Configuração frágil/confusa (coisas quebradas podem parecer funcionar)
Ignorando a ponderação (que basicamente pode ser "resolvida" adicionando o mesmo servidor várias vezes à lista), o maior problema que você tem é o que fazer quando um servidor morre ou você deseja adicionar um novoou até mesmo deseja substituir um.
Em 2007, Richard Jones e a equipe do last.fm criou uma nova maneira de resolver alguns desses problemas, chamada ketama. Essa era uma biblioteca e um método para "hashing consistente", ou seja, uma maneira de reduzir bastante a probabilidade de fazer hashing em um servidor que não tem os dados que você procura quando a lista de servidores muda.
É um sistema incrível, mas não estou aqui para escrever sobre ele, portanto não entrarei em detalhes. Ele ainda tem uma falha que o torna inadequado para projetos como base de membranaSe você não tiver uma resposta, o método do módulo é mais provável: é apenas probabilisticamente mais provável que você chegue ao servidor com seus dados. Analisando de outra forma, é quase garantido que você chegue ao servidor errado algumas vezes, mas com menos frequência do que o método de módulo descrito acima.
Uma nova esperança
No início de 2006, Anatoly Vorobey apresentou algum código para criar algo a que ele se referia como "buckets gerenciados". Esse código permaneceu lá até o final de 2008. Ele foi removido porque ele nunca foi totalmente completo, nem compreendido, e nós criamos um protocolo mais novo que facilitou a criação dessas coisas.
Estamos trazendo isso de volta, e eu vou lhe dizer por que ele existe e por que você o quer.
Primeiro, um breve resumo do que queríamos realizar:
- Nunca atenda a uma solicitação no servidor errado.
- Permitir o aumento de escala e para baixo à vontade.
- Os servidores recusam comandos que não devem atender, mas
- Os servidores ainda não sabem uns sobre os outros.
- Podemos transferir conjuntos de dados de um servidor para outro atomicamente, mas
- Não há restrições temporais.
- A consistência é garantida.
- Absolutamente nenhuma sobrecarga de rede é introduzida no caso normal.
Para expandir um pouco o último ponto em relação a outras soluções que examinamos, não há proxies, serviços de localização, conhecimento de servidor para servidor ou qualquer outra coisa mágica que exija sobrecarga. Uma solicitação com reconhecimento do vbucket não requer mais operações de rede para encontrar os dados do que para executar a operação nos dados (não é nem mesmo um byte maior).
Há outros objetivos menores, como "você deve ser capaz de adicionar servidores quando estiver sob carga de pico", mas eles são descartados gratuitamente.
Apresentando: O VBucket
Um vbucket é conceitualmente um subconjunto computado de todas as chaves possíveis.
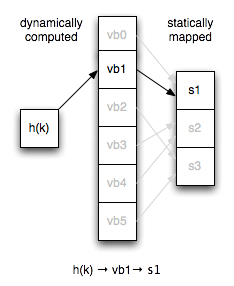
Se você já implementou uma tabela de hash, pode pensar nela como um balde de tabela de hash virtual que é o primeiro nível de hash para todas as pesquisas de nós. Em vez de mapear as chaves diretamente para os servidores, mapeamos os vbuckets para os servidores de forma estática e temos um cálculo consistente de chave → vbucket.
O número de vbuckets em um cluster permanece constante, independentemente da topologia do servidor. Isso significa que a chave x sempre mapeia para o mesmo vbucket com o mesmo hash.
As configurações de cliente precisam crescer um pouco para esse conceito. Em vez de ser uma sequência simples de servidores, a configuração agora também tem o mapeamento explícito do vbucket para o servidor.
Na prática, modelamos a configuração como uma sequência de servidores, função hash e mapa de vbuckets. Considerando três servidores e seis vbuckets (um número muito pequeno para ilustração), um exemplo de como isso funciona em relação ao código de módulo acima seria o seguinte:
vbuckets = [0, 0, 1, 1, 2, 2]
server_for_key(chave) = servidores[vbuckets[hash(chave) % vbuckets.comprimento]]
Ao ler esse código, deve ser óbvio como a introdução dos vbuckets proporciona um enorme poder e flexibilidade, mas vou continuar, caso não seja.
Terminologia
Antes de entrarmos em muitos detalhes, vamos dar uma olhada na terminologia que será usada aqui.
- Cluster:
- Uma coleção de servidores colaboradores.
- Servidor:
- Uma máquina individual em um cluster.
- vbucket:
- Um subconjunto de todas as chaves possíveis.
Além disso, um determinado vbucket estará em um dos seguintes estados em um determinado servidor:

- Ativo:
- Esse servidor está atendendo a todas as solicitações para esse vbucket.
- Morto:
- Este servidor não é de forma alguma responsável por este vbucket
- Réplica:
- Nenhuma solicitação de cliente é tratada para esse vbucket, mas ele pode receber comandos de replicação.
- Pendente:
- Esse servidor bloqueará todas as solicitações para esse vbucket.
Operações do cliente
Cada solicitação deve incluir o ID do vbucket conforme calculado pelo algoritmo de hash. Usamos os campos reservados no protocolo binário, permitindo a criação de até 65.536 vbuckets (o que é realmente muito).
Como tudo o que é necessário para escolher consistentemente o vbucket correto é que os clientes concordem com o algoritmo de hash e o número de vbuckets, é muito mais difícil configurar incorretamente um servidor de modo que você esteja se comunicando com o servidor errado para um determinado vbucket.
Além disso, com a libvbucket, tornamos a distribuição de configurações e a distribuição de configurações, a concordância com algoritmos de mapeamento e a reação a configurações incorretas um problema que não precisa ser resolvido repetidamente. O trabalho está em andamento para obter portas do libvbucket para java e .net e, enquanto isso, o moxi realizará todas as traduções para você se tiver clientes não persistentes ou não puder esperar que seu cliente favorito se atualize.
Um servidor ativo
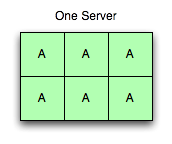
Embora as implantações normalmente tenham 1.024 ou 4.096 vbuckets, continuaremos com este modelo com seis, porque é muito mais fácil de pensar e desenhar.
Na imagem à direita, há um servidor em execução com seis buckets ativos. Todas as solicitações com todos os vbuckets possíveis vão para esse servidor, e ele responde a todas elas.
Um servidor ativo, um novo servidor
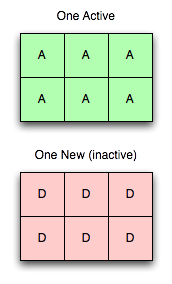
Agora vamos adicionar um novo servidor. Aqui está a primeira parte da mágica: a adição de um servidor não desestabiliza a árvore (como visto à direita).
Adicionar um servidor ao cluster, e até mesmo enviá-lo na configuração para todos os clientes, não significa que ele será usado imediatamente. O mapeamento é um conceito separado, e todos os vbuckets ainda são mapeados exclusivamente para o servidor antigo.
Para tornar esse servidor útil, transferiremos vbuckets de um servidor para outro. Para efetuar uma transferência, você seleciona um conjunto de vbuckets que deseja que o novo servidor possua e define todos eles para o estado pendente no servidor receptor. Em seguida, começamos a extrair os dados e colocá-los no novo servidor.
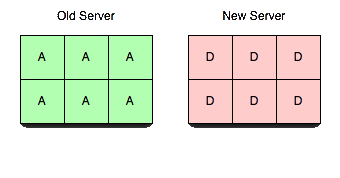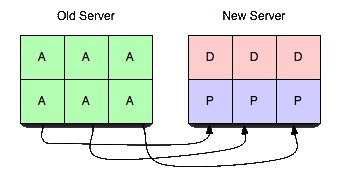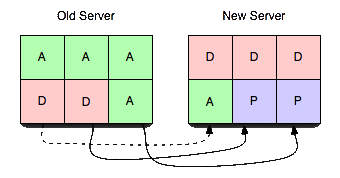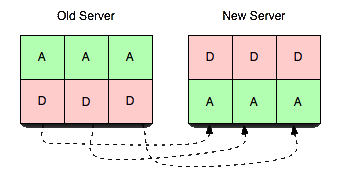 Ao executar as etapas nessa ordem exata, é possível garantir que não haja mais de um servidor ativo para um determinado vbucket em um determinado momento sem sem levar em conta a cronologia real. Ou seja, você pode ter horas de inclinação do relógio e transferências de vbucket que levam vários minutos e nunca deixar de ser consistente. Também é garantido que os clientes nunca receberão incorreto respostas.
Ao executar as etapas nessa ordem exata, é possível garantir que não haja mais de um servidor ativo para um determinado vbucket em um determinado momento sem sem levar em conta a cronologia real. Ou seja, você pode ter horas de inclinação do relógio e transferências de vbucket que levam vários minutos e nunca deixar de ser consistente. Também é garantido que os clientes nunca receberão incorreto respostas.
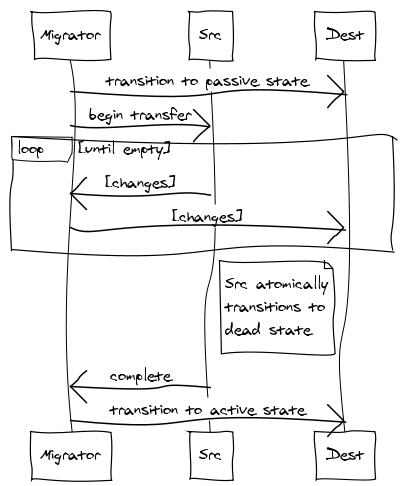
- O vbucket no novo servidor é colocado em um estado pendente.
- Uma extração do vbucket toque é iniciado.
- O fluxo de taps do vbucket define atomicamente o estado como morto quando a fila está em um estado de drenagem suficiente.
- O novo servidor só passa de pendente para ativo depois de receber a confirmação de que o servidor antigo não está mais atendendo às solicitações. Como as subseções estão sendo transferidas de forma independente, você não precisa mais se limitar a pensar em um servidor sendo transferido de cada vez, mas em uma pequena fração de um servidor sendo transferido de cada vez. Isso permite que você comece a migrar lentamente o tráfego de servidores ocupados no pico para servidores menos ocupados com um impacto mínimo (com 4.096 vbuckets em 10 servidores, cada um com 10 milhões de chaves, você estaria movendo cerca de 20 mil chaves por vez com uma transferência de vbucket ao ativar o décimo primeiro servidor).
Você pode notar que há um período de tempo em que um vbucket tem não servidor ativo. Isso ocorre no final do mecanismo de transferência e causa o bloqueio. Em geral, deve ser raro observar um cliente realmente bloqueado na natureza. Isso só acontece quando um cliente recebe um erro do servidor antigo indicando que ele terminou de preparar a transferência e pode chegar ao novo servidor antes que o novo servidor receba o último item. Então, o novo servidor só bloqueia o cliente até que esse item seja entregue e o vbucket possa fazer a transição de pendente para ativo Estado.
Embora o vbucket no servidor antigo vá automaticamente para o morto Quando o estado está suficientemente avançado, ele não excluir dados automaticamente. Isso é feito explicitamente após confirmação de que o novo nó foi ativado ativo. Se o nó de destino falhar em qualquer ponto antes de definirmos ativoSe o servidor antigo não for usado, podemos simplesmente abortar a transferência e deixar o servidor antigo ativo (ou definir de volta para ativo se estivéssemos suficientemente adiantados).
O que está acontecendo com a réplica do Estado?
A HA é muito mencionada, por isso fizemos questão de abordá-la. A réplica O vbucket é semelhante a um morto O vbucket é assim do ponto de vista de um cliente normal. Ou seja, todas as solicitações são recusadas, mas os comandos de replicação são permitidos. Isso também é semelhante ao pendente no sentido de que os registros são armazenados, mas contrastam no sentido de que os clientes não bloqueiam.
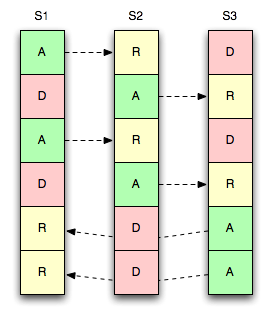
Considere a imagem à direita, onde temos três servidores, seis vbuckets e uma única réplica por vbucket.
Assim como os mestres, cada réplica também é mapeada estaticamente, de modo que pode ser movida a qualquer momento.
Neste exemplo, replicamos o vbucket para o "próximo" servidor da lista, ou seja, um ativo vbucket em S1 replica para um réplica balde em S2 - o mesmo para S2 → S3 e S3 → S1.
Várias réplicas
Também permitimos que as estratégias tenham mais de uma cópia de seus dados disponíveis nos nós.
O diagrama abaixo mostra duas estratégias para que três servidores tenham uma réplica ativa e duas réplicas de cada bucket.
1:n Replicação
A primeira estratégia (1:n) refere-se a um mestre que atende a vários escravos ao mesmo tempo. O conceito aqui é familiar para qualquer pessoa que tenha lidado com software de armazenamento de dados que permita várias réplicas.
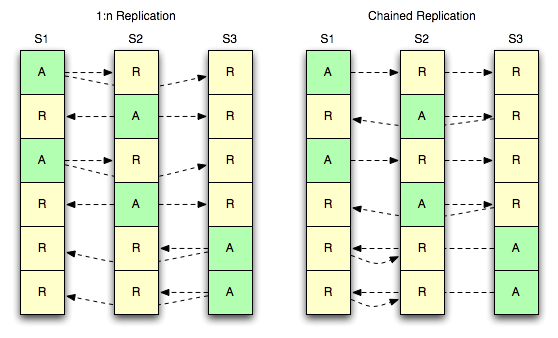
Replicação encadeada
A segunda estratégia (acorrentado) refere-se a um único mestre que atende a apenas um único escravo, mas esse escravo tem um outro escravo downstream próprio. Isso oferece a vantagem de ter um único fluxo de eventos de mutação saindo de um servidor e, ao mesmo tempo, manter duas cópias de todos os registros. Isso tem a desvantagem de compor a latência de replicação à medida que você percorre a cadeia.
É claro que, com mais de duas cópias adicionais, você pode misturá-las de modo a fazer um único fluxo a partir do mestre e, em seguida, fazer com que o segundo elo da cadeia faça um 1:n para outros dois servidores.
Tudo depende de como você mapeia as coisas.
Agradecimentos
Agradecimentos a Dormir por ajudar a decifrar o código, a intenção e os fluxos de trabalho originais do "balde gerenciado", e Jayesh Jose e aos outros funcionários da Zynga por terem descoberto isso de forma independente e trabalhado em vários casos de uso.
Fantástica postagem no blog. Ajudou-me a entender muitos conceitos básicos sobre clientes inteligentes, vBuckets e estados de vBuckets.
Pergunta: Como evitar que as chaves sejam enviadas para o mesmo servidor após o hash?