Estou muito animado em anunciar a prévia para desenvolvedores #1 do provedor Linq oficial para o Couchbase N1QL! Este é um pré-lançamento muito antecipado para apresentar o provedor, visualizar sua funcionalidade básica e ilustrar como usá-lo. Neste blog, criarei um aplicativo de amostra que aborda as etapas de como usar o provedor hoje.
Isenção de responsabilidade
Por ser um pré-lançamento, espera-se que a API pública mude significativamente até que a versão beta esteja disponível. Observe que o projeto Couchbase.Linq depende da versão GA do SDK. Não use esse provedor em produção até a versão GA do SDK 2.2.0!
Obtendo o pacote
O pacote é um pré-lançamento no NuGet e pode ser encontrado em aqui. Se você estiver usando o Visual Studio, provavelmente desejará usar o NuGet Package Manager ou o NuGet Package Manager Console para incluir as dependências no seu projeto.
Primeiro, crie um aplicativo de console usando o Visual Studio. Em seguida, usando o Package Manager, procure por Couchbase.Linq:
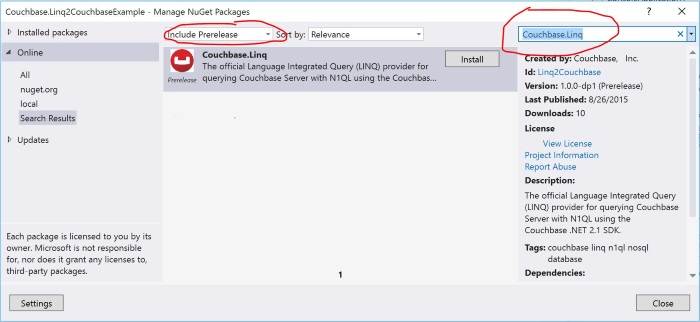
Certifique-se de selecionar "Include Prerelease" ao pesquisar, caso contrário, o pacote não aparecerá nos resultados da pesquisa. Clique em "install" (instalar) e todas as dependências serão instaladas para você. Por fim, feche a caixa de diálogo do Package Manager.
Configuração e inicialização
O provedor atual do Couchbase Linq tem uma forte dependência da classe ClusterHelper do Couchbase .NET 2.1 SDK. O ClusterHelper é uma classe que facilita o gerenciamento de buckets e outros recursos que, por motivos de desempenho, devem ter vida longa. É um singleton para um objeto Cluster e um "multiton" para referências de Bucket. Essa dependência provavelmente será removida em versões futuras, mas deve ser considerada quando você usar o provedor Linq em seu aplicativo.
Para lidar com essa dependência, basta usar o ClusterHelper em seu aplicativo e chamar explicitamente Initialize() exatamente uma vez durante a vida útil do aplicativo. Por padrão, o localhost será usado para inicializar o cliente, mas você pode usar a sobrecarga que recebe uma ClientConfiguration que pode ser personalizada como você quiser.
No gist acima, criamos uma nova configuração e especificamos uma instância do Couchbase Server instalada localmente como o destino do bootstrap. Em seguida, inicializamos o objeto auxiliar de cluster chamando Initialize e passando a configuração.
Criação de uma instância de DbContext
Depois de inicializar o ClusterHelper, você criará um objeto DbContext que é uma abstração do armazenamento de dados subjacente (o Couchbase Bucket) e fornece um meio de criar consultas e (em breve) agrupar alterações que serão enviadas de volta ao bucket.
O construtor DbContext recebe um objeto Cluster e, em seguida, o nome do bucket do Couchbase a ser usado na consulta.
Observe que, depois de criar o DbContext, ele pode ser usado várias vezes e você também pode executar JOINs contra ele mesmo. Em uma postagem posterior, mostrarei como herdar do DbContext para criar objetos de consulta concretos que mapeiem os documentos em seu bucket; eventualmente, forneceremos suporte a ferramentas para gerar esses objetos automaticamente a partir de um bucket.
Criação de uma consulta Linq
Criar uma consulta Linq não é diferente de usar qualquer outro provedor Linq em sua maior parte; as diferenças são que o Linq2Couchbase oferece suporte a palavras-chave e conceitos N1QL como NEST, UNNEST e USE KEYS, entre outros.
Como todas as consultas Linq, a execução é adiada até que você a enumere:
Aqui estamos simplesmente enumerando a consulta que criamos na etapa anterior. O provedor pegará a expressão que foi gerada e a converterá em uma consulta N1QL e a executará, retornando apenas a parte das linhas da resposta. Observe que as exceções serão lançadas pelo provedor Linq, o que é um comportamento diferente do Couchbase SDK, que retorna a exceção como uma propriedade da implementação IQueryResult.
E quanto à cláusula WHERE?
Você notou que não estamos especificando uma cláusula WHERE para filtrar por tipo de documento? Como os compartimentos são um espaço-chave de documentos heterogêneos, sem um predicado para filtrar os resultados, a consulta gerada retornaria todos os atributos Name de todos os documentos do compartimento (observe que o compartimento de amostra de cerveja tem tipos de documentos de cerveja e cervejaria). Como queremos manter a DRY e adicionar um WHERE type="[document-type]" para cada consulta seria tedioso, há uma maneira de especificar o filtro de documento como um atributo do POCO que estamos usando para nossa projeção.
Aqui na definição de POCO, adicionamos um EntityTypeFilter e especificamos "beer" (cerveja) como o tipo de documento que devemos direcionar com nossa consulta. Muito legal!
Conclusão
Instale o pacote e experimente-o. Diga-nos o que achou e, se encontrar algum erro ou tiver uma solicitação de recurso, crie um Tíquete do Jira ou enviar um solicitação de retirada!