O Kafka é uma plataforma de streaming que pode ser usada para transmitir registros para (Kafka sink) e de (Kafka source) centros de dados. O Couchbase criou e oferece suporte a um aplicativo Kafka conector que permite que você use facilmente o Couchbase como uma fonte ou um coletor.
Estou trabalhando em um tutorial completo para um Cliente 360 caso de uso. Uma parte dele envolve o Kafka. Aqui está um diagrama de alto nível:
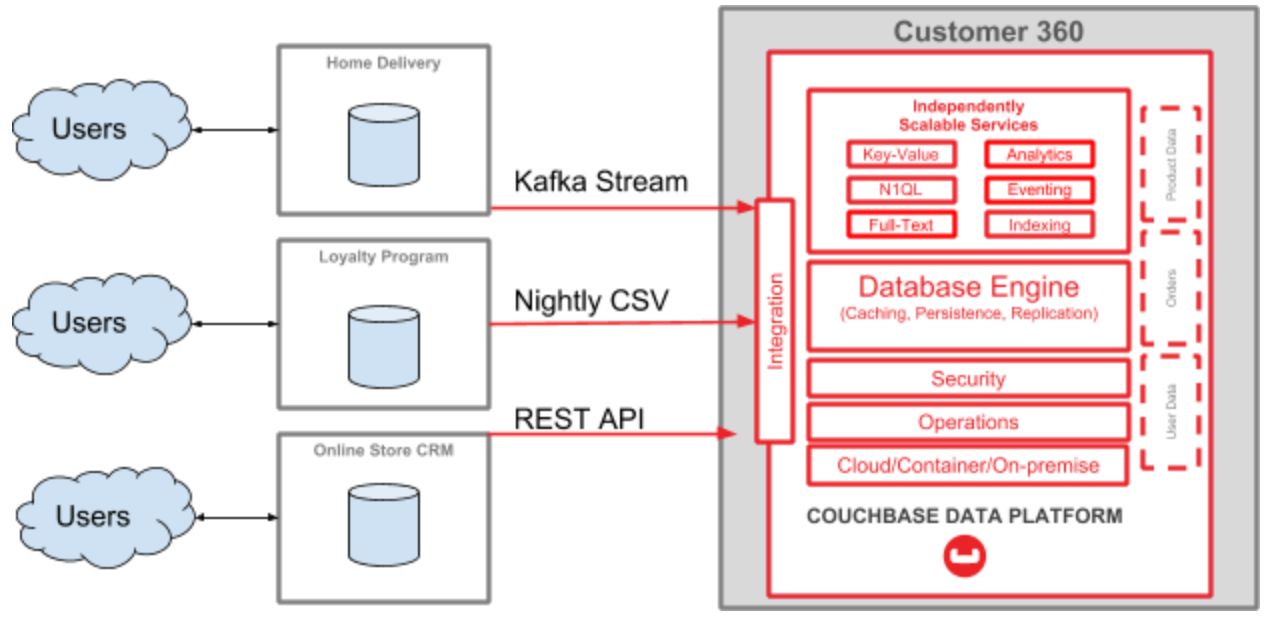
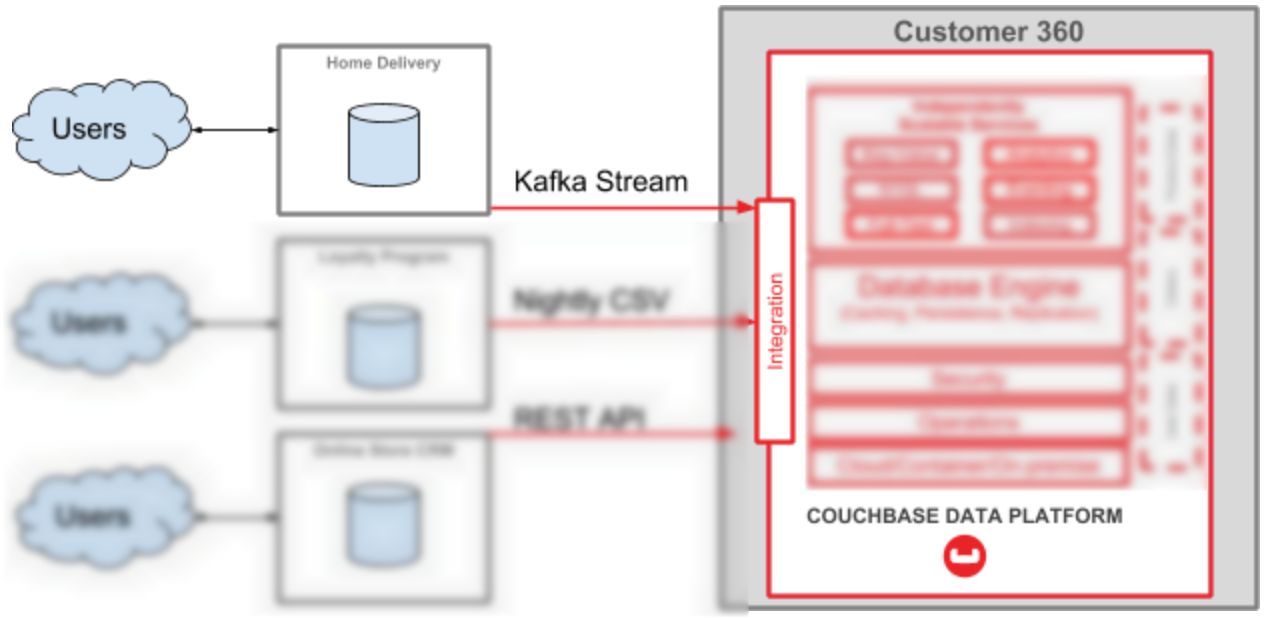
Uma parte desse tutorial é um guia sobre como começar a transmitir dados de um banco de dados MySQL (que é usado para um sistema de "entrega em domicílio" em uma empresa) para a plataforma de dados Couchbase (que será usada para fins do Customer 360). Para esta postagem do blog, estou me concentrando apenas nessa parte do diagrama:
Pré-requisitos
Comecei sem saber muito sobre o Kafka, mas consegui montar uma prova de conceito funcional usando:
- Docker. Você precisará ter o Docker instalado para concluir este tutorial. Talvez você queira mover tudo isso para o docker-compose ou (mais provavelmente) Kubernetes. Estou criando toda a arquitetura nesta postagem, mas em sua empresa haverá pelo menos algumas partes que já estão implantadas.
- Tutorial de início rápido do Debezium - O Debezium é o conector que escolhi usar para configurar um banco de dados MySQL como um fonte.
- Início rápido do Docker do Couchbase - para executar um cluster simples do Couchbase no Docker
- Couchbase Kafka Tutorial de início rápido do conector - Este tutorial mostra como configurar o Couchbase como um coletor do Kafka ou como uma fonte do Kafka.
- Referência do Dockerfile - como criar uma imagem do docker personalizada. Isso pode parecer intimidador, mas não se preocupe, são apenas algumas linhas de texto.
Configuração do Couchbase
Instalar o Couchbase com o Docker:
docker run -d --name db -p 8091-8094:8091-8094 -p 11210:11210 couchbase
Você também precisará configurar o cluster do Couchbase como de costume. Criei um bucket chamado "staging".
Executando o Zookeeper, o Kafka e o MySQL
Na maior parte do tempo, você só precisará seguir o Tutorial do Debezium. Certifique-se de ler todos os detalhes, mas a versão resumida é seguir estas etapas:
Execute uma imagem do Zookeeper (isso é necessário para o Kafka):
docker run -it --rm --name zookeeper -p 2181:2181 -p 2888:2888 -p 3888:3888 debezium/zookeeper:0.9
Execute uma imagem do Kafka (vinculada ao Zookeeper):
docker run -it --rm --name kafka -p 9092:9092 --link zookeeper:zookeeper debezium/kafka:0.9
Inicie um banco de dados MySQL (o Debezium fornece uma imagem do Docker que já contém alguns dados de amostra):
docker run -it --rm --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw debezium/example-mysql:0.9
Depois disso, você pode se conectar ao banco de dados MySQL usando as credenciais acima. O tutorial do Debezium fornece outra imagem do Docker para fazer isso, ou você pode usar a ferramenta MySQL de sua preferência. Não é necessário fazer isso agora, mas eventualmente você desejará se conectar a ele e inserir/atualizar dados para testar o processo de ponta a ponta.
Preparação dos conectores Kafka
Neste ponto de minha jornada, devo divergir um pouco do tutorial do Debezium. Esse tutorial mostra como iniciar um Debezium MySQL Connector (com outra imagem do Docker e uma solicitação REST). No entanto, quero apresentar o Conector Kafka do Couchbase.
A maneira mais fácil de fazer isso é criar uma imagem personalizada do Docker. Isso usará a imagem do Debezium Kafka Connect como base e simplesmente adicionará o arquivo JAR do Couchbase Kafka Connect a ela. Para fazer isso, crie um arquivo de texto chamado Dockerfile:
|
1 2 3 4 |
DE debezium/conectar:0.9 # colocou o kafka-connect-couchbase-3.4.3.jar em # a pasta /kafka/connect/couchbase ADD kafka-conectar-couchbase-3.4.3.jar /kafka/conectar/couchbase/kafka-conectar-couchbase-3.4.3.jar |
Depois de fazer isso, crie a imagem: compilação do docker . --tag couchbasedebezium. Chamei a imagem de sofá-baseadoebeziummas você pode chamá-lo como quiser. Depois que isso for concluído, execute imagens do dockere sofá-baseadoebezium deve aparecer em seu repositório local:
|
1 2 3 4 5 6 7 8 9 10 |
PS C:\minha pasta> doca imagens REPOSITÓRIO TAG IMAGEM ID CRIADO TAMANHO sofá-baseadoebezium mais recente a48fa903cc7d 3 dias atrás 641 MB debezium/conectar 0.9 5a5e60b3f50a 2 semanas atrás 633 MB debezium/kafka 0.9 b4b130f4bb9c 2 semanas atrás 612 MB debezium/tratador de zoológico 0.9 4ba823930ede 2 semanas atrás 519 MB debezium/exemplo-mysql 0.9 ba801de1fe22 3 semanas atrás 372 MB couchbase empresa-6.0.1 5403ed5c6ef4 2 meses atrás 940 MB ... etc ... |
Iniciando o Kafka Connect
Para iniciar o Kafka Connect:
docker run -it --rm --name connect -p 8083:8083 -e GROUP_ID=1 -e CONFIG_STORAGE_TOPIC=my_connect_configs -e OFFSET_STORAGE_TOPIC=my_connect_offsets -e STATUS_STORAGE_TOPIC=my_connect_statuses --link zookeeper:zookeeper --link kafka:kafka --link mysql:mysql --link db:db couchbasedebezium
Isso iniciará uma imagem do Docker que usaremos para conectar o Kafka ao MySQL e ao Couchbase. Observe que estou usando a opção sofá-baseadoebezium e também estou usando a imagem -link db:dbmas, fora isso, é idêntico ao tutorial do Debezium.
Há mais duas etapas:
- Diga ao Kafka Connect para usar o MySQL como fonte.
- Diga ao Kafka Connect para usar o Couchbase como coletor.
Há várias maneiras de fazer isso, mas decidi usar a API REST do Kafka.
Conecte-se ao MySQL como uma fonte
Crie uma solicitação POST para http://localhost:8083/connectors/ com o corpo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ "name" (nome): "conector de inventário", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "mysql", "database.port": "3306", "database.user": "debezium", "database.password": "dbz", "database.server.id": "184054", "database.server.name": "dbserver1", "database.whitelist": "inventário", "database.history.kafka.bootstrap.servers": "kafka:9092", "database.history.kafka.topic": "schema-changes.inventory" } } |
Isso foi extraído diretamente do tutorial do Debezium. Observe especialmente database.server.name e banco de dados.whitelist. Depois de fazer esse POST, os dados começarão a fluir imediatamente do MySQL para o Kafka.
Conectar-se ao Couchbase como um sink
Crie outra solicitação POST para http://localhost:8083/connectors/ com o corpo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "name" (nome): "home-delivery-sink" (pia de entrega em domicílio), "config": { "connector.class": "com.couchbase.connect.kafka.CouchbaseSinkConnector", "tasks.max": "2", "tópicos" : "dbserver1.inventory.customers", "connection.cluster_address" : "db", "connection.timeout.ms" : "2000", "connection.bucket" : "staging" (preparação), "connection.username" : "Administrador", "connection.password" : "senha", "couchbase.durability.persist_to" : "NONE", "couchbase.durability.replicate_to" : "NONE", "key.converter" : "org.apache.kafka.connect.storage.StringConverter", "value.converter" : "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable" : "false" (falso) } } |
Essa configuração é amplamente extraída do Início rápido do Couchbase. Em vez de ser um arquivo de texto para a linha de comando, é um HTTP POST. Observe especialmente:
conector.class- Esta é a classe do conector que reside no arquivo JARtópicos- Os tópicos dos quais o Couchbase irá afundar.connection.cluster_address- Quando iniciei o Couchbase no Docker, dei a ele o nome de "db"conexão.bucket,connection.username,connection.password- Essas são todas as configurações que criei ao configurar o Couchbase.
Os dados estão fluindo agora
Agora, os dados devem estar fluindo para o seu bucket do Couchbase. Conecte-se ao Couchbase e você verá 4 documentos no bucket de teste (isso corresponde às 4 linhas de dados no banco de dados de amostra do MySQL). Adicione ou atualize os dados no banco de dados MySQL e mais registros começarão a entrar no bucket do Couchbase automaticamente.
Passei por todo esse processo em minha Transmissão de código ao vivo no Twitch. Se você quiser ver todo esse processo em ação, criei um vídeo de destaque para mostrar todas as etapas:
[youtube https://www.youtube.com/watch?v=HCAY7EMm3pg&w=560&h=315]
Recursos e próximas etapas
Agora que você concluiu este tutorial, há outras direções que você pode seguir para continuar explorando.
- Orquestração: esta amostra contém muitas imagens do Docker que são executadas manualmente. Em um ambiente de produção, você provavelmente desejaria orquestrar e dimensionar algumas ou todas essas peças com algo como o Kubernetes. Há um Operador do Kubernetes para o Couchbase Enterprise.
- Cliente 360: O streaming de dados de um banco de dados MySQL para o Couchbase é apenas um passo nessa direção. Um aplicativo Customer 360 provavelmente extrairá dados de uma variedade de outros bancos de dados. Fique atento ao Blog do Couchbase e aos Tutoriais do Couchbase para obter mais informações sobre como criar uma arquitetura de ingestão do Customer 360.
Se tiver perguntas para mim, pode entrar em contato pelo telefone Twitter @mgrovesdeixe um comentário abaixo ou sintonize em meu próximo Transmissão de código ao vivo.
Se você tiver dúvidas técnicas sobre o Couchbase ou o Conector Kafka do Couchbase, não deixe de conferir a seção Fóruns do Couchbase.