Os cientistas de dados adoram os notebooks Jupyter - e faz uma combinação natural com o banco de dados de documentos do Couchbase.

Por quê? A Bloco de notas Jupyter O aplicativo da Web permite criar e compartilhar documentos que contêm texto narrativo, equações e similares para casos de uso como visualização de dados e aprendizado de máquina. Couchbase permite que você armazene e processe grandes quantidades de dados (semiestruturados e não estruturados) em escala e ofereça suporte aos tipos de dados dos quais o mundo está cheio: texto narrativo (publicações em mídias sociais etc.), equações e muito mais.
Nesta publicação, você aprenderá a estabelecer a conectividade entre um cluster do Couchbase e um Jupyter Notebook e, em seguida, extrair dados do Couchbase e usá-los para treinar um modelo de regressão linear para aprendizado de máquina. Examinaremos um exemplo para prever o valor de uma variável-alvo usando variáveis categóricas por meio de uma equação de regressão linear.
Carregando seus dados
Para começar, siga estas etapas para carregar o conjunto de dados de amostra:
- No Admin Console do cluster do Couchbase, vá para Buckets > Add Bucket para criar um novo bucket, conforme mostrado aqui:
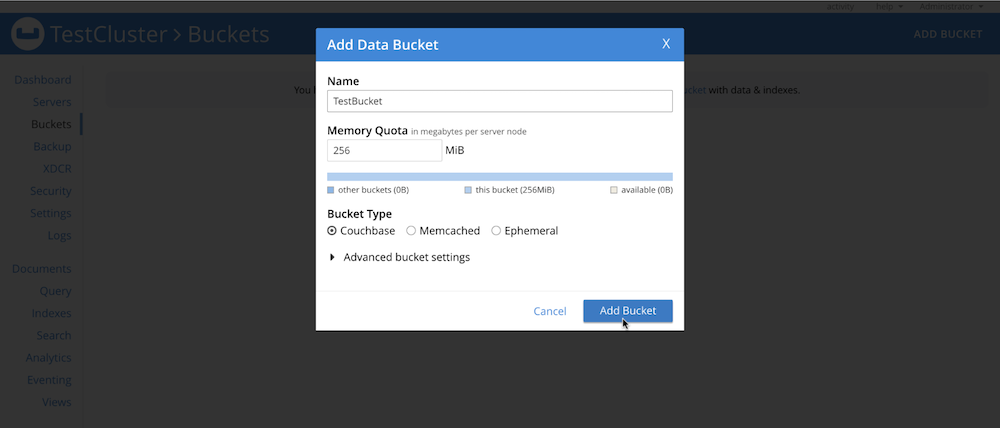
-
Adicione documentos ao seu compartimento navegando até Documents > Add Document (Documentos > Adicionar documento), assim:
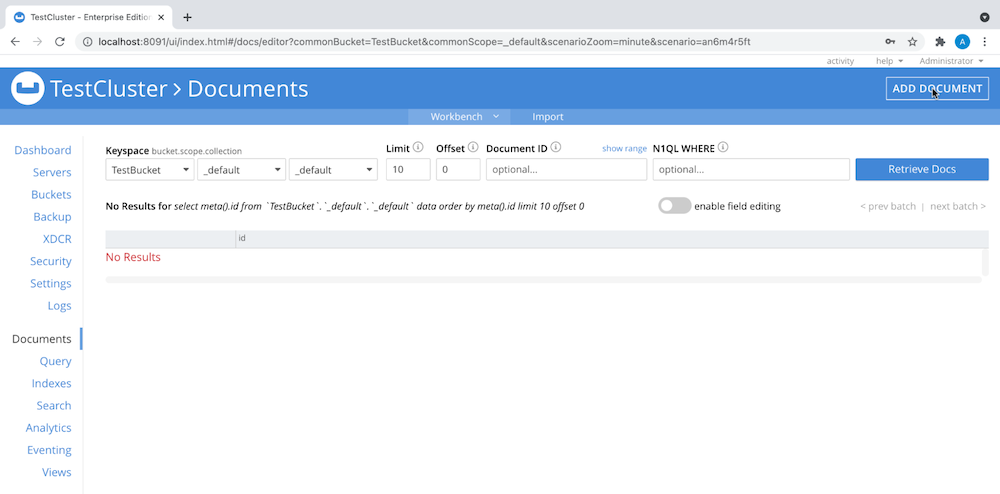
ou fazer upload de uma lista de documentos JSON ou de um arquivo CSV. Para este exemplo, faremos upload de um arquivo CSV usando
cbimport. Este é o aspecto do meu documento: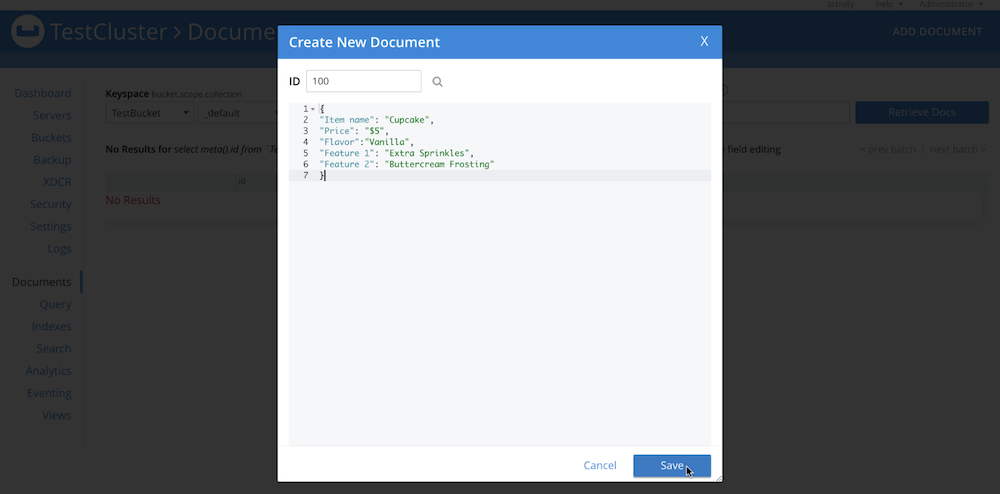
- O arquivo pode ser qualquer dado com o qual você queira trabalhar. Este exemplo usa o arquivo Conjunto de dados de publicidade do Kaggle.
- Vá para Documents > Import, conforme mostrado aqui:
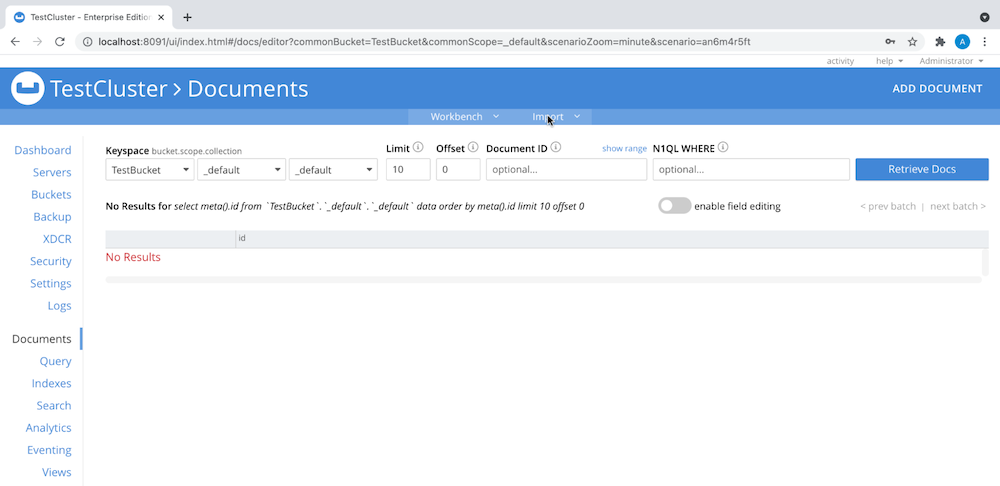
-
Selecione o arquivo que deseja importar e o intervalo de dados onde os documentos residem:
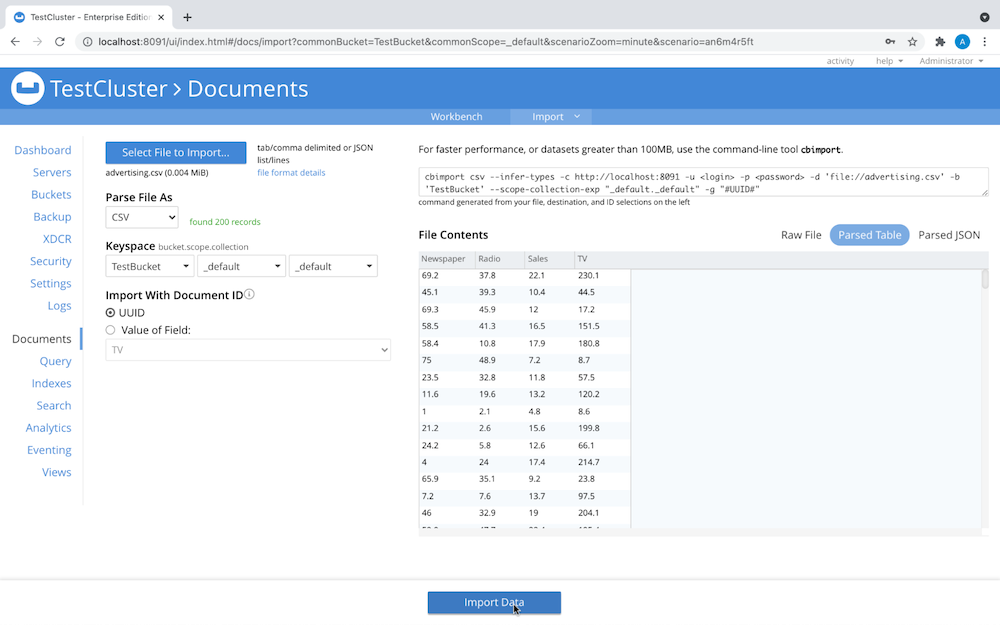
Seu menu Documentos agora deve ter a seguinte aparência:
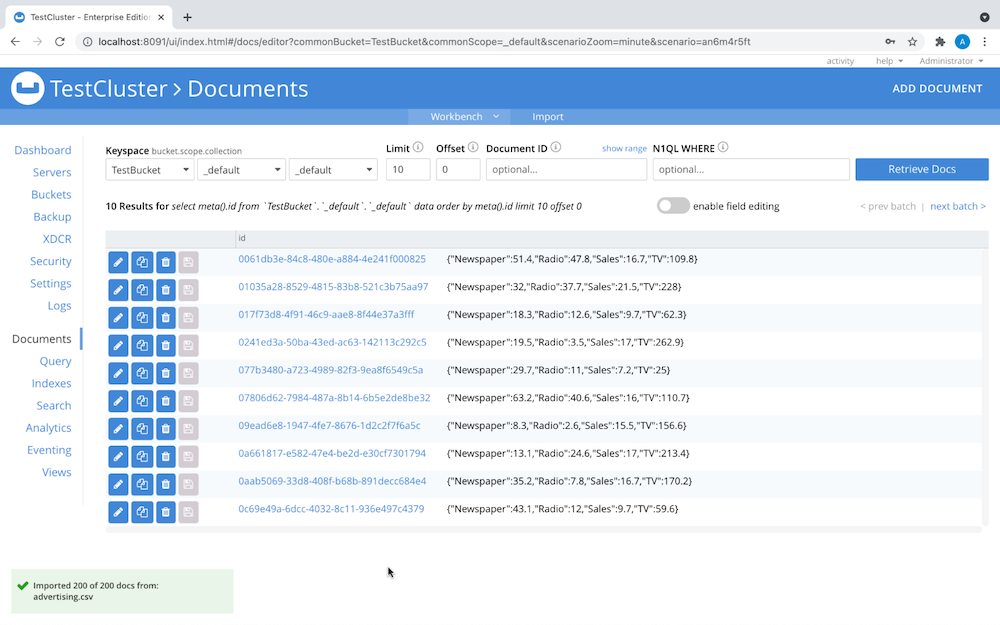
- No Admin Console, crie um índice primário para o bucket de dados para tornar os dados consultáveis, como você vê aqui:
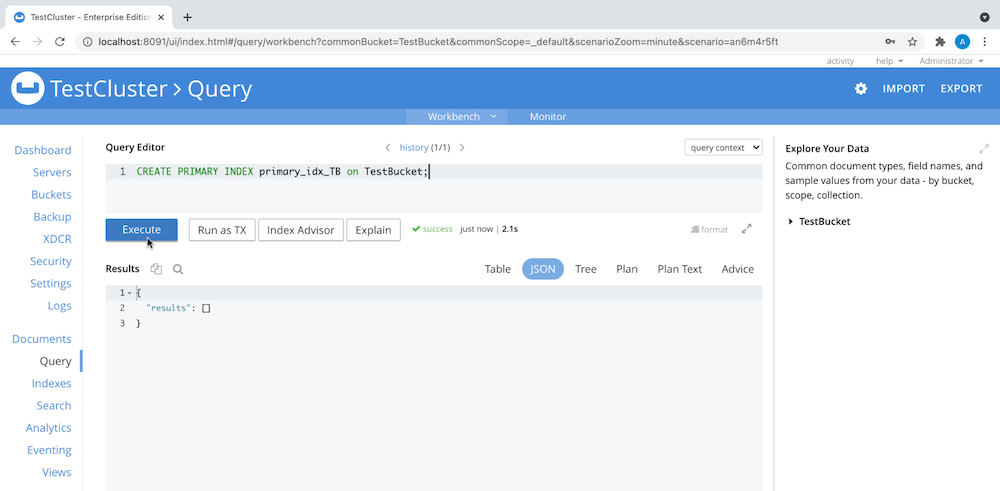
Instalando o Jupyter Notebook
Em primeiro lugar, Faça o download do exemplo do couchbase-jupyter do repositório do GitHub do Couchbase Labs. Em seguida, siga estas etapas:
- Instalar o Jupyter Notebook por meio do sistema de gerenciamento de pacotes Python (
tubulação) ou Anaconda. - Instale as dependências para esse projeto usando
tubulaçãodorequisitosem seu shell:
1$ pip install -r requirements.txt - Abra o Jupyter Notebook no shell.
- Crie um novo notebook com Python 3, como mostrado aqui:
O que é um modelo de regressão linear?
O modelo de regressão linear é poderoso para a análise preditiva, permitindo determinar a força das variáveis categóricas ou independentes, prever o efeito dessas variáveis e identificar tendências nos dados.
Como você pode deduzir pelo nome regressão linearSe a equação de regressão for uma linha, a "curva" que usamos para ajustar os dados é uma linha. A forma mais simples da equação de regressão é y = mx + c, onde y representa a variável-alvo, x representa uma única variável categórica e m e c são constantes. Usaremos uma equação de regressão linear simples em nosso exemplo.
As variáveis categóricas em nosso exemplo são TV, Rádio e Jornal. A variável alvo é Vendas.
Treinamento do nosso modelo de regressão linear
- No novo Jupyter Notebook, use o código mostrado abaixo para se conectar ao servidor Couchbase. Use seu nome de usuário e senha, é claro, em vez de
Administradore123456.

- Importe as bibliotecas necessárias, mostradas na captura de tela aqui. Se essas bibliotecas não estiverem presentes em seu ambiente, faça o download das versões mais recentes dessas bibliotecas para o ambiente correto usando o gerenciador de pacotes Python,
tubulação.

- Usando o
SELECIONARbusque os dados do seu bucket de dados em um quadro de dados do pandas:

- Você pode visualizar o conteúdo do quadro de dados do pandas usando o comando
describe()como mostrado aqui:
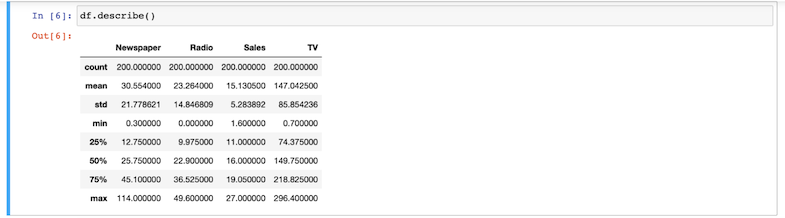
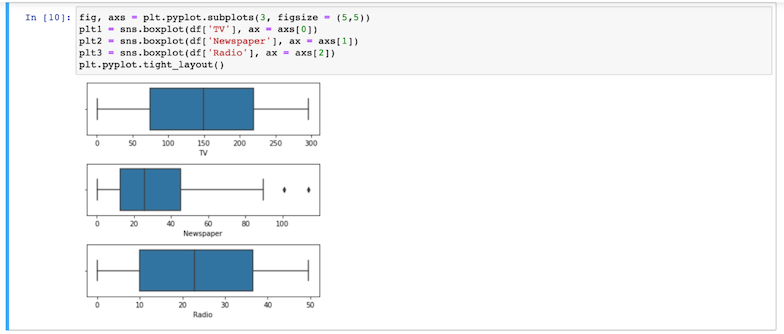
- Crie boxplots correspondentes aos valores de cada variável categórica para detectar valores discrepantes:
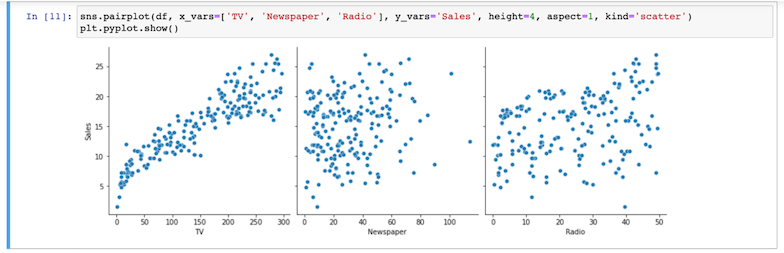
- Crie gráficos de dispersão para cada variável categórica em relação à variável-alvo para determinar o grau de correlação.
Observe queTVparece ter o mais alto grau de correlação.
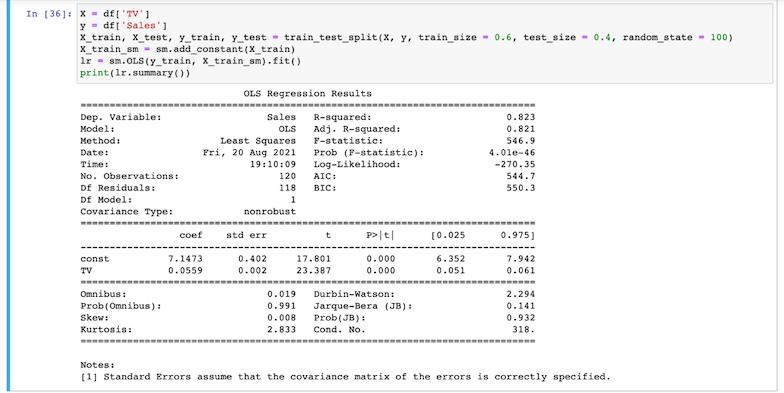
- Divida o conjunto de dados, usando 60% dele para treinamento e os 40% restantes para teste. Agora podemos determinar o valor dos coeficientes na equação de regressão, quando a variável categórica é
TVe a variável de destino éVendas, usando o Método dos mínimos quadrados ordinários.
- Agora, treine o modelo usando o código que você vê aqui:
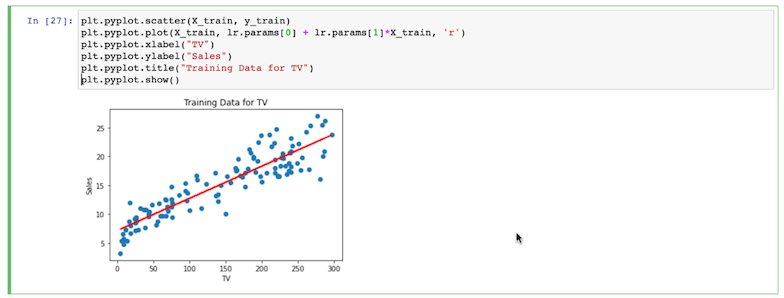
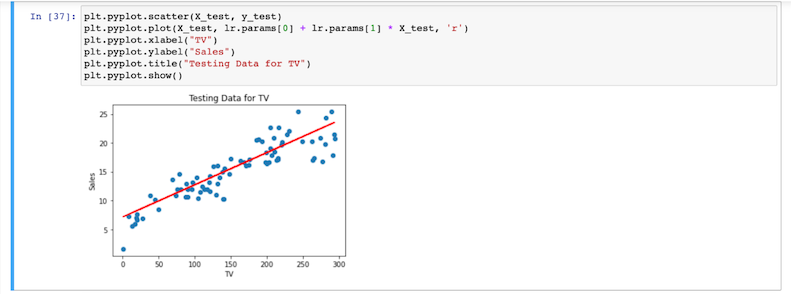
- Em seguida, substitua
testeparatrempara usar o modelo para prever os valores do conjunto de teste, assim:
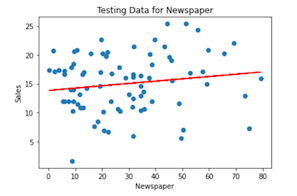
Usando a mesma abordagem, podemos treinar e testar um modelo com as variáveis categóricas Rádio e Jornaltambém:

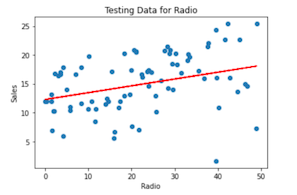
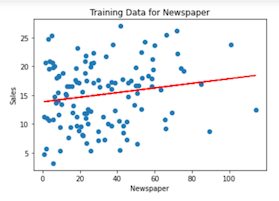
Indo além com o aprendizado de máquina e o Couchbase
Agora que você já se familiarizou com a conexão Servidor Couchbase ao Jupyter Notebook e explorou o conceito de aprendizado de máquina da regressão linear, desenvolva esse conhecimento com estas postagens sobre como usar o Couchbase como um armazenamento de modelos de aprendizado de máquina e possibilitando insights orientados por IA usando o Couchbase.
