
No one doubts that indexing and query with big data is challenging. Big data comes at you fast, with high velocity, variety and volume! 100Ks of updates/sec and TBs of data to scan – you cannot do this real-time unless you have solid indexing! Imagine these apps:
- The travel app that is pricing & recording all the flights and hotels you looked at!
- The viral online game that has to display the accurate score-board for top players!
- The fraud detection app that needs to look at your recent activity to decide if the active credit-card transaction is a legitimate one!
These are use cases for queries that need to deal with high ingest of data but cannot compromise on milliseconds as the response time! If you cannot render the travel-itineraries, the score-boards or respond to a fraud in real time, all bet are off! Okay! this sounds impossible and you ask: “How do you index and query this types of data in real time?”
Indexing in Distributed Database Systems
Distributed systems offer 2 types of indexing;
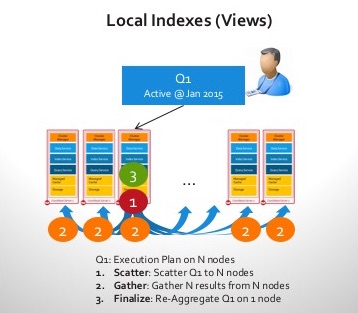
- Local indexes: In the cluster, each node indexes the data it locally holds. This optimizes for indexing fast. However as the data ingest increases, index maintenance locally competes with the incoming workload and as the cluster gets larger (more nodes) the scatter gather hits the query latency. Imagine this query: “Find the top 10 most active users for month of Aug“
|
1 2 3 4 5 6 7 8 9 10 |
#SQL would look something like this SELECT customer_name, total_logins.jan_2015 FROM customer_bucket WHERE type=“customer_profile” ORDER BY total_logins.jan_2015 DESC LIMIT 10; #index for the query would look something like this INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile”; |
Here are the steps as soon as the query get received on a cluster with a local index:
- No one node knows the answer! SO Scatter is required to figure out “TOP 10” on each node locally using the local index.
- Gather gets the “TOP 10″s back to the coordinating node.
- Final step is to re-sort and figure out the rela TOP 10 active users, combining the results from all nodes and send the results back to the client.
Lets assume this was done over a 100 nodes and you added your 101st node! Nothing gets faster on executing this query. Every node still does the same work including the new node. In fact 101st node hurts the latency of the query!
By the way, Couchbase Server does local indexing. It is called Map/Reduce Views and they are fantastic for complex interactive reporting apps and dashboard apps that can put up with seconds of latency. See more about views here.
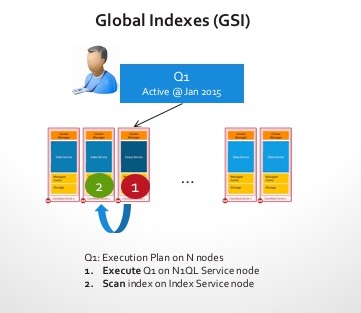
- Global Indexes: The index is independently partitioned and placed away from the data on the nodes. It can be challenging to keep up with mutations, as indexing the data will require a network access. However global indexes works fantastically for queries. Imagine the same query above. The index now sits on a node or two (maybe partitioned by continents as the example below)
|
1 2 3 4 5 6 7 8 9 10 |
#index for the query would look something like this INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile” AND continent="Europe"; INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile” AND continent="America"; INDEX ON Customer_bucket(customer_name, total_logins.jan_2015) WHERE type=“customer_profile” AND continent="Asia"; |
Here are the steps as soon as the query get received on a cluster with a global index:
- Now we have a node with the global index that knows the answer! SO no scatter required here! We simply retrieve the top login count from the index.
- Final step is to send the results back to the client.
Those 100 nodes in the previous example, your 101st node can now do real work! Query latencies are much faster!
In Couchbase Server, GSIs can also be deployed independently to a separate zone within the cluster using the index service. That means data service nodes that are doing the core data operations (INSERT/UPDATE/DELETE) don’t have to compete with the indexing that goes on in the other part of the cluster. We call this deployment topology MDS and you can find more about it here.
You can also find a more detailed discussion of differences in Map/Reduce Views vs GSI and their architectures here.
Couchbase Server provides GSI (global secondary indexes) that works this way. Couchbase Server provides 2 storage options for GSIs: standard GSI and memory-optimized GSI. Standard GSI has been available since 4.0. However memory optimized GSI is new with 4.5. In PART II of this post, you can read about memory optimized global indexes and how they are different.
Happy Hacking
-Cihan