Ninguém duvida que a indexação e a consulta de Big Data são desafiadoras. O Big Data chega até você rapidamente, com alta velocidade, variedade e volume! 100 mil atualizações por segundo e TBs de dados a serem verificados - não é possível fazer isso em tempo real a menos que você tenha uma indexação sólida! Imagine esses aplicativos:
- O aplicativo de viagem que define preços e registra todos os voos e hotéis que você consultou!
- O jogo on-line viral que precisa exibir o placar preciso para os melhores jogadores!
- O aplicativo de detecção de fraude que precisa examinar sua atividade recente para decidir se a transação de cartão de crédito ativa é legítima!
Esses são casos de uso para consultas que precisam lidar com uma alta ingestão de dados, mas não podem se comprometer com milissegundos como tempo de resposta! Se você não puder renderizar o roteiros de viagem, os placares ou responder a uma fraude em tempo realSe você não tiver uma aposta, todas as apostas estão canceladas! Ok! Isso parece impossível e você pergunta: "Como você indexa e consulta esses tipos de dados em tempo real?"
Indexação em sistemas de banco de dados distribuídos
Os sistemas distribuídos oferecem dois tipos de indexação;
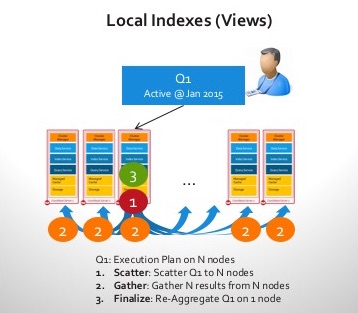
- Índices locais: No cluster, cada nó indexa os dados que mantém localmente. Isso otimiza a indexação rápida. No entanto, à medida que a ingestão de dados aumenta, a manutenção do índice localmente compete com a carga de trabalho recebida e, à medida que o cluster fica maior (mais nós), a dispersão atinge a latência da consulta. Imagine esta consulta: "Encontre os 10 principais usuários mais ativos do mês de agosto“
|
1 2 3 4 5 6 7 8 9 10 |
#SQL would look something like this SELECT customer_name, total_logins.jan_2015 FROM customer_bucket WHERE type=“customer_profile” ORDER BY total_logins.jan_2015 DESC LIMIT 10; #index for the query would look something like this INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile”; |
Aqui estão as etapas assim que a consulta é recebida em um cluster com um índice local:
- Nenhum nó sabe a resposta! Portanto, é necessário que o Scatter descubra o "TOP 10" em cada nó localmente usando o índice local.
- O Gather leva os "TOP 10″ de volta ao nó de coordenação.
- A etapa final é reordenar e descobrir os 10 usuários ativos mais próximos, combinando os resultados de todos os nós e enviando os resultados de volta ao cliente.
Vamos supor que isso tenha sido feito em 100 nós e que você tenha adicionado o 101º nó! Nada fica mais rápido ao executar essa consulta. Cada nó ainda faz o mesmo trabalho, inclusive o novo nó. De fato, o 101º nó prejudica a latência da consulta!
A propósito, o Couchbase Server faz indexação local. Isso se chama Map/Reduce Views e é fantástico para aplicativos complexos de relatórios interativos e aplicativos de painel que podem suportar segundos de latência. Veja mais sobre visualizações aqui.
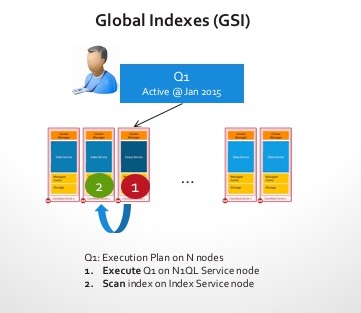
- Índices globais: O índice é particionado de forma independente e colocado longe dos dados nos nós. Pode ser desafiador acompanhar as mutações, pois a indexação dos dados exigirá um acesso à rede. No entanto, os índices globais funcionam de forma fantástica para consultas. Imagine a mesma consulta acima. O índice agora está em um nó ou dois (talvez particionado por continentes, como no exemplo abaixo)
|
1 2 3 4 5 6 7 8 9 10 |
#index for the query would look something like this INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile” AND continent="Europe"; INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile” AND continent="America"; INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile” AND continent="Asia"; |
Aqui estão as etapas assim que a consulta é recebida em um cluster com um índice global:
- Agora temos um nó com o índice global que sabe a resposta! Portanto, não há necessidade de dispersão aqui! Simplesmente recuperamos a contagem de login superior do índice.
- A etapa final é enviar os resultados de volta para o cliente.
Com os 100 nós do exemplo anterior, seu 101º nó agora pode trabalhar de verdade! As latências de consulta são muito mais rápidas!
No Couchbase Server, os GSIs também podem ser implantados de forma independente em uma zona separada dentro do cluster usando o serviço de índice. Isso significa que os nós de serviço de dados que estão realizando as operações de dados principais (INSERT/UPDATE/DELETE) não precisam competir com a indexação que ocorre em outra parte do cluster. Chamamos essa topologia de implementação de MDS e você pode saber mais sobre ela aqui.
Você também pode encontrar uma discussão mais detalhada sobre as diferenças entre Map/Reduce Views e GSI e suas arquiteturas aqui.
O Couchbase Server fornece GSI (índices secundários globais) que funciona dessa forma. O Couchbase Server oferece duas opções de armazenamento para GSIs: GSI padrão e GSI otimizado para memória. O GSI padrão está disponível desde a versão 4.0. No entanto, o GSI otimizado para memória é novo na versão 4.5. Em PARTE II desta postagem, você pode leia sobre índices globais otimizados para memória e como eles são diferentes.