
Distributed databases apply the principles of distributed computing to data storage. The simplest example is a database which stores data on two (or more) servers connected by a network. This “cluster” can be accessed and managed as if it was a single database server.
The traditional single server model of a database, in comparison, exists on one server.
The primary benefits of using distributed database architecture for services include:
- Clustering to handle load (horizontal scaling)
- High availability (if one server goes offline, the remaining servers stay online and available)
- Replication (to support high availability, disaster recovery, and geographical distribution)
There are many best practices for distributed databases, including different options, topologies, and methods to distribute the load between the servers. So, how do distributed databases work?.
Horizontal Scaling
A single database server for a small set of applications and data has historically worked well. However, when exposed to a large, public user base, the only way to increase capacity of these servers is to upgrade them to a more expensive server.
To improve capacity, move the database software to another single machine with more memory, more disk space, and more processors. This is “vertical scaling”. The drawback to this approach is that it may require downtime. There’s also a ceiling on the performance that can be obtained from a single machine. (See Herb Sutter’s The Free Lunch is Over).
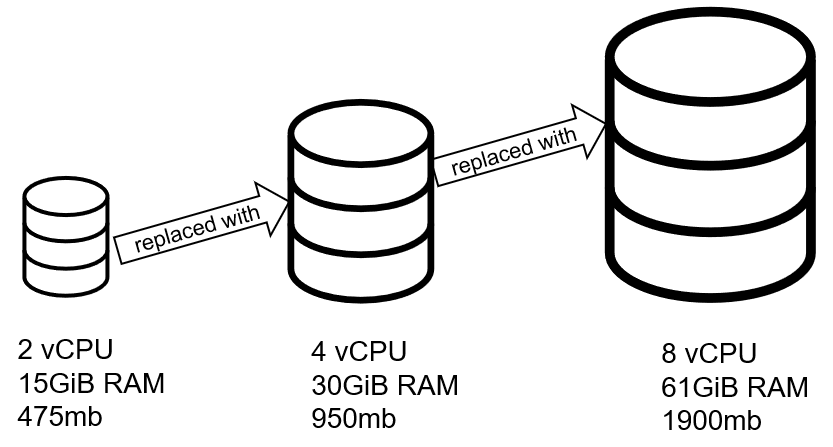
Unfortunately, many databases, especially relational (RDBMS) databases are not designed to be distributed and clustered.
However, distributed databases are created from the start to support elastic scalability. Need to add more resources to handle more load? Install the database software on 1 or more additional machines and add it to the cluster.
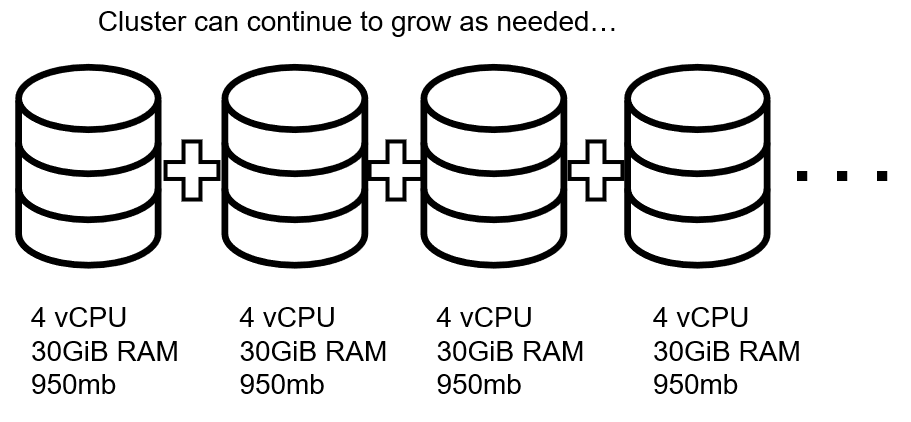
Then, add inexpensive commodity machines to the cluster when necessary. You can also remove them and scale down if you no longer need them.
Distributed Database Architecture
For databases, there are two popular approaches for distributing data: primary/secondary (historically called master/slave) and shared-nothing (sometimes called masterless).
Primary/Secondary Architecture
In a primary/secondary architecture, there is a designated “primary” server. This server stores all the data and handles all data requests. There are one or more “secondary” servers. These servers will receive data updates from the primary in order to stay in sync and store a complete replica of the data.
If the primary server goes offline (crashes), the remaining servers (and/or coordination servers) appoint one of the secondary servers to be the new primary.
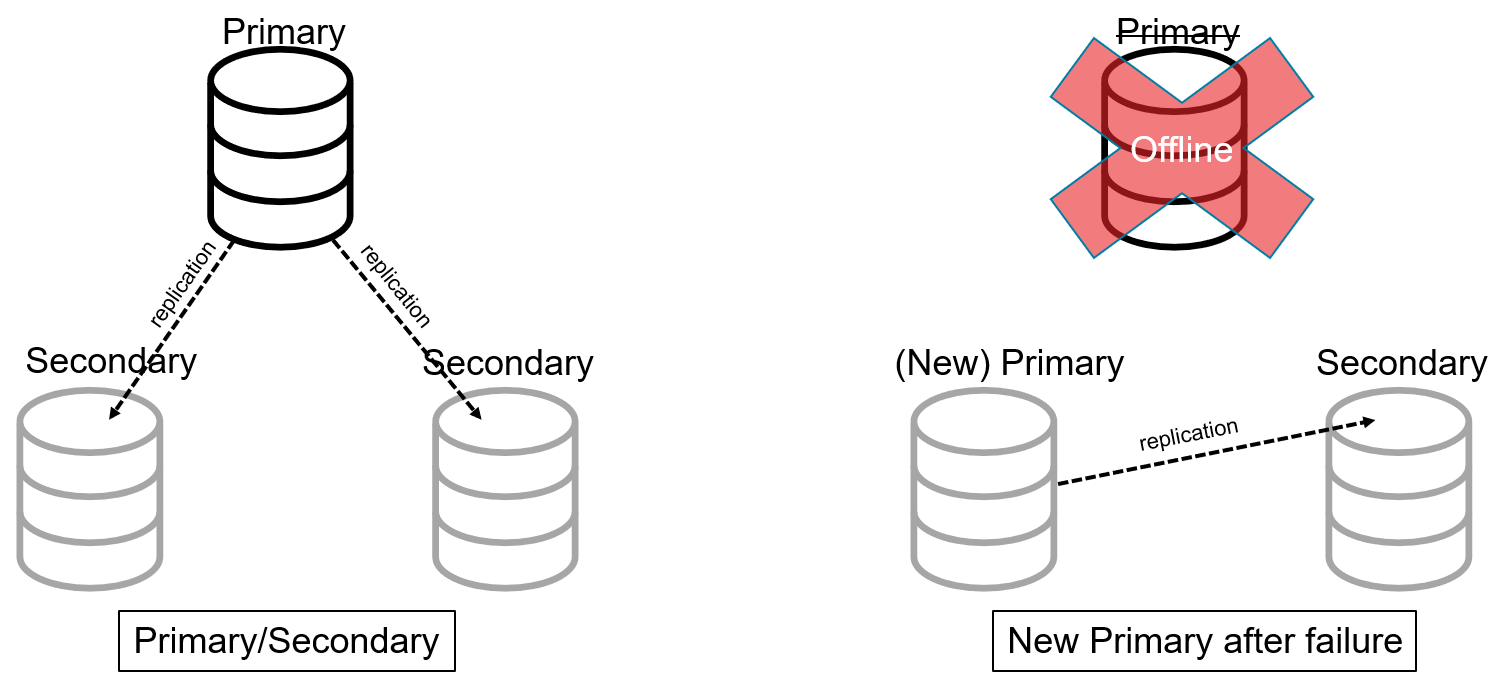
Architects use this pattern to provide high availability to traditional, non-distributed databases. However, this distributed database architecture doesn’t do much to address to issue of increased load. In order to accomplish that, sharding must be used.
Shared-nothing distributed databases
Shared-nothing architecture involves splitting the data into partitions usually called “shards”. Each shard lives on an individual server (node) in the cluster. For example, if there are 300 records and 3 nodes, each node would (ideally) store 100 records. Each additional node could further partition the data and continue spreading out the load as necessary.
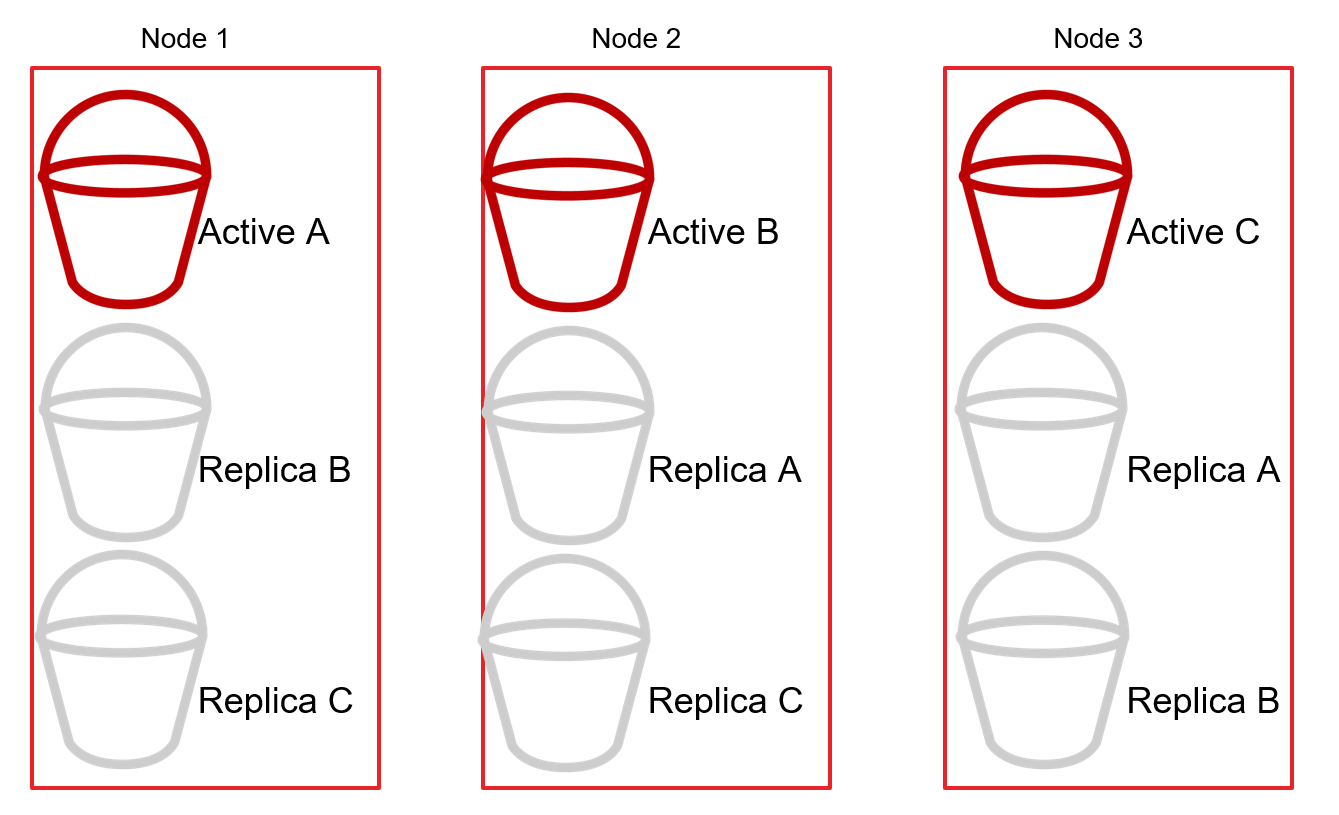
The cluster will also replicate shards between the nodes to maintain high availability. For instance, if Node 1 contains Active Shard A, then Node 2 would contain a Replica Shard A, and so on.
Then, if Node 3 goes offline, the cluster promotes the replicas from Shard C to Active in order to keep the distributed DB cluster online (as a whole).
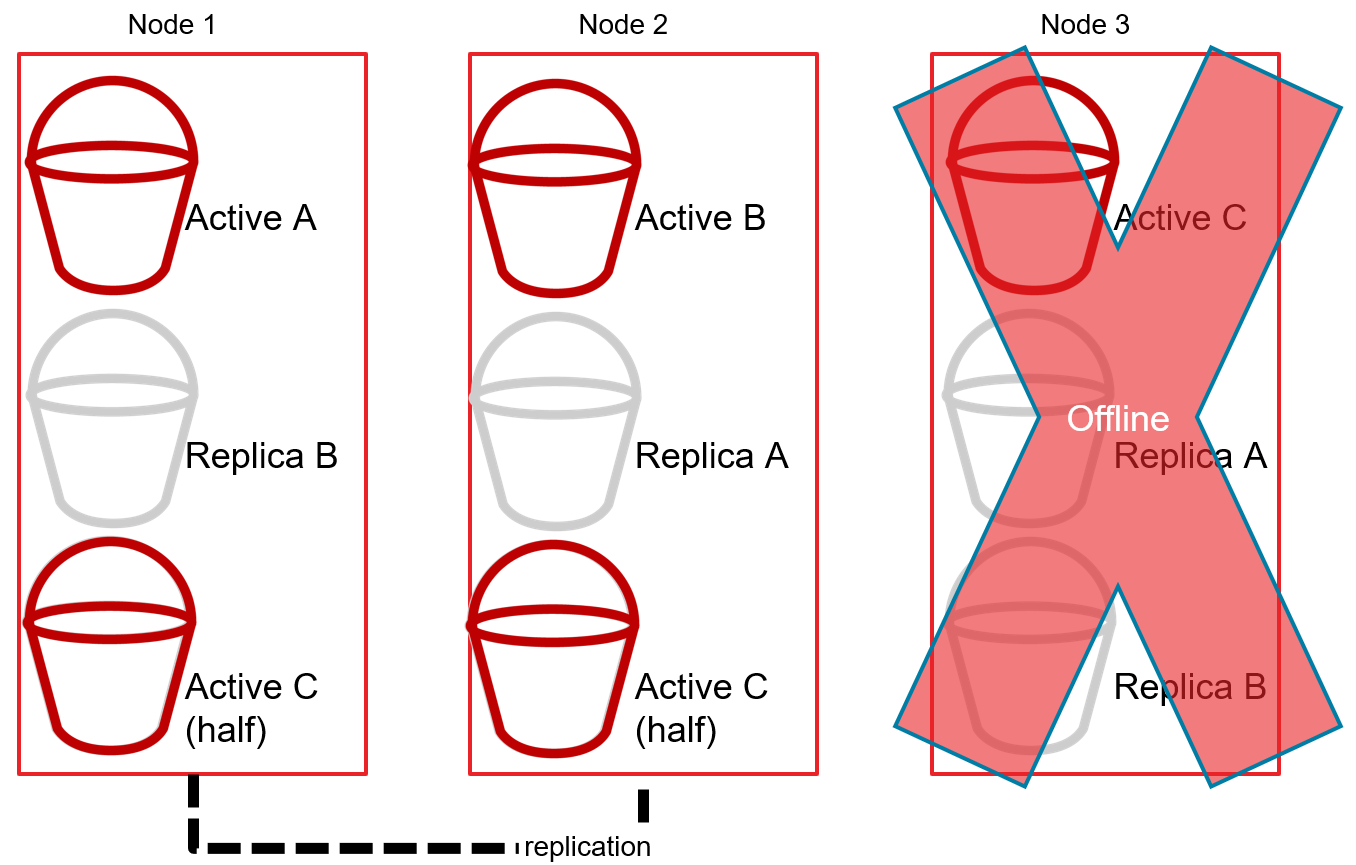
The nature of relational databases is to store individual rows of data together in a tightly coupled table. This makes distributed SQL databases difficult. This is why organizations often choose NoSQL where clustering, high-availability, and replication are critical. NoSQL trades off strictly coupled data that cannot exist outside a table in exchange for independent data that can exist in any given shard in a cluster.
Distributed Database Examples
Depending on the distributed DB that you use, sharding may be completely automatic or require considerable effort to plan and maintain.
Let’s look at two examples of distributed databases that use the popular NoSQL and how they differ:
Couchbase Server
Couchbase Server is a distributed NoSQL database that stores data as individual pieces of JSON data called documents. Each document has a unique key.
Each document exists within a shard (called vBuckets in Couchbase), and each shard is assigned to a node. A Couchbase cluster has a fixed amount of 1024 total vBuckets.
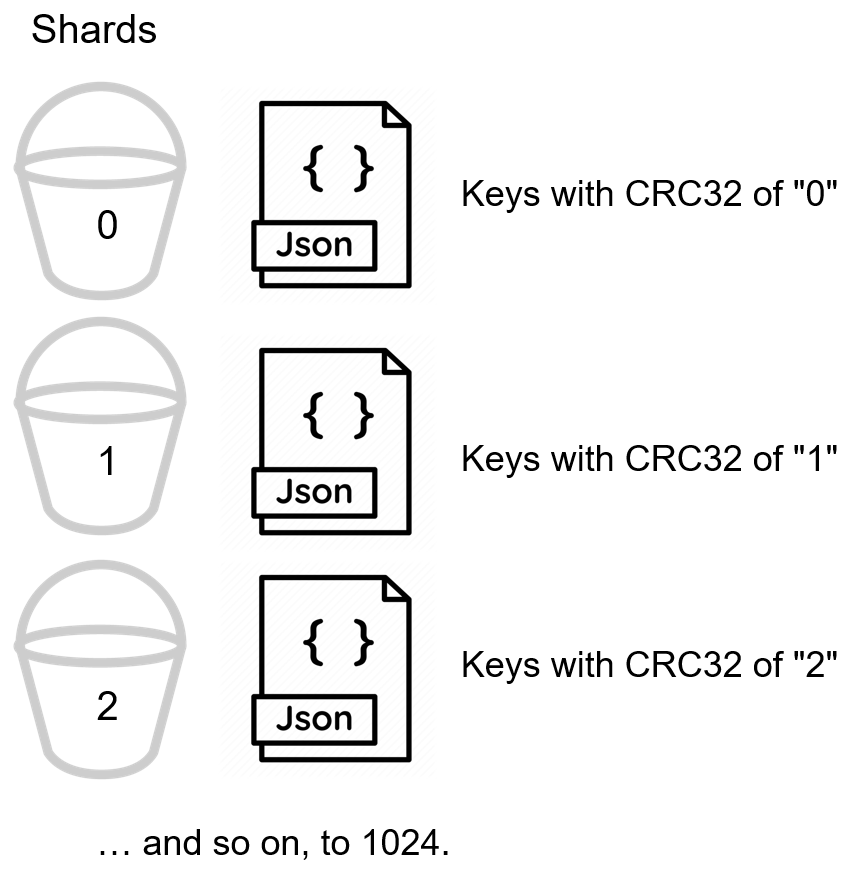
Couchbase automatically assigns a document to vBucket based on its key (using a CRC32 hashing algorithm). There is no need for developers, DBAs, or DevOps to create and manage sharding. Each node has a cluster manager that ensures all the shards remain in balance and the data is evenly distributed. There will be no “hot spots”: one node storing much larger amounts of data than other nodes. There is no need for other servers to process query routing or provide a load balancing facade apart from the Couchbase Server cluster.
MongoDB
MongoDB is also a distributed NoSQL database. It also stores data as individual pieces in a format similar to JSON called BSON. Each document has a unique key.
MongoDB takes a different approach to sharding. In order to shard data, you must select a shard key (consisting of one or more pieces of BSON data). For instance, you might consider sharding data by “last name” and “zip code”.
Once you’ve defined a shard key, Mongo routes client requests though another server that’s running a “query router”. This query router will refer to yet another server called a “config server”. It can then determine which data server that the desired shard is on.
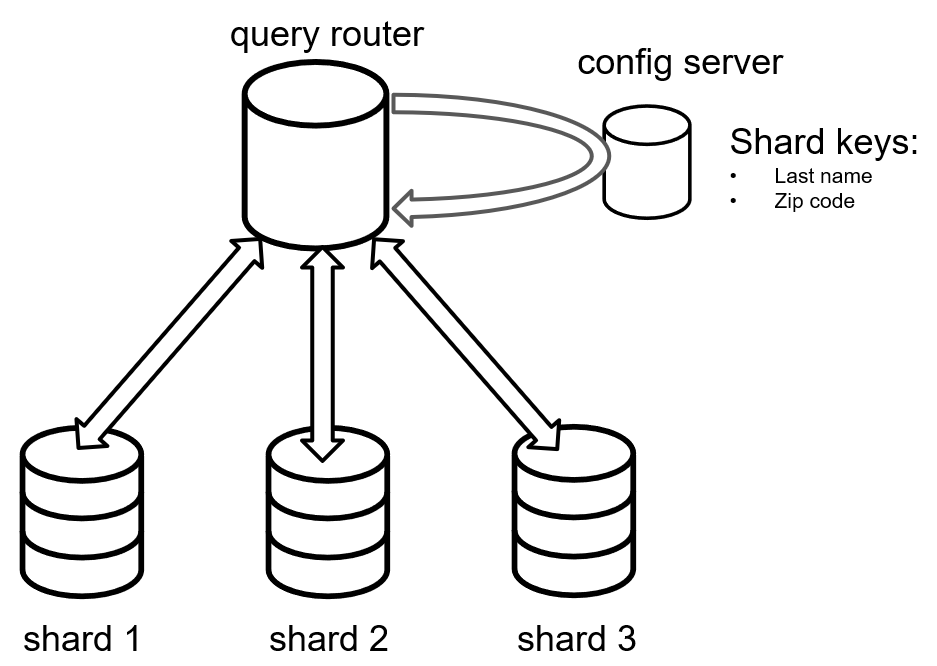
The sharding process is not automatic. The development team must choose shard keys carefully and periodically review them in order to avoid bottlenecks and hot spots.
Summary
These are just two notable distributed database examples. There are many more examples that all take a variety of approaches to architecture.
What they all have in common is that they store data on network connected servers.
Interested in the automatic sharding approach that Couchbase Server is taking? That’s just scratching the surface of what Couchbase can do. With a built-in memory-first architecture, full text search, distributed SQL querying capabilities, and more, Couchbase is a complete data platform. Download Couchbase Server today and give it a try.
Author
1 Comment
-
[…] to store your data to avoid them monitoring your important files and documents. Visit sites like https://www.couchbase.com/distributed-databases-overview/ to know more about […]
Leave a comment
You must be logged in to post a comment.