Ultimamente, há muito burburinho em torno do armazenamento de classe empresarial. A Pure Storage, líder reconhecida no setor, recentemente nos deu a oportunidade de implantar o Couchbase em um de seus ambientes de laboratório. O cluster de 8 nós foi capaz de sustentar facilmente uma carga de trabalho de 1 milhão de operações/segundo com 100% de gravação. Uma carga de trabalho de 1.000.000 de gravações/segundo foi gerada usando nossa ferramenta pillowfight executada em um dos nós do cluster com os seguintes parâmetros:
Essa carga de gravação sustentada de 1 milhão de gravações por segundo do cluster tem a seguinte aparência:

Essa carga de trabalho, embora impressionante, não exercitou nem um pouco a matriz de armazenamento. De fato, foi difícil localizar muita carga no Pure Dashboard. O motivo disso é que, com o pillowfight, utilizamos exclusivamente um documento de 64 bytes. É uma carga de trabalho perfeitamente razoável quando se considera um caso de uso da Internet das coisas com muitas chaves/valores pequenos gravados em alta velocidade. E quanto a um caso de uso de armazenamento de perfil de usuário? Qual seria o desempenho de uma carga de trabalho de gravação 100% de alta velocidade nesse ambiente usando um aplicativo do mundo real e dados de perfil de usuário com estilo realista?
Chicote de teste
Para esse aplicativo, é necessário um gerador de carga e um conjunto de testes de rápida implantação, e o node.js é a plataforma perfeita. O código-fonte está disponível em github . Primeiro, é necessário um objeto de camada de dados com um método de criação:
var ponto final=“10.21.16.121:8091”;
var agrupamento = novo couchbase.Aglomerado(ponto final);
var db = agrupamento.openBucket("usuário",função (erro) {
se (erro) {
console.registro('=>ERRO DE CONEXÃO DO BANCO DE DADOS:', erro);
}
});
função criar(chave, item){
db.upsert(chave, item, função(erro, resultado){
se(erro){
}mais {
}
});
}
Em seguida, é necessária uma maneira de criar usuários. A utilização da maravilhosa biblioteca "faker.js" para criar usuários simplifica essa tarefa. Usar o faker para criar um usuário é incrivelmente simples, e há funções auxiliares que abstraem ainda mais essa funcionalidade. Ao criar um simples loop for, os usuários são criados com faker e passados para a camada de dados descrita acima:
para(i=0;i<limite;i++){
var u=falsificador.ajudantes.Cartão de usuário();
conexão.db.criar(u.e-mail,u);
}
}
É necessário um loop de controle para realizar a ingestão no Couchbase:
checkOps(função(feito){
console.registro(feito);
se (parseInt(feito, 10) < limite) {
loadTextUserProfile(testBatch);
console.registro("INGEST:Added:",testBatch);
}
mais {
console.registro("INGEST:Busy:", feito);
}
});
}, intervalo de teste
);
O loop de controle faz uso da lógica de limitação, que é um recurso interessante para qualquer tipo de teste de desempenho e análise de estresse. Essa função chama o endpoint de repouso em um nó do cluster e verifica quantas operações por segundo o cluster está processando no momento:
http.obter("http://" + ponto final + "/pools/default/buckets/user", função (res) {
var dados=“”;
res.setEncoding('utf8');
res.em("dados, função (pedaço) {
dados += pedaço;
});
res.em("fim,função(){
var analisado=JSON.analisar(dados);
opsV(analisado.Estatísticas básicas.opsPerSec);
});
});
}
Resultados
Assim como no caso de uso da Internet das coisas, os resultados de desempenho do armazenamento de perfis de usuários foram impressionantes. Em um curto período de tempo, conseguimos gerar cerca de 500 milhões de usuários, com uma carga de trabalho contínua de 400.000 gravações por segundo.
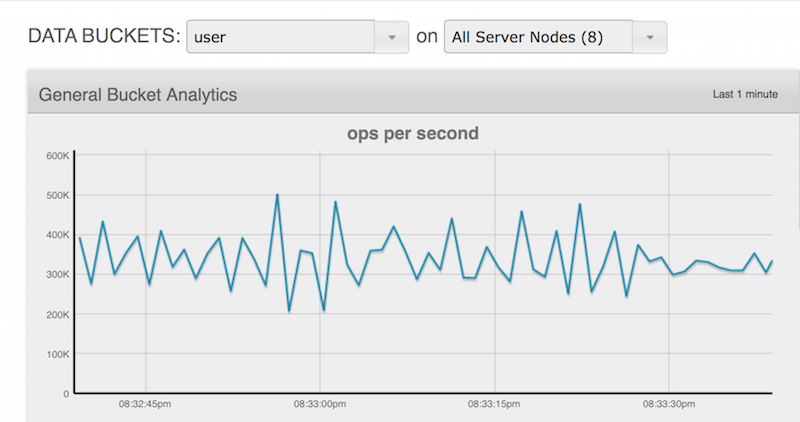
Apenas para manter as coisas interessantes, usamos o despejo total e ajustamos a memória para ser aproximadamente 10% do tamanho final do conjunto de dados.

O sistema Pure funcionou perfeitamente. Atingimos os limites de processamento da CPU muito antes de o sistema de armazenamento ficar sem espaço livre:
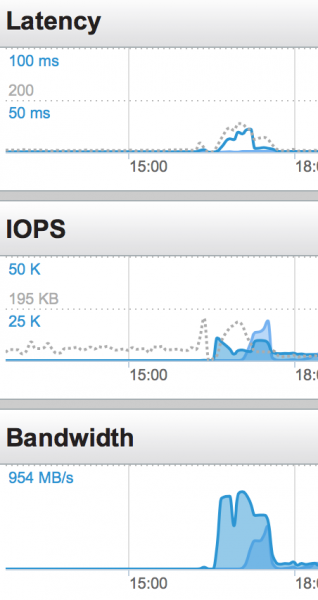
Ainda mais impressionante do que o desempenho da carga de trabalho em si, é o espaço ocupado pelo armazenamento. Esse é um dos aspectos mais difíceis do armazenamento em um sistema distribuído. A tecnologia de desduplicação da Pure é excepcional.

Usando uma granularidade de 512 bytes, uma precisão quatro vezes mais fina do que a dos sistemas concorrentes, a Pure é capaz de desduplicar com eficiência uma carga de trabalho realmente desafiadora. Em nosso ambiente de teste que gera usuários com faker, os dados são aleatórios e distribuídos uniformemente. Em uma carga de trabalho do mundo real, espera-se que a desduplicação seja ainda melhor. Com o conjunto de dados de usuários aleatórios, observamos uma desduplicação consistente de 1,6 para 1, com 1 réplica do Couchbase ativada. Esperamos fazer mais benchmarking com a tecnologia da Pure no futuro e estamos animados com o desempenho do Couchbase usando seu sistema.