No Couchbase, a latência e a taxa de transferência são significativamente afetadas pela replicação de dados.
Há diferentes tipos de modelos de replicação de dados, principalmente mestre-escravo (Couchbase, MongoDB, Espresso), mestre-mestre (BDR para PostgreSQL, GoldenGate para Oracle) e sem mestre (Dynamo, Cassandra). Este artigo discute apenas a replicação mestre-escravo em armazenamentos de valores-chave (KV).
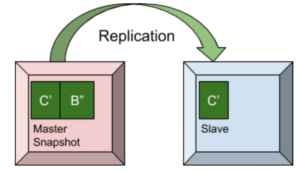
No modelo de replicação mestre-escravo, há um mestre para uma única partição de dados e uma ou mais réplicas, que são essencialmente escravas e seguem os dados na partição mestre. Os aplicativos clientes enviam os valores-chave para o mestre e, posteriormente, os valores-chave são enviados do mestre para as réplicas.
Este artigo começa com alguns conceitos, como ordenação, números de sequência monotonicamente crescentes, snapshots, MVCC usando gravações e compactação somente de acréscimo. Em seguida, o artigo explica como a replicação mestre-escravo pode ser feita com (1) Instantâneos do Delta ou com (2) Ponto no tempo snapshots, as vantagens e desvantagens entre eles e quando é melhor usar um em vez do outro. Por fim, o artigo discute brevemente como o Couchbase, uma plataforma popular de Big Data, usa esses snapshots para replicação de dados.
O particionamento dos dados, a atribuição das partições aos nós físicos, a detecção e o tratamento de falhas nos nós, a reconciliação de ramificações divergentes de dados e muito mais são importantes para alimentar um armazenamento KV distribuído. Este artigo não aborda nenhum desses aspectos, mas discute apenas a replicação mestre-escravo de uma única partição de dados - incluindo, especificamente, o Couchbase e a replicação.
Histórico
Replicação ingênua
Uma maneira de replicar dados é obter uma cópia completa da fonte sempre que quisermos uma cópia. Embora isso seja muito simples de implementar, não é de grande utilidade em bancos de dados OLTP ou em armazenamentos KV com carga de trabalho em tempo real, em que os dados de origem continuam recebendo novas atualizações, pois as cópias de réplica não podem obter essas atualizações em tempo real.
A capacidade de resumir, enviando apenas as alterações (delta), é um recurso importante para qualquer protocolo de replicação que frequentemente precisa lidar com grandes quantidades de dados. Mas isso tem um custo de complexidade adicional da necessidade de ordenação e instantâneos que discutiremos nas seções a seguir.
Ordenação com números de sequência
A ordem é importante porque permite que os aplicativos raciocinem sobre a causalidade dos dados ou, em outras palavras, permite que os aplicativos saibam se uma operação ocorreu antes ou depois de outra operação. Nos armazenamentos KV, a ordem é usada para identificar o valor mais recente de uma determinada chave no armazenamento e também significa a ordem em que as chaves são recebidas pelo armazenamento. Números de sequência monotonicamente crescentes são uma maneira de obter "ordem" nos valores-chave no armazenamento. Cada par de valor-chave no armazenamento tem um número de sequência exclusivo associado a ele e essa sequência aumenta monotonicamente à medida que o armazenamento recebe novos valores-chave.
| OPERAÇÃO | CHAVE | VALOR | NÚMERO DE SEQUÊNCIA |
| INSERIR | K1 | V1 | SEQ1 |
| INSERIR | K2 | V2 | SEQ2 |
| ATUALIZAÇÃO | K1 | V1' | SEQ3 |
| INSERIR | K3 | V3 | SEQ4 |
No exemplo acima, K2-V2 é recebido pela loja depois de K1-V1; K1-V1' é recebido pela loja depois de K2-V2 e assim por diante. Portanto, SEQ4 > SEQ3 > SEQ2 > SEQ1. Se o armazenamento for somente de acréscimo, com a ajuda de SEQ3 > SEQ1, podemos identificar que o valor (mais recente) de K1 é V1' e não V1.
O uso de números de sequência que aumentam monotonicamente ocorre principalmente em instantâneos pontuais, sobre os quais falaremos mais adiante.
Instantâneos
No sentido mais básico, um snapshot (um snapshot completo) é uma exibição imutável do armazenamento KV em uma instância. Essa também é uma exibição consistente do armazenamento KV nessa instância.
Definimos um "Instantâneo da Delta" como uma cópia imutável dos pares de valores-chave recebidos pelo armazenamento de KV em um período de tempo. Chamamos de snapshot delta porque o snapshot não contém todos os valores-chave no armazenamento e contém apenas os valores-chave recebidos após a formação de um snapshot delta imediatamente anterior, até o momento em que o snapshot atual é criado. Os instantâneos delta sucessivos fornecem uma visão consistente do armazenamento KV até um determinado ponto, ou seja, até o ponto em que o último instantâneo é criado.
MVCC usando Append Only Writes
O controle de simultaneidade de várias versões (MVCC) é um método de controle de simultaneidade usado em armazenamentos KV para permitir leitores e gravadores simultâneos. A maneira mais simples de lidar com a simultaneidade seria usar bloqueios de leitura e gravação. No entanto, em armazenamentos KV distribuídos que lidam com grandes quantidades de dados, o MVCC provou ser extremamente útil em relação ao bloqueio. O MVCC ajuda a obter taxas de transferência mais altas e latências mais baixas para leituras e gravações.
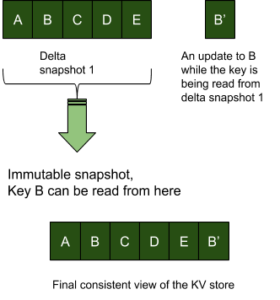
O MVCC é obtido com o uso de instantâneos e gravações somente de acréscimo no armazenamento KV. No exemplo abaixo, digamos que a "chave B" seja atualizada por um escritor enquanto há leitores no instantâneo delta 1. O controle de simultaneidade com bloqueio exigiria que a entidade mutante esperasse até que a replicação de todo o snapshot fosse concluída. No entanto, com uma abordagem MVCC somente de acréscimo, a gravação na chave B pode continuar a ocorrer mesmo quando o instantâneo atual estiver sendo lido.
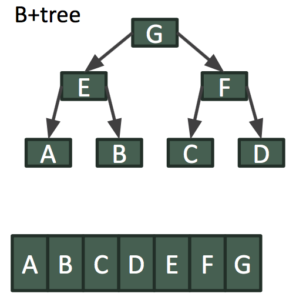
Para leitores mais avançados, o MVCC também pode ser feito quando o armazenamento KV usa estruturas de dados mais complicadas para armazenar dados. O exemplo abaixo mostra como o MVCC pode ser obtido em uma B+Tree somente de acréscimo. Digamos que a "chave B" seja atualizada por um escritor enquanto houver leitores no instantâneo delta atual.
Com uma abordagem MVCC somente de anexo, a gravação na "chave B" e o ramo associado na árvore B+ podem continuar a ocorrer mesmo quando o instantâneo atual estiver sendo lido, conforme mostrado abaixo.
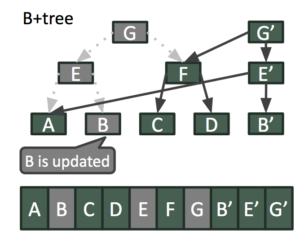
Os dois instantâneos sobrepostos representados pelas raízes B+Tree de G e G' representam visualizações consistentes do repositório KV em duas instâncias de tempo.
Compactação
Como os instantâneos são imutáveis, as atualizações das chaves são anexadas apenas ao final do armazenamento da KV e, portanto, o uso da memória do armazenamento acabará se tornando muito maior do que a memória necessária para os valores-chave ativos. Portanto, o armazenamento KV precisa mesclar periodicamente os instantâneos mais antigos e se livrar dos valores-chave duplicados/velhos em uma tarefa em segundo plano chamada compactação. A compactação reduz a memória usada pelo repositório KV.
Os acionadores para compactação podem estar em um limite de memória ou em um intervalo de tempo fixo ou em uma combinação de ambos.
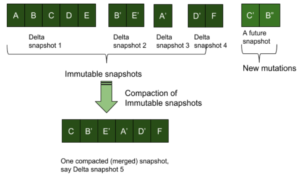
Instantâneos do Delta
Os armazenamentos KV podem ser replicados enviando uma sequência de instantâneos delta sucessivos. Conforme explicado acima, em uma abordagem de gravações append-only, novos valores-chave e atualizações são apenas anexados ao armazenamento. Depois de receber um lote de itens, um instantâneo imutável é criado e está pronto para ser enviado aos nós de réplica. Os valores de chave recebidos pelo armazenamento após a criação desse instantâneo são anexados ao armazenamento e farão parte do próximo instantâneo. Os clientes de replicação coletam esses instantâneos delta imutáveis um após o outro e obtêm uma visualização do armazenamento que é consistente com a origem. Observe que isso não precisa de números de sequência para cada par de KV, mas precisará identificar a ordem dos delta snapshots.
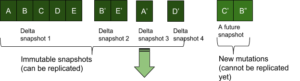
Uma desvantagem dessa abordagem é que o lado de origem do armazenamento KV pode compactar os vários instantâneos delta imutáveis em um único instantâneo. Agora, se a compactação ocorrer antes que um cliente de replicação tenha recebido o último snapshot compactado, o cliente terá que receber o snapshot totalmente compactado desde o início do snapshot. Digamos que haja 5 instantâneos delta imutáveis snp1, snp2, snp3, snp4 e o cliente tenha recebido até o snp3; então, a compactação é executada e os 4 instantâneos no lado da origem são compactados em um único instantâneo snp1'. Agora o cliente não pode retomar a partir do snp3, ele terá que reverter os instantâneos que recebeu antes (até o snp3) e terá que receber o snp1' completamente.
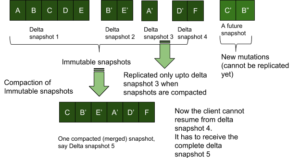
Podemos fazer uma otimização com um número de sequência (monotonicamente crescente) em cada par de valores-chave e, em seguida, enviar pela rede apenas os números de sequência que são maiores que o snap_end de snp3. Entretanto, o armazenamento KV ainda terá de ler desde o início de snp1' para chegar ao snap_end de snp3.
Outra desvantagem da abordagem é que os pares de valores-chave mais recentes não podem ser replicados até que sejam formados em um instantâneo delta imutável. Isso aumenta a latência das chaves que estão sendo enviadas para as réplicas.
Os snapshots delta são bons para replicar um lote razoavelmente grande de itens, ou seja, para replicar um lote de itens, alta taxa de transferência, mas também alta latência.
Snapshots pontuais
Os snapshots point-in-time são os snapshots criados em tempo real. Ou seja, enquanto novos dados e atualizações estão sendo gravados no repositório de KV, o repositório cria o snapshot se um cliente de replicação solicitar dados. Isso significa que, para receber os valores-chave mais recentes, as réplicas não precisam esperar que um snapshot seja criado na origem.
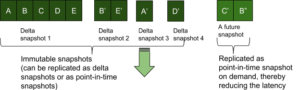
Os snapshots point-in-time podem ser criados muito rapidamente (baixa latência) em um armazenamento KV somente de acréscimo e são mais adequados para replicação de itens na memória e em estado estável. Por estado estável, queremos dizer que todos os clientes de replicação quase alcançaram a origem.
Esse modelo exige que cada par chave-valor tenha um número de sequência monotonicamente crescente. Um snapshot point-in-time é definido pela tupla {start_seqno, end_seqno}.
Digamos que a origem tenha pares de valores-chave do número de sequência 0 a 100 e um cliente de replicação R1 faça uma solicitação de cópia de dados. Os pares de valores chave do número de sequência 0 a 100 são enviados como um instantâneo (instantâneo point-in-time) para R1 e um cursor C1 que corresponde ao cliente R1 é marcado no armazenamento. Em um momento posterior, digamos que o armazenamento tenha anexado mais 20 pares KV e tenha o número de sequência mais alto, 120. Se outro cliente R2 solicitar dados, os pares de valores-chave do número de sequência 0 a 120 serão enviados como um instantâneo para R2 e um cursor C2 que corresponde ao cliente R2 será marcado no armazenamento. Quando mais dados são anexados ao armazenamento, digamos até o número de sequência 150, o cliente R1 pode obter até 150 em um instantâneo pontual sucessivo de 101 a 150 e o cliente R2 em um instantâneo pontual sucessivo de 121 a 150. Observe que os cursores C1 e C2 são importantes para recomeçar rapidamente de onde os clientes R1 e R2 pararam antes. À medida que os cursores se movem, os pares de valores-chave com número de sequência menor que o número de sequência em que qualquer cursor está marcado podem ser compactados sem nenhuma contenção de leitura e gravação ou removidos da memória (no caso de replicação de dados na memória em um armazenamento KV persistente).
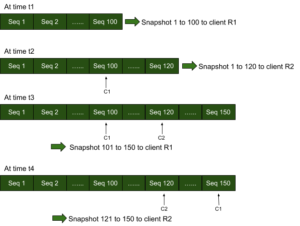
Os snapshots point-in-time são bons para a replicação em estado estável, pois os clientes de replicação obtêm seus próprios snapshots que são criados sob demanda e, portanto, evitam qualquer espera pela criação de um snapshot. Assim, os clientes podem se atualizar com a origem muito rapidamente com os pares de valores-chave mais recentes enviados o mais rápido possível. Além disso, os clientes não precisam recomeçar se uma compactação for executada entre seus instantâneos sucessivos e a origem também não precisa manter instantâneos delta para que todos os clientes os leiam.
Clientes lentos e clientes atrasados (diferidos) não funcionam bem com instantâneos pontuais. Como não podemos compactar sem contenção de leitura e gravação ou ejetar da memória os pares de valores-chave com número de sequência menor que o número de sequência do cursor com o menor número de sequência, um cliente lento pode diminuir a velocidade de criação de instantâneos point-in-time para todos os outros clientes e também aumentar o uso da memória.
Os snapshots point-in-time são bons para replicar rapidamente os itens mais recentes, ou seja, para que os itens mais recentes sejam replicados, baixa latência, mas também baixa taxa de transferência.
Uso de snapshots delta e point-in-time
Ambos alta taxa de transferência e baixa latência pode ser obtida alternando dinamicamente entre o modo de instantâneo delta ou o modo de instantâneo point-in-time, conforme necessário, durante a replicação de uma partição.
Quando um cliente de replicação se conecta a uma origem, ele inicialmente obtém instantâneos delta em uma alta taxa de transferência, de modo que logo alcança a origem e, portanto, atinge o estado estável. Em seguida, a replicação muda para o modo de snapshot point-in-time e, assim, o cliente continua recebendo os itens mais recentes em uma latência muito baixa. Se, por algum motivo, um cliente ficar lento, a replicação volta para o modo de instantâneo delta incremental para reduzir qualquer aumento não saudável no uso da memória. E quando o cliente lento alcança a fonte e atinge o estado estável novamente, a replicação muda para o modo de instantâneo point-in-time.
Outras considerações sobre o projeto
Eliminação de exclusões
No modo somente anexar, as exclusões são sempre anexadas no final do armazenamento. Na replicação que usa snapshots, a anexação de exclusões é essencial para refletir a exclusão de uma chave em todas as réplicas. No entanto, não podemos manter as exclusões para sempre, pois elas representam uma sobrecarga para a memória do armazenamento. Portanto, eventualmente, as exclusões precisam ser eliminadas.
Mas a eliminação de exclusões pode ter efeitos em clientes de replicação lenta e, às vezes, pode interromper a replicação incremental, especialmente em clientes que não alcançaram o instantâneo em que uma exclusão foi eliminada. Esses clientes podem ter que reconstruir todos os instantâneos desde o início para obter uma cópia que seja consistente com a origem.
Ramificação
Falhas graves podem levar a diferentes ramificações de dados entre réplicas. Essas ramificações podem ser reconciliadas e, eventualmente, todas as réplicas podem ter as mesmas cópias consistentes. Existem protocolos e algoritmos para fazer isso e eles se cruzam muito bem com o mundo dos instantâneos. No entanto, esses aspectos estão fora do escopo deste artigo. Este artigo discute apenas os esquemas de replicação e de snapshotting quando não há falhas graves.
Deduplicação
A deduplicação é a remoção de versões duplicadas da mesma chave em um instantâneo e a retenção apenas da versão final da chave nesse instantâneo. O principal objetivo da deduplicação é reduzir o uso da memória.
A deduplicação é feita em snapshots delta durante a compactação. Nos snapshots point-in-time, a deduplicação pode ser feita durante a compactação e também enquanto os itens estão sendo anexados. Fazer a deduplicação junto com snapshots point-in-time cria uma complexidade adicional, como a impossibilidade de gravar quando um snapshot point-in-time está sendo lido e a não-reprodutibilidade quando a origem de um cliente muda em casos de falha. Conforme mencionado anteriormente, a discussão sobre esses cenários de falha está além do escopo deste artigo.
Uso no Couchbase
No Couchbase, a latência e a taxa de transferência se beneficiam da replicação que escolhe dinamicamente instantâneos delta do disco ou instantâneos point-in-time da memória. Os snapshots delta do disco também usam números de sequência monotonicamente crescentes para retomar de onde os clientes pararam para reduzir o tráfego da rede.
O Couchbase também faz desduplicação, detecção e tratamento de falhas de nós, reconciliação de ramificações divergentes de dados, fornecendo clientes de dados mais sofisticados do que apenas clientes de replicação (indexação, pesquisa de texto completo), armazenamento em cache, particionamento e muito mais, o que é importante para fornecer uma plataforma de dados altamente disponível, de alto desempenho e que prioriza a memória.
Conclusão
Na replicação mestre-escravo, os "Delta Snapshots" são bons para replicar um lote de itens e, portanto, oferecem alta taxa de transferência. Os "Point-in-time Snapshots" são bons para replicação em estado estável, proporcionando, assim, baixa latência. Usando um ou outro, conforme a situação, podemos obter uma replicação mestre-escravo com alta taxa de transferência e baixa latência.
Autor

Sundar Sridharan, engenheiro de software sênior