Com o Couchbase 7.0, agora você pode permitir a integração de UDFs do Python com o Couchbase Analytics. Em Parte 1 desta série do blogNa seção "Como configurar o Couchbase", abordamos os aspectos essenciais para configurar o Couchbase e o Analytics for Machine Learning (ML).
O ML transformou radicalmente as maneiras pelas quais as organizações entendem as necessidades de seus clientes. Os domínios de análise avançada, como a análise preditiva (rotatividade de clientes, sentimento do cliente etc.) e a modelagem financeira, estão cada vez mais dependentes do processamento de dados em escala, quase em tempo real, e da extração de insights valiosos.
Para ajudar nossos clientes a obter insights analíticos em tempo real, criamos um pipeline contínuo de modelos de aprendizado de máquina baseados em Python para o Couchbase Analytics. Nesta postagem, eu passo pelas etapas a seguir para mostrar a você como aplicar algoritmos externos a dados residentes no Couchbase.
Seis etapas para aplicar modelos de ML em seus dados NoSQL:
- Treinar o modelo
- Codificar o modelo
- Empacotar e implantar o código
- Importar os dados necessários para este projeto
- Escrevendo o UDF
- Usando o UDF em sua instância para o CB (Modo DP)
Antes de começarmos, vamos encontrar um conjunto de dados que será uma demonstração interessante dos recursos que estamos criando. Há resenhas de filmes em vários sites diferentes, mas para ter uma compreensão holística das resenhas dos críticos, não há lugar melhor do que o Rotten Tomatoes. Esse site permite comparar as classificações dadas por usuários comuns (pontuação do público) e as classificações ou resenhas dadas pelos críticos (tomatômetro) que são membros certificados de várias corporações de escritores ou associações de críticos de cinema.
Os dois conjuntos de dados usados para este blog podem ser encontrados em kaggle.com. Esses arquivos são bastante grandes, portanto, um link para eles é fornecido para que você possa baixá-los quando estiver acompanhando.
No filmes cada registro representa um filme disponível no Rotten Tomatoes, com o URL usado para extrair o título do filme, a descrição, os gêneros, a duração, o diretor, os atores, as classificações dos usuários e as classificações dos críticos. No críticas de filmes cada registro representa uma resenha crítica publicada no Rotten Tomatoes, com o URL usado para extrair o nome do crítico, a publicação da resenha, a data, a pontuação e o conteúdo.
Treinamento do modelo de ML
Antes de começar a explorar o poder da integração entre ML e NoSQL, você precisará desenvolver e treinar um modelo de aprendizado de máquina em Python.
Para os fins deste blog, usaremos um modelo simples de regressão logística que utiliza a biblioteca scikit-learn. Em sua essência, o modelo recebe dados e analisa seus sentimentos em relação às críticas de filmes. Você pode seguir as etapas descritas abaixo ou fazer o download de todos os arquivos necessários em nosso Repositório do GitHub.
Para este blog, estamos usando um algoritmo preditivo de código aberto no conjunto de dados de resenhas de filmes para determinar o sentimento, ou seja, para determinar se as resenhas são positivas ou negativas para um determinado filme. Nos exemplos de hoje, já treinamos o modelo usando um subconjunto do arquivo que você baixou anteriormente. Para os fins deste blog, utilizamos um arquivo CSV (valores separados por vírgula) para importar nossos dados.
Abaixo está um exemplo do código do próprio modelo:
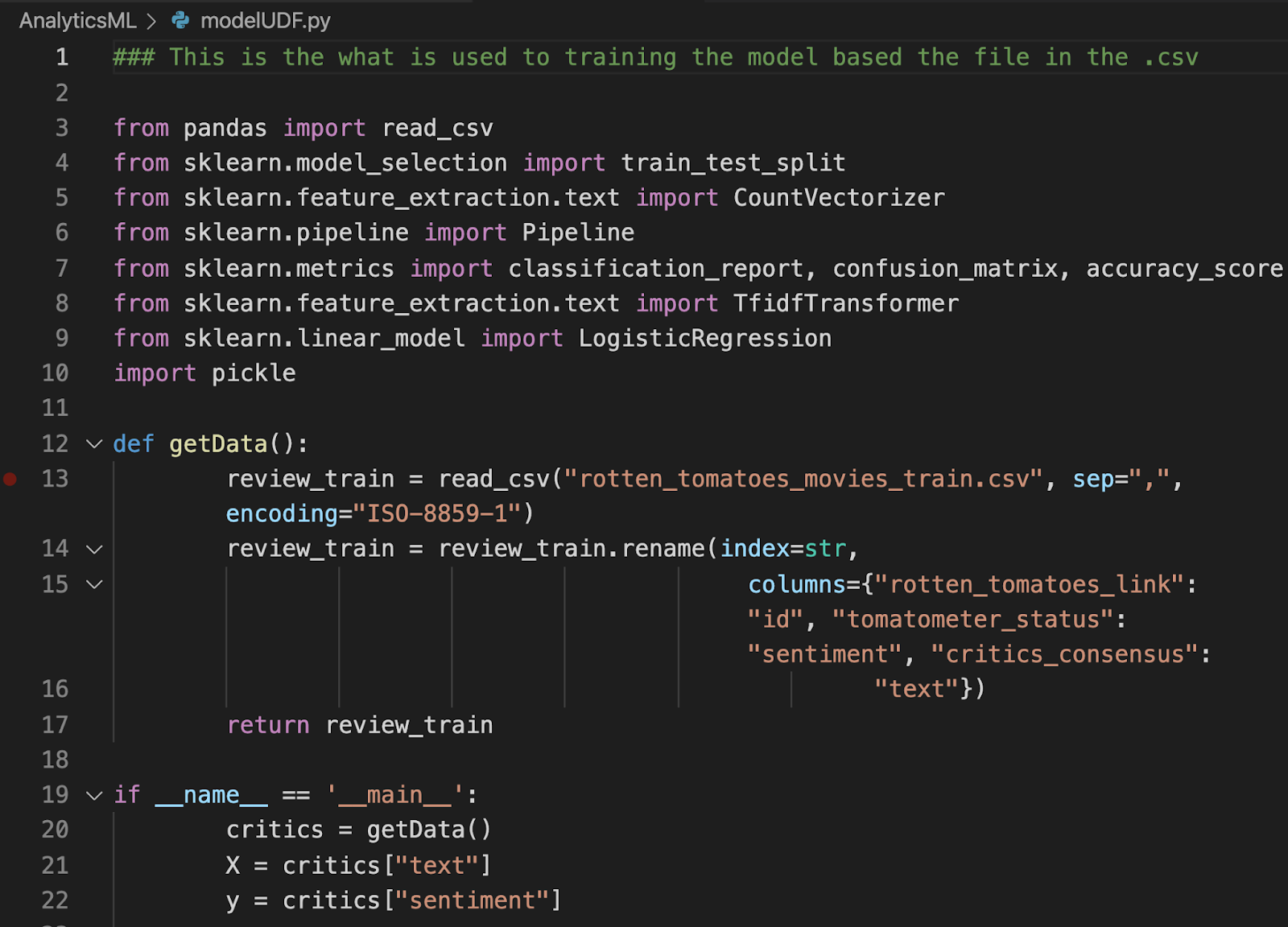
A totalidade do exemplo de código pode ser encontrada no arquivo Repositório do GitHub.
Ao executar o script Python do modelo mostrado acima, você deverá obter o seguinte resultado:

Você pode ler mais sobre as métricas do scikit-learn, como precisão, recall, pontuação f1 e suporte aqui. Agora temos um modelo de aprendizado de máquina funcional e com bom desempenho, totalmente treinado em Python.
Criando uma biblioteca Python
Para fazer referência ao modelo de aprendizado de máquina, você precisará criar uma biblioteca Python. Abaixo está a biblioteca para este exemplo específico:
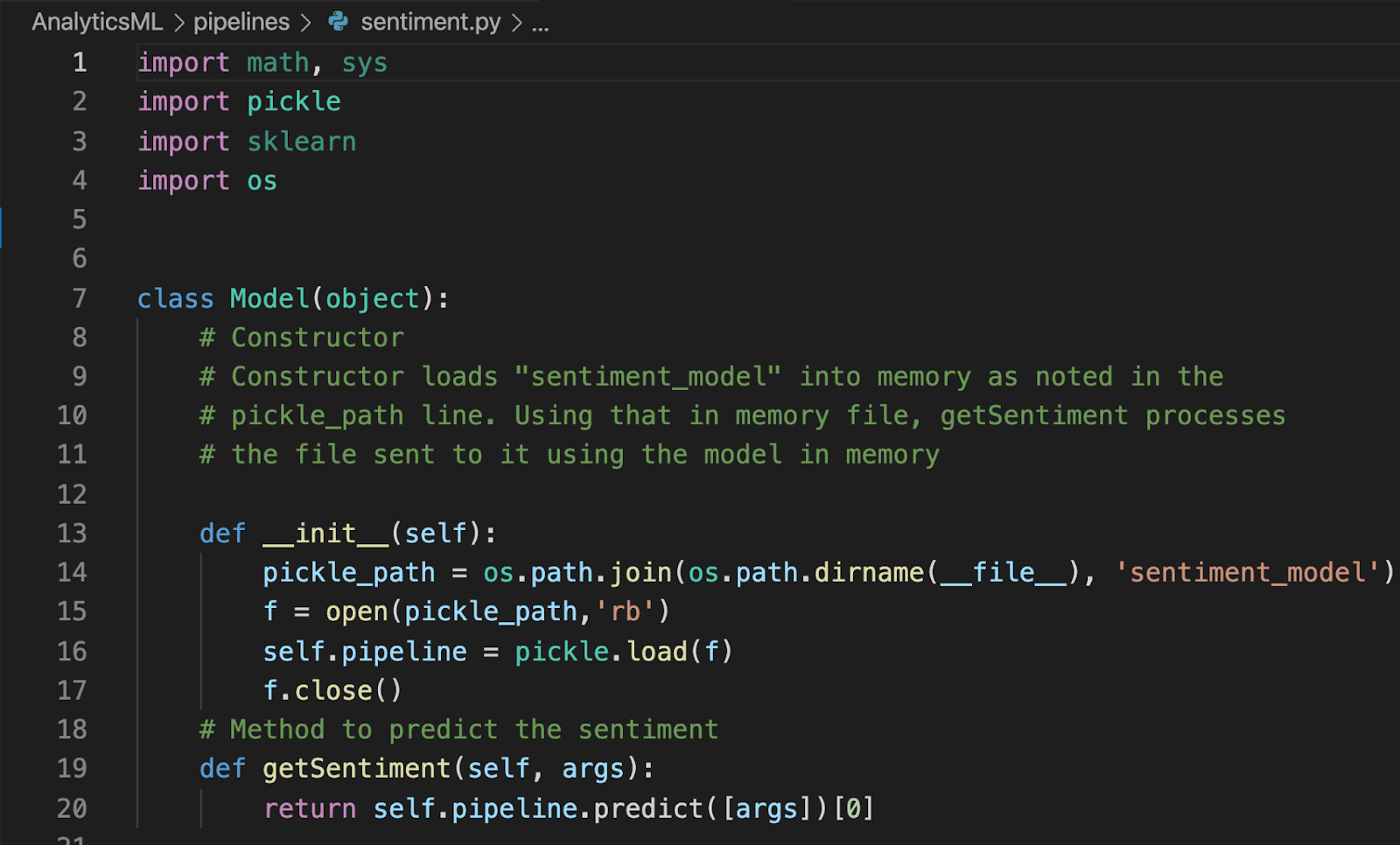
Há dois componentes principais da biblioteca:
Construtor de modelos-Esse construtor cria um arquivo chamado modelo_de_sentimento no dutos do nosso ambiente Jupyter.
método getSentiment-Esse método prevê o sentimento do cliente associado ao parâmetro (ou argumento) passado para ele.
Salve o arquivo como sentimento.py dentro do dutos com o arquivo modelo_de_sentimento.
Empacotamento e implantação da biblioteca
Essa é uma etapa essencial para o que virá a seguir: desbloquear o poder das funções definidas pelo usuário do Python! Preste atenção aos detalhes, pois ela depende mais da sintaxe do que qualquer outra. Certifique-se de ler atentamente a documentação apropriada. Siga o link para saber mais sobre funções definidas pelo usuário.
Para empacotar o modelo e a biblioteca que criamos nas etapas anteriores, usaremos o utilitário shiv. Se o shiv ainda não estiver instalado, use o comando pip install shiv (ou pip3 install shiv dependendo de seu ambiente). Além disso, se você estiver interessado em ler a documentação desse utilitário de linha de comando, poderá encontrá-la aqui.
Etapas para empacotar o modelo:
- Em seu laptop, empacote o modelo de sentimento e o código do modelo. Isso o torna autoexecutável e remove todas as dependências de biblioteca:
-
- shiv -site-packages pipelines/ -o pipeline.pyz -platform manylinux1_x86_64 -python-version 39 -only-binary=:all: scikit-learn
-plataforma manylinux1_x86_64 só é necessário quando se usa uma máquina virtual com Linux.
- Copie o pacote Python autônomo com as dependências necessárias para o servidor de análise:
- docker cp pipeline.pyz cb-analytics:/tmp/
- Acesse o shell do cb-analytics Contêiner do Docker:
- docker exec -it cb-analytics bash
- No shell do Docker, vá para o diretório tmp na pasta onde o arquivo zip está localizado e importe os dados necessários para os dois compartimentos:
- cd /tmp
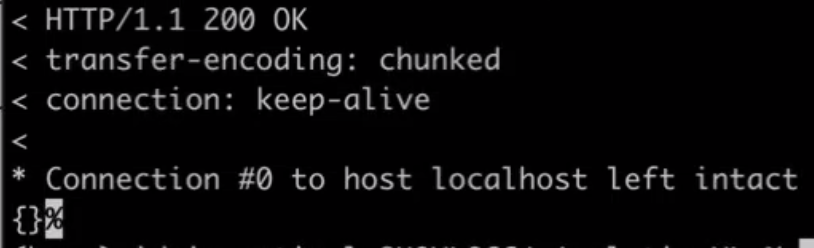
- curl -v -X POST -F "data=@./pipeline.pyz" -F "type=python" "localhost:8095/analytics/library/Default/sentimentlibrary" -u Administrator:password;
- O sistema será atualizado quando estiver concluído e será bem-sucedido quando você vir essa resposta HTTP 200:
Importando o documento do bucket para análise pelo UDF
Há duas etapas a serem seguidas em seu computador local e três comandos a serem executados na instância do Docker.
Máquina local
0. Criar baldes filme ou críticas de filmes seja no console da Web ou por meio do couchbase-cli comando
- Executar: docker cp rotten_tomatoes_critic_reviews.csv cb:/tmp/ Esse arquivo ultrapassa o limite de 100 Mb do utilitário de importação da GUI e precisa ser importado diretamente.
Instância do Docker
2. docker exec -it cb bash
3. cbimport csv -infer-types -c https://localhost:8091 -u Administrator -p password -d 'file://rotten_tomatoes_critic_reviews.csv' -b 'movie_reviews' -scope-collection-exp "_default._default" -g "%rotten_tomatoes_link%"
4. cbimport csv -infer-types -c https://localhost:8091 -u Administrator -p password -d 'file://rotten_tomatoes_movies.csv' -b 'movies' -scope-collection-exp "_default._default" -g "%rotten_tomatoes_link%"
Você pode importar o último arquivo (rotten_tomatoes_movies.csv) na linha de comando, conforme mostrado acima, ou no Console da Web do Couchbase > Documento > Importar do portal do Couchbase, conforme mostrado nesta captura de tela:
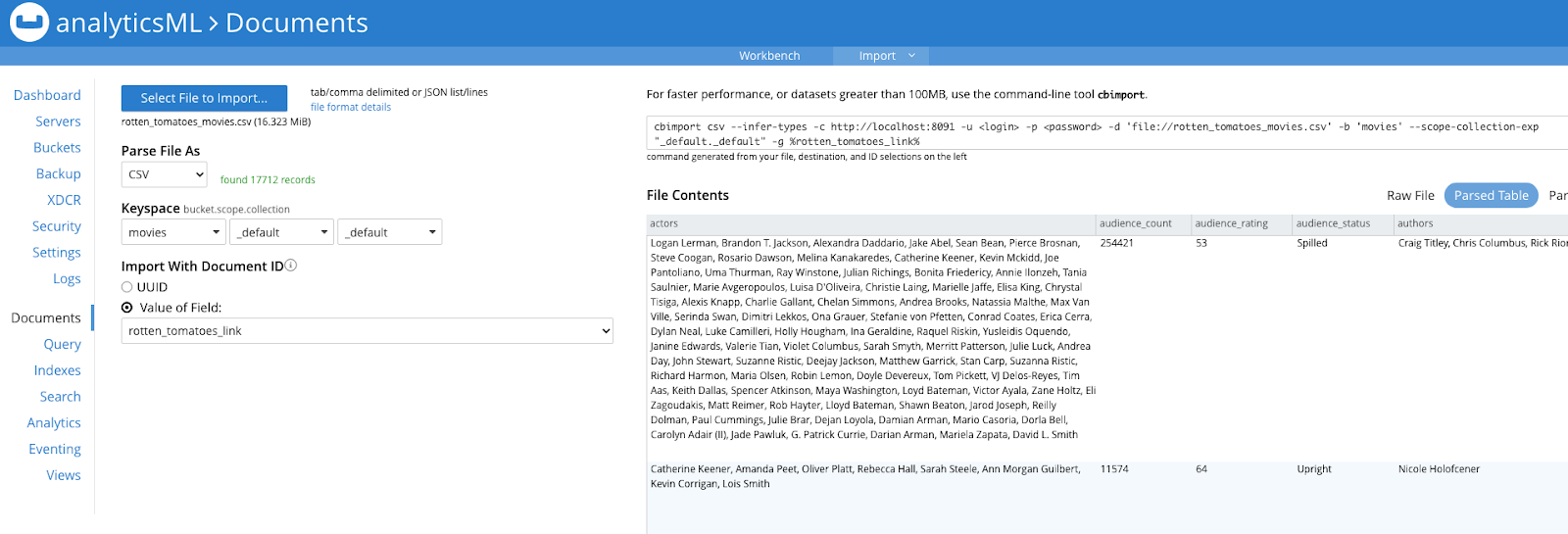
Agora você tem documentos nos dois buckets e eles contêm a crítica e os resumos dos filmes no Couchbase para executar a análise de sentimentos.
Gravação de UDFs
É hora de escrever nossa própria função definida pelo usuário no Couchbase Analytics. Se você precisar de uma atualização, aqui está um link para nossa documentação sobre Funções definidas pelo usuário. Consulte a biblioteca (o Modelo e o construtor getSentiment ) que criamos na Etapa 2 e depois carregamos no servidor do Analytics na Etapa 3. Eles agora são referenciados na seguinte função definida pelo usuário:
|
1 2 |
CRIAR ANALÍTICA FUNÇÃO getReviewSentiment(texto) AS "sentimento", "Model.getSentiment" AT biblioteca de sentimentos; |
Crie o UDF do Analytics no mesmo local (biblioteca de sentimentos) conforme especificado no enrolar função.
Invocando os UDFs
Aproveitando os recursos do N1QL, agora podemos escrever consultas preditivas no Couchbase Analytics para obter insights avançados de nossos UDFs. Por baixo dos panos, ao invocar esse UDF, ele chama o Modelo que itera sobre cada linha para fazer a análise de sentimento. A seguir, um exemplo básico de uma consulta desse tipo, mas as possibilidades são realmente infinitas.
|
1 2 3 4 5 6 |
USO Padrão; SELECIONAR getReviewSentiment(r.review_content) AS sentimento, CONTAGEM(*) AS SentimentCount DE filme_revisões r, filmes m ONDE m.rotten_tomatoes_link = r.rotten_tomatoes_link GRUPO BY getReviewSentiment(r.review_content) ORDEM BY SentimentCount DESC; |
Com essa consulta, você obterá resultados como os seguintes:
|
1 2 3 4 5 6 7 8 9 10 |
[ { "sentimentCount": 10105, "sentimento": "Fresco" }, { "sentimentCount": 7601, "sentimento": "Podre" } ] |
Agora temos uma contagem ordenada de sentimentos positivos, neutros e negativos, conforme definido por nosso modelo treinado.
Conclusão
Parabéns, você acabou de configurar o ambiente necessário do Couchbase Server no Docker e executou com êxito sua primeira função definida pelo usuário no Couchbase Analytics. Como você pode ver, a integração dos seus modelos Python ML com UDFs e o Couchbase Analytics promete ser uma maneira eficaz de extrair informações valiosas dos seus dados sem comprometer o desempenho ou a eficiência.
Fique à vontade para compartilhar dúvidas ou comentários nos comentários abaixo ou por meio de uma postagem em Fóruns do Couchbase. Mal podemos esperar para ver como você combinará o poder do ML e do NoSQL para sua empresa.
Se quiser saber mais sobre o Couchbase Analytics, assista à nossa Sessão de conexão: Aprendizado de máquina e NoSQL: UDFs em Python.
Aqui está um resumo dos links e tópicos mencionados nesta postagem:
- Parte 1 - O ML encontra o NoSQL: Integração de funções definidas pelo usuário do Python com o N1QL para análise
- Repositório do GitHub do Couchbase AnalyticsML
- Conjunto de dados do Kaggle de avaliações do Rotten Tomatoes
- Documentação das funções definidas pelo usuário do Couchbase
Agradecimentos
Agradecimentos a Anuj Kothari, um estagiário de verão em gerenciamento de produtos do serviço Couchbase Analytics, cujos esforços iniciais fizeram com que isso começasse e saísse do papel no verão passado. Agradecimentos a Idris MotiwalaGerente de produto principal do Couchbase Analytics Service e Ian Maxonengenheiro de software do Couchbase Analytics Service, por seu trabalho editorial para tornar este blog mais funcional.
