Os bancos de dados distribuídos aplicam os princípios da computação distribuída ao armazenamento de dados. O exemplo mais simples é um banco de dados que armazena dados em dois (ou mais) servidores conectados por uma rede. Esse "cluster" pode ser acessado e gerenciado como se fosse um único servidor de banco de dados.
O modelo tradicional de servidor único de um banco de dados, em comparação, existe em um único servidor.
Os principais benefícios do uso da arquitetura de banco de dados distribuído para serviços incluem:
- Clustering para lidar com a carga (dimensionamento horizontal)
- Alta disponibilidade (se um servidor ficar off-line, os demais servidores permanecerão on-line e disponíveis)
- Replicação (para dar suporte à alta disponibilidade, recuperação de desastres e distribuição geográfica)
Há muitas práticas recomendadas para bancos de dados distribuídos, incluindo diferentes opções, topologias e métodos para distribuir a carga entre os servidores. Então, como funcionam os bancos de dados distribuídos?
Escala horizontal
Historicamente, um único servidor de banco de dados para um pequeno conjunto de aplicativos e dados tem funcionado bem. No entanto, quando exposto a uma grande base de usuários públicos, a única maneira de aumentar a capacidade desses servidores é atualizá-los para um servidor mais caro.
Para aumentar a capacidade, mova o software do banco de dados para outra máquina com mais memória, mais espaço em disco e mais processadores. Esse é o "escalonamento vertical". A desvantagem dessa abordagem é que ela pode exigir tempo de inatividade. Há também um limite máximo para o desempenho que pode ser obtido em uma única máquina. (Consulte o artigo de Herb Sutter O almoço grátis acabou).
Infelizmente, muitos bancos de dados, especialmente os bancos de dados relacionais (RDBMS), não foram projetados para serem distribuídos e agrupados em clusters.
Entretanto, os bancos de dados distribuídos são criados desde o início para oferecer suporte à escalabilidade elástica. Precisa adicionar mais recursos para lidar com mais carga? Instale o software do banco de dados em uma ou mais máquinas adicionais e adicione-as ao cluster.
Em seguida, adicione máquinas de commodity de baixo custo ao cluster quando necessário. Você também pode removê-las e reduzir a escala se não precisar mais delas.
Arquitetura de banco de dados distribuído
Para bancos de dados, há duas abordagens populares para a distribuição de dados: primária/secundária (historicamente chamada de mestre/escravo) e nada compartilhado (às vezes chamado de masterless).
Arquitetura primária/secundária
Em uma arquitetura primária/secundária, há um servidor "primário" designado. Esse servidor armazena todos os dados e processa todas as solicitações de dados. Há um ou mais servidores "secundários". Esses servidores receberão atualizações de dados do primário para manter a sincronia e armazenar uma réplica completa dos dados.
Se o servidor primário ficar off-line (falhar), os servidores restantes (e/ou os servidores de coordenação) indicarão um dos servidores secundários para ser o novo primário.
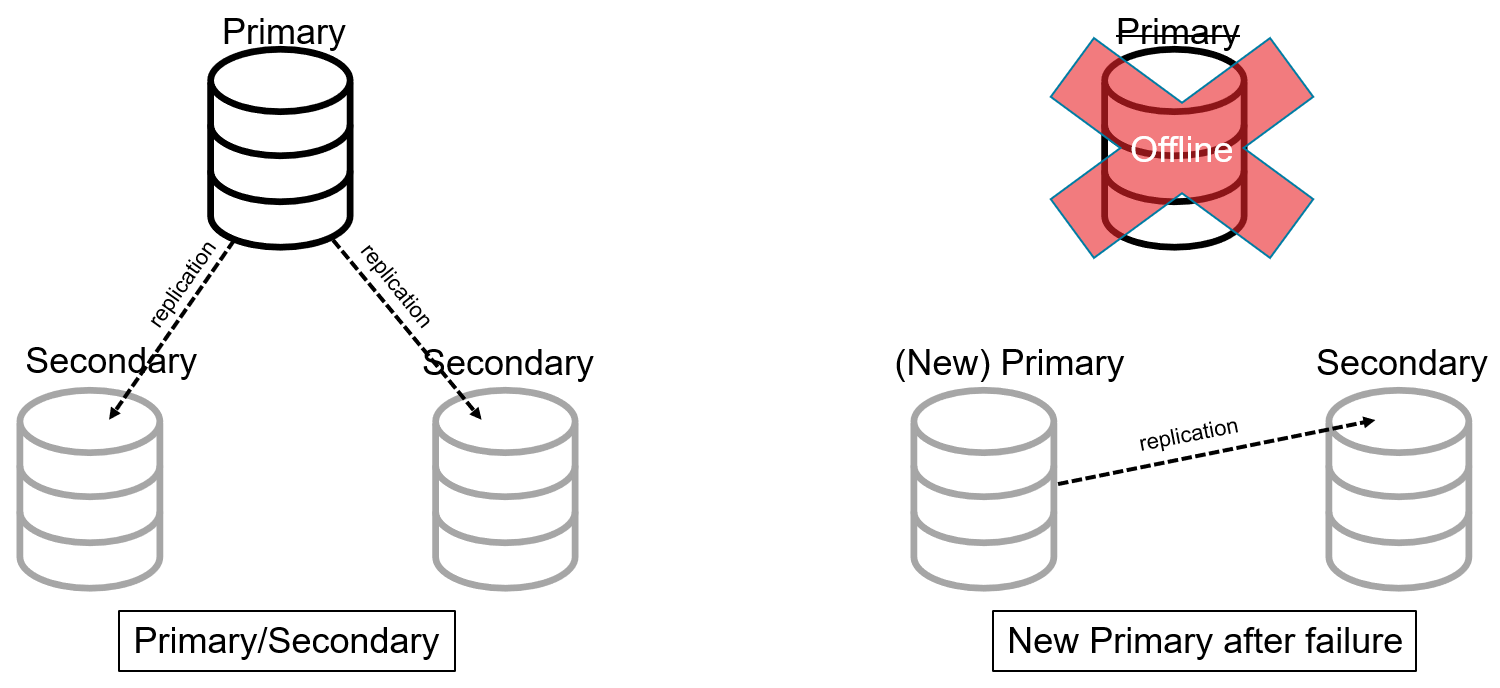
Os arquitetos usam esse padrão para fornecer alta disponibilidade em relação aos bancos de dados tradicionais e não distribuídos. No entanto, essa arquitetura de banco de dados distribuído não faz muito para resolver o problema do aumento da carga. Para conseguir isso, fragmentação deve ser usado.
Bancos de dados distribuídos sem compartilhamento
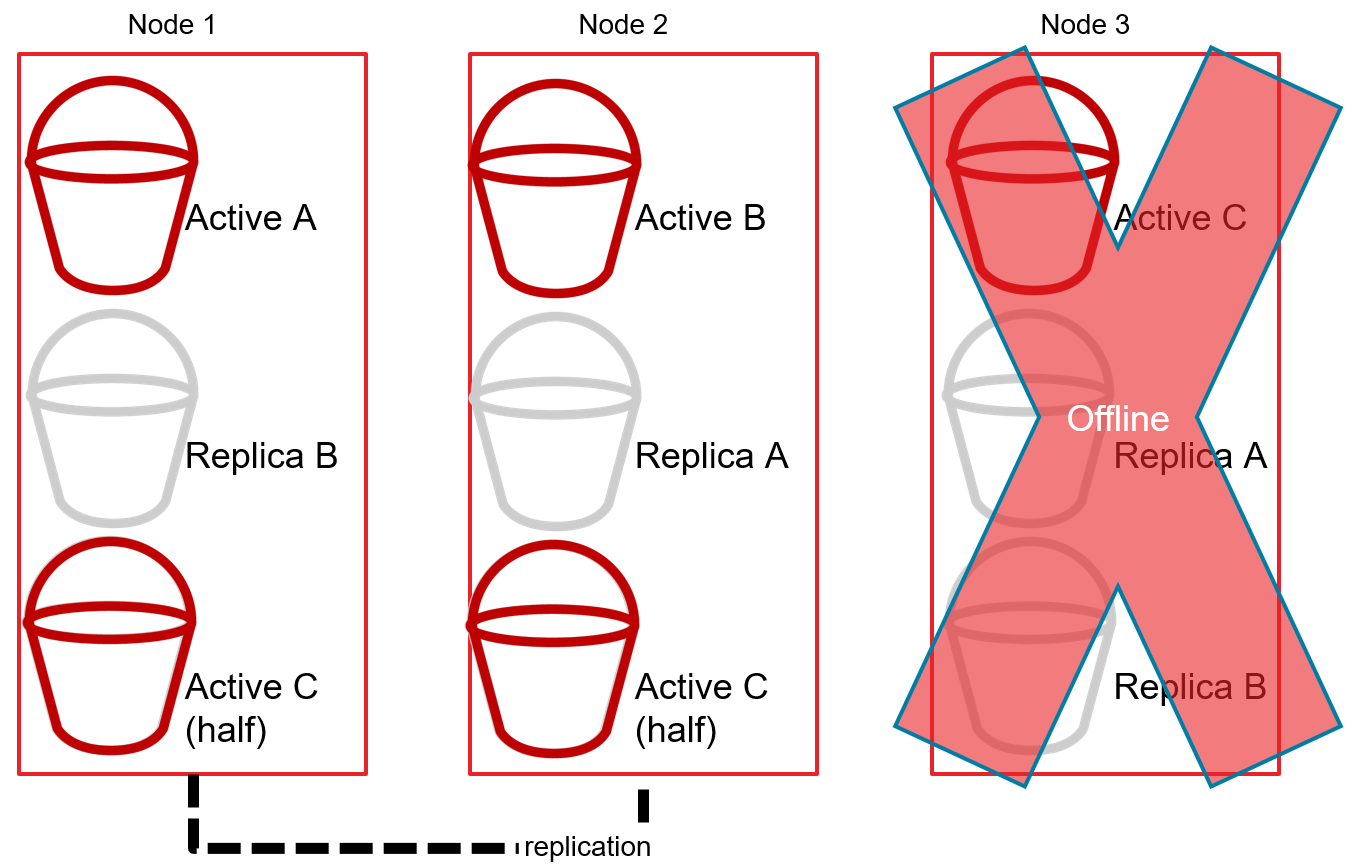
A arquitetura sem compartilhamento envolve a divisão dos dados em partições geralmente chamadas de "shards". Cada shard reside em um servidor individual (nó) no cluster. Por exemplo, se houver 300 registros e 3 nós, cada nó armazenaria (idealmente) 100 registros. Cada nó adicional poderia particionar ainda mais os dados e continuar distribuindo a carga conforme necessário.
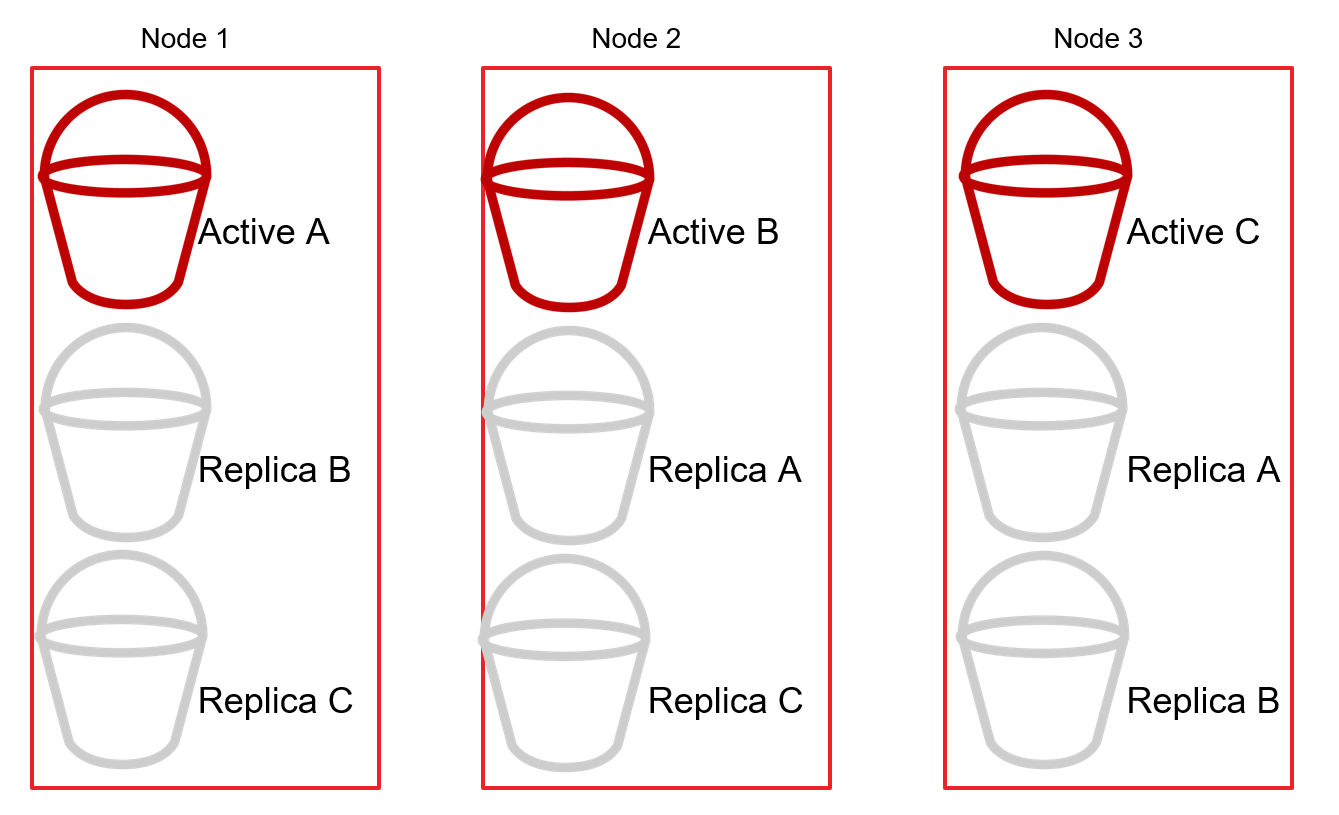
O cluster também replicará os fragmentos entre os nós para manter a alta disponibilidade. Por exemplo, se o nó 1 contiver o fragmento ativo A, o nó 2 conterá um fragmento de réplica A e assim por diante.
Então, se o Nó 3 ficar off-line, o cluster promoverá as réplicas do Fragmento C para Ativo a fim de manter o cluster de BD distribuído on-line (como um todo).
A natureza dos bancos de dados relacionais é armazenar linhas individuais de dados em uma tabela firmemente acoplada. Isso dificulta a distribuição de bancos de dados SQL. É por isso que as organizações geralmente escolhem o NoSQL quando o clustering, a alta disponibilidade e a replicação são essenciais. O NoSQL troca dados estritamente acoplados que não podem existir fora de uma tabela por dados independentes que podem existir em qualquer fragmento em um cluster.
Exemplos de bancos de dados distribuídos
Dependendo do banco de dados distribuído que você usa, o sharding pode ser totalmente automático ou exigir um esforço considerável de planejamento e manutenção.
Vamos dar uma olhada em dois exemplos de bancos de dados distribuídos que usam o popular NoSQL e como eles se diferenciam:
Servidor Couchbase
O Couchbase Server é um banco de dados NoSQL distribuído que armazena dados como partes individuais de dados JSON chamados documentos. Cada documento tem uma chave exclusiva.
Cada documento existe em um fragmento (chamado vBuckets no Couchbase), e cada shard é atribuído a um nó. Um cluster do Couchbase tem uma quantidade fixa de 1024 vBuckets no total.
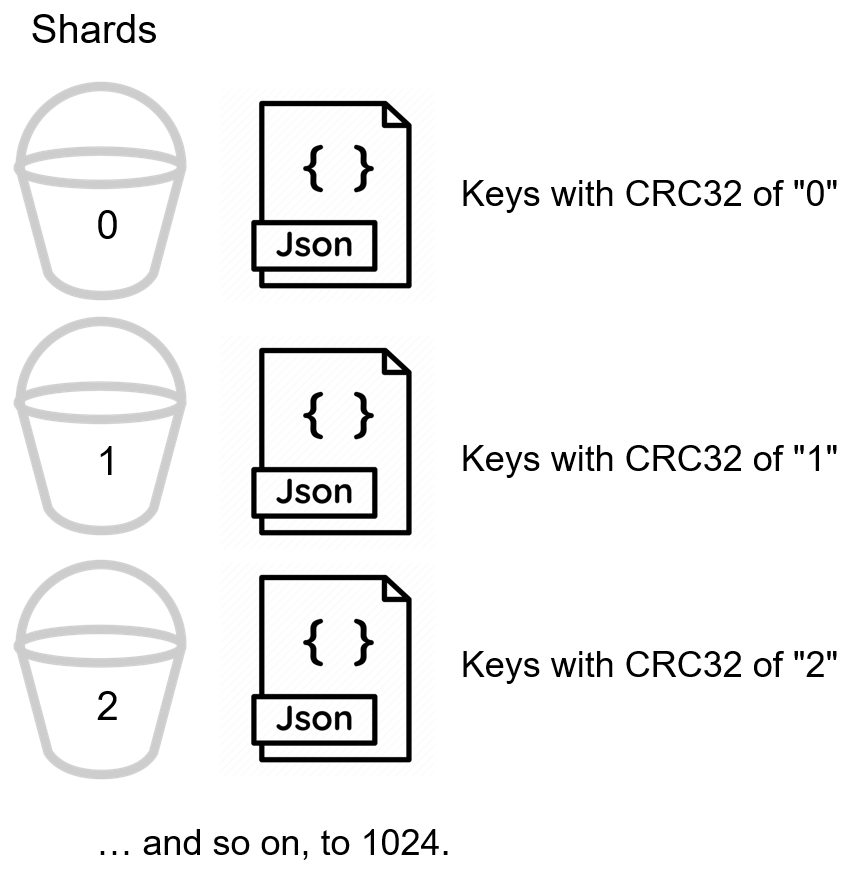
Couchbase automaticamente atribui um documento ao vBucket com base em sua chave (usando um algoritmo de hash CRC32). Não é necessário que os desenvolvedores, DBAs ou DevOps criem e gerenciem a fragmentação. Cada nó tem um gerente de cluster que garante que todos os shards permaneçam equilibrados e que os dados sejam distribuídos de forma homogênea. Não haverá "pontos quentes": um nó armazenando quantidades muito maiores de dados do que outros nós. Não há necessidade de outros servidores para processar o roteamento de consultas ou fornecer uma fachada de balanceamento de carga além do cluster do Couchbase Server.
MongoDB
O MongoDB também é um banco de dados NoSQL distribuído. Ele também armazena dados como partes individuais em um formato semelhante para JSON chamado BSON. Cada documento tem uma chave exclusiva.
O MongoDB adota uma abordagem diferente para o sharding. Para fragmentar os dados, você deve selecionar uma chave de fragmentação (que consiste em uma ou mais partes de dados BSON). Por exemplo, você pode considerar a fragmentação de dados por "sobrenome" e "código postal".
Depois de definir uma chave de fragmento, o Mongo encaminha as solicitações do cliente por meio de outro servidor que está executando um "roteador de consulta". Esse roteador de consulta fará referência a outro servidor chamado "servidor de configuração". Ele pode então determinar em qual servidor de dados está o fragmento desejado.
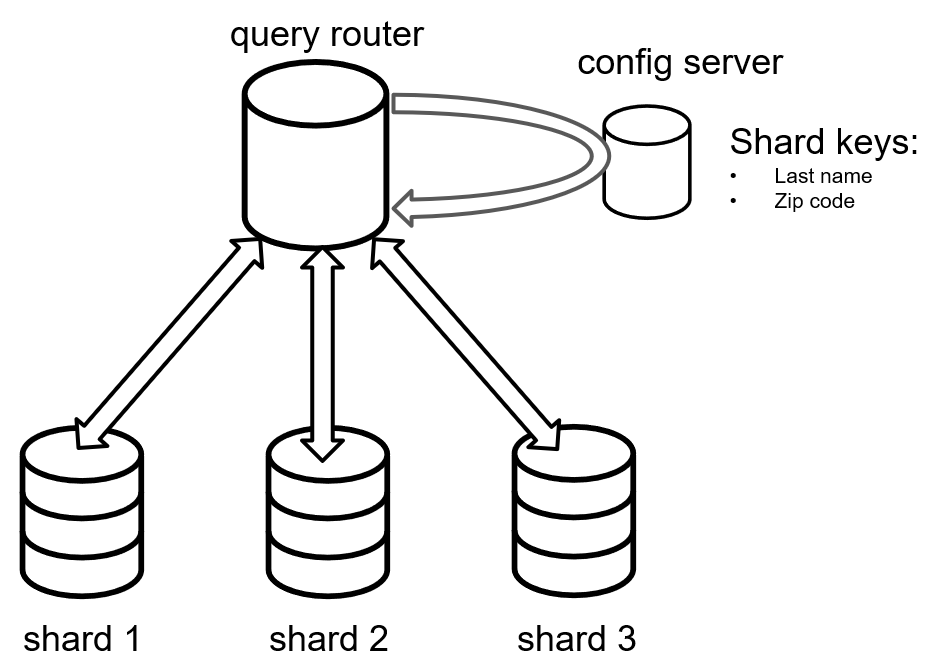
O processo de fragmentação não é automático. A equipe de desenvolvimento deve escolher cuidadosamente as chaves de fragmentação e revisá-las periodicamente para evitar gargalos e pontos críticos.
Resumo
Esses são apenas dois exemplos notáveis de bancos de dados distribuídos. Há muitos outros exemplos que adotam uma variedade de abordagens de arquitetura.
O que todos eles têm em comum é o fato de armazenarem dados em servidores conectados à rede.
Interessado na abordagem de fragmentação automática que o Couchbase Server está adotando? Isso é apenas o começo do que o Couchbase pode fazer. Com uma arquitetura integrada que prioriza a memória, pesquisa de texto completo, recursos de consulta SQL distribuída e muito mais, o Couchbase é uma plataforma de dados completa. Faça o download do Couchbase Server hoje mesmo e experimente.
[...] para armazenar seus dados e evitar que eles monitorem seus arquivos e documentos importantes. Visite sites como https://www.couchbase.com/distributed-databases-overview/ para saber mais sobre [...]