Como defensor do desenvolvedor na CouchbaseEm minha viagem, frequentemente encontro pessoas que não têm ideia do que é NoSQL ou, mais importante, do que é Couchbase. Para as pessoas que já estão familiarizadas com o NoSQL, o Couchbase é frequentemente comparado a outros sistemas de armazenamento de dados. Banco de dados NoSQL produtos como o MongoDB e o CouchDB, que não são afiliados ao Couchbase.
Recentemente, deparei-me com uma série de comparações entre MongoDB e Couchbase feita por um autor da comunidade, Milan Milosevic. Em primeira parte e segunda parte de sua série, ele explica sua experiência, como desenvolvedor experiente de MongoDB, saindo do MongoDB e tentando usar o Couchbase. Opiniões válidas são compartilhadas, mas há alguns aspectos que podem ser ignorados.
Quero esclarecer algumas dúvidas sobre o que torna o Couchbase uma opção tão boa no espaço NoSQL.
Compartimentos e o documento JSON
Ao trabalhar com dados no Couchbase, você está trabalhando com eles como dados formatados em JSON. Esses dados JSON podem ser tão simples ou tão complexos quanto você quiser torná-los. Por exemplo, o seguinte é um documento JSON muito válido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "firstname": "Nic", "lastname" (sobrenome): "Raboy", "endereços": [ { "cidade": "São Francisco", "estado": "Califórnia" }, { "cidade": "Vista da montanha", "estado": "Califórnia" } ], "social": { "twitter": "https://www.twitter.com/nraboy", "blog": "https://www.thepolyglotdeveloper.com" } } |
Percebeu como no documento acima há matrizes aninhadas de objetos, bem como objetos aninhados? Ao trabalhar com documentos JSON, você tem mais flexibilidade no que diz respeito aos dados do que em um banco de dados relacional.
Cada documento JSON armazenado no Couchbase deve receber um valor de identificação exclusivo, também conhecido como chave. O Couchbase não criará essa chave para você, mas há muitas soluções disponíveis quando se trata do design da chave. Por exemplo, aqui estão três maneiras possíveis de criar uma chave:
Legível por humanos
|
1 |
garoto |
Gerado por computador ou incrementado
|
1 |
caa80375-77e7-4714-b90a-1089e66a5fd5 |
Combinação ou composto
|
1 |
garoto::1 |
Não há maneiras certas ou erradas de criar uma chave. O que realmente importa são as suas necessidades no documento específico que está salvando. A capacidade de criar sua própria chave é útil quando se trata de estabelecer relacionamentos de dados e consultar esses dados.
Cada documento JSON, com sua chave exclusiva, é salvo no que é chamado de Bucket do Couchbase. Provavelmente é seguro pensar em um Bucket como um balde literal no qual você pode armazenar coisas. Você pode colocar qualquer coisa nesse balde, independentemente de sua forma ou tamanho. O mesmo se aplica a um Bucket do Couchbase. Por exemplo, digamos que eu queira salvar os dois documentos a seguir:
|
1 2 3 4 5 |
{ "tipo": "pessoa", "firstname": "Nic", "lastname" (sobrenome): "Raboy" } |
Podemos dar ao documento acima qualquer chave exclusiva, o que realmente não importa para este exemplo. A mesma regra se aplica ao documento a seguir:
|
1 2 3 4 5 |
{ "tipo": "localização", "cidade": "São Francisco", "estado": "Califórnia" } |
Em ambos os documentos, você notará que cada um deles tem um tipo com um valor diferente. Além disso, cada nome de propriedade é completamente diferente, indicando que esses documentos têm finalidades diferentes. Embora não seja totalmente necessário, o tipo nos ajuda ao consultar esses documentos.
Ter uma quantidade X de tipos de documentos em um único Bucket torna as coisas mais complicadas ou confusas? Absolutamente não, pois o que importa é a consulta, e não como os documentos são armazenados.
Quando se trata do MongoDB, você armazenaria cada tipo de documento em sua própria coleção e, da mesma forma, em um RDBMS, onde você armazenaria cada um em sua própria tabela. Isso significa que o MongoDB e um banco de dados relacional como o Oracle estão fazendo isso errado ou são melhores que o Couchbase? Não, isso não significa, é apenas a maneira deles de resolver o problema.
Couchbase Shell (CBQ) e o Query Workbench
Portanto, com os dados JSON no Couchbase, será necessário consultá-los ou até mesmo criar mais deles. Há várias maneiras de consultar dados no Couchbase e com várias ferramentas diferentes.
Com o Couchbase Enterprise Edition e o Community Edition, você tem o que é chamado de Workbench de consultaque é uma ferramenta gráfica para executar consultas, semelhante ao que você encontraria no phpMyAdmin ou no SQL Developer da Oracle.
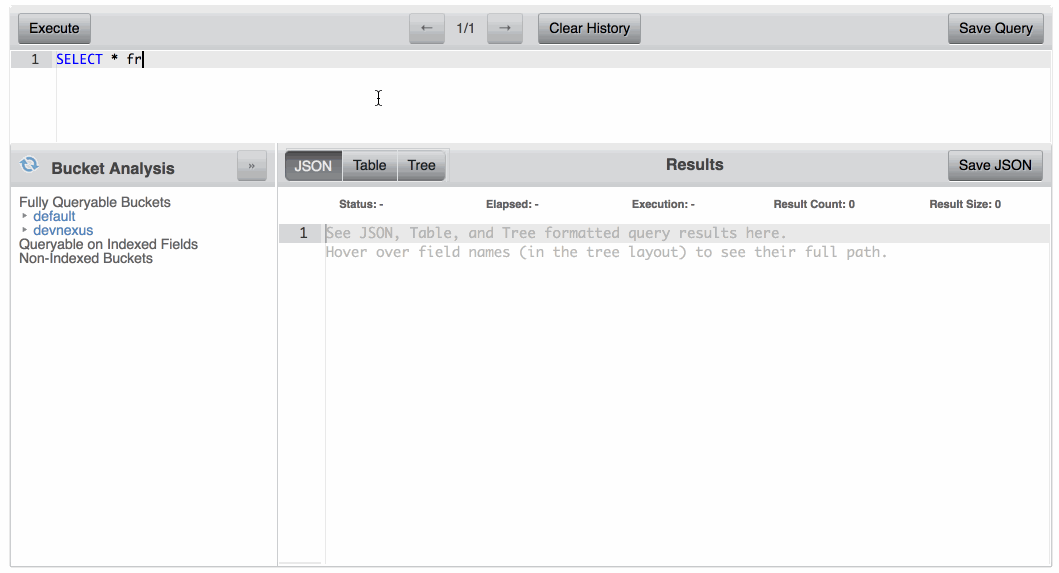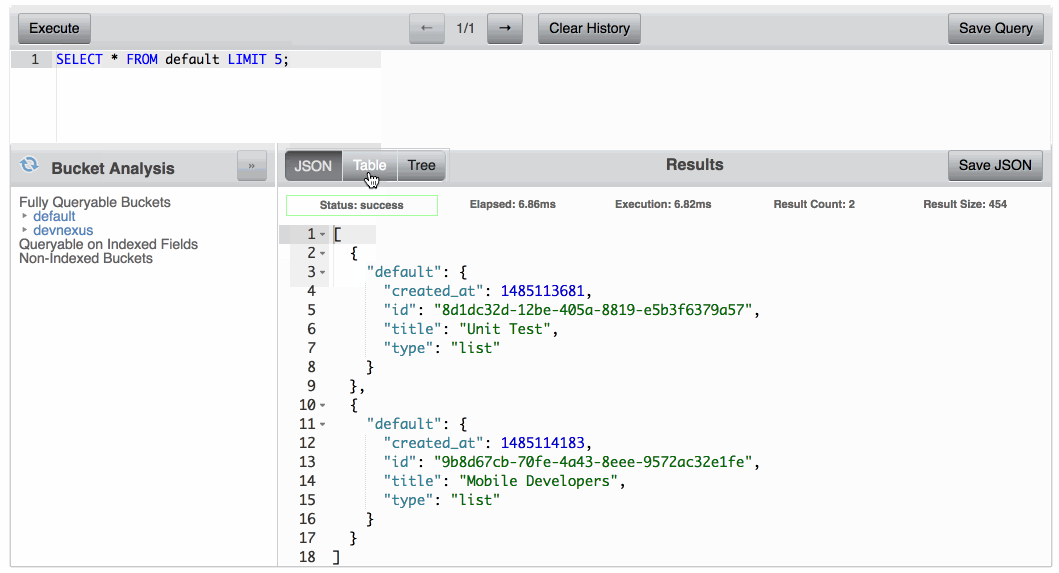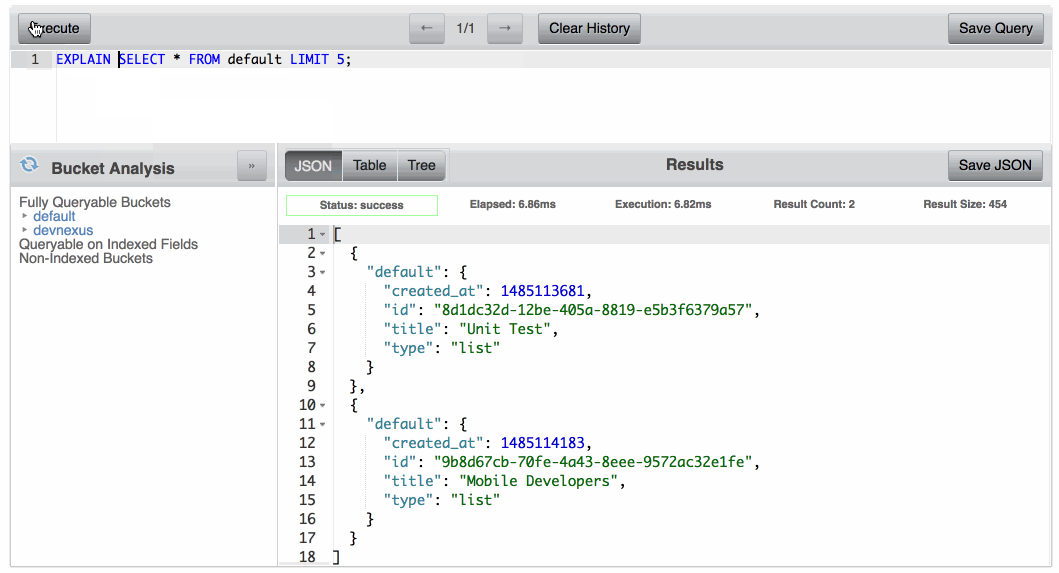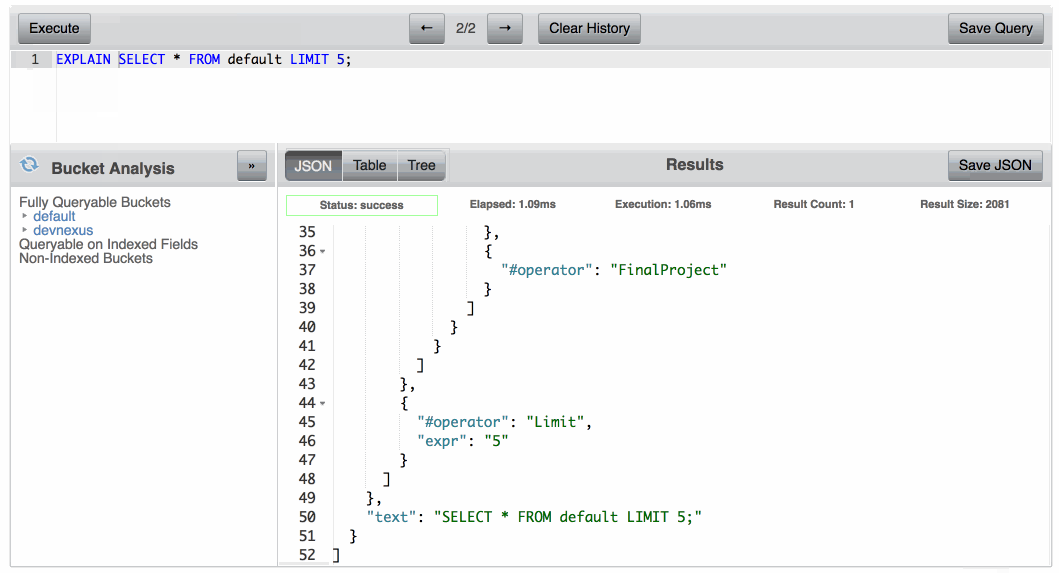
Com o Query Workbench, você pode executar consultas N1QL do Couchbase em relação aos documentos encontrados em cada um dos seus Buckets. Essas consultas podem incluir SELECIONAR, INSERIRou qualquer outro comando de consulta que seja popular em linguagens baseadas em SQL. Por exemplo, a consulta a seguir retornará todas as propriedades de todos os documentos encontrados no Bucket do Couchbase chamado padrão:
|
1 |
SELECT * DE padrão; |
Embora cada tecnologia NoSQL tenha seus próprios métodos de consulta de dados, o N1QL não só é fácil de usar, como também é mais conveniente para aqueles que estão se afastando de um banco de dados relacional e já têm experiência com SQL.
Então, o que acontece com os desenvolvedores que preferem usar um cliente shell? É aí que entra em cena o Couchbase Shell (CBQ).
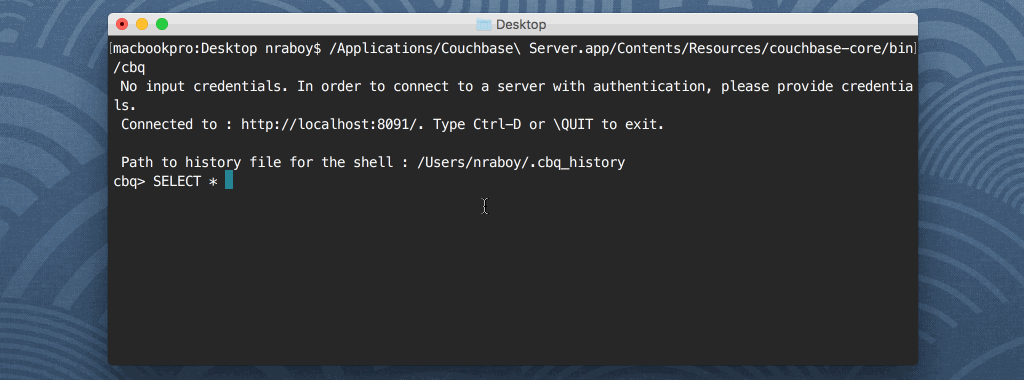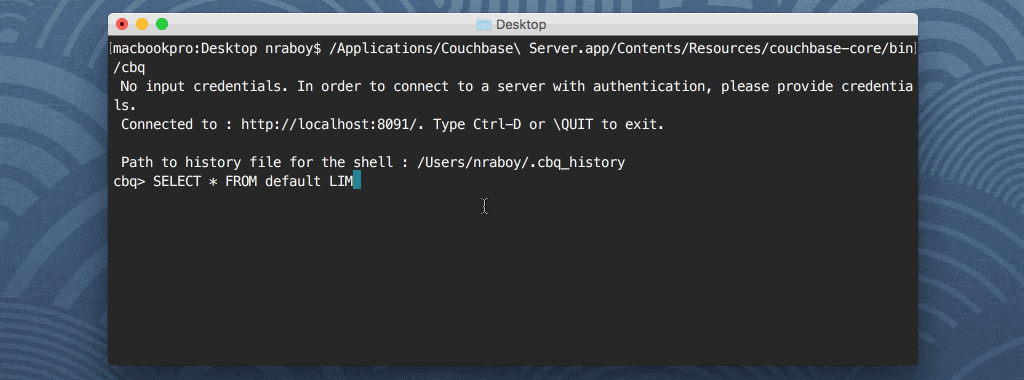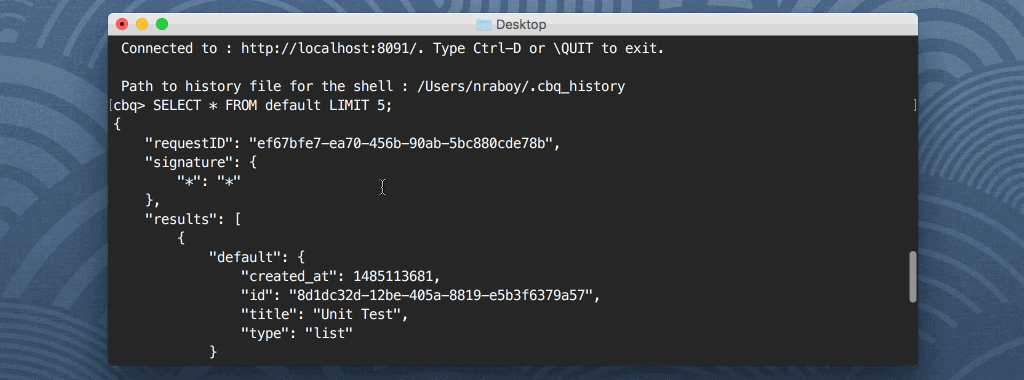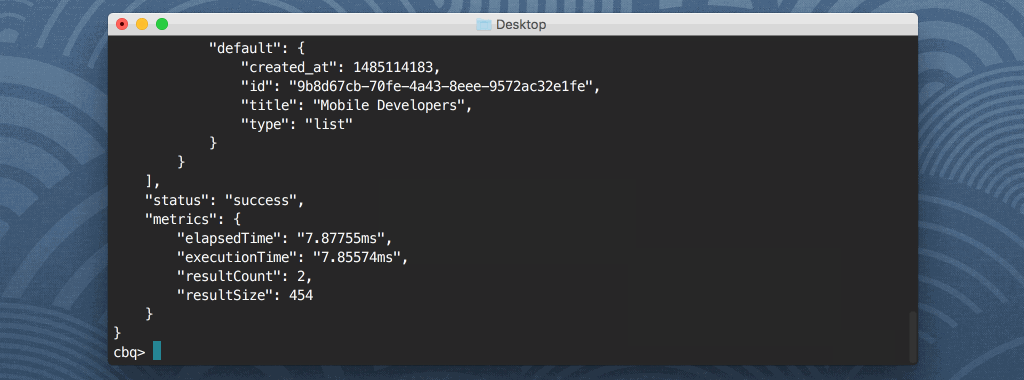
O cliente shell é semelhante ao que você encontraria no MongoDB ou em qualquer uma das tecnologias de banco de dados relacional. E se você quisesse salvar os resultados da consulta em um arquivo, em vez de exibi-los no shell? Você poderia fazer algo assim:
|
1 |
eco "SELECT * FROM default;" | /Aplicativos/Couchbase Servidor.aplicativo/Conteúdo/Recursos/couchbase-núcleo/caixa/cbq -u Administrador -p senha -o ~/Desktop/saída.txt |
Você não está limitado à execução estrita de consultas com o CBQ. Há recursos de gerenciamento de conexão e segurança que também estão disponíveis. Um conjunto completo de recursos pode ser visto na seção documentação bem como esta postagem do blog Eu já havia escrito anteriormente.
O Query Workbench e o CBQ têm suas finalidades, mas, na maioria dos casos, você consultará seus documentos usando um dos muitos SDKs para desenvolvedores em seu aplicativo. Com suporte de linguagem para tecnologias de desenvolvedor populares, como Java, .NET, Node.js e Golang, você está totalmente coberto quando se trata de usar o NoSQL em seu aplicativo.
Indexação no Couchbase Server
A consulta ao Couchbase requer a criação de índices em seu cluster do Couchbase. Há alguns tipos de índices que podem ser criados, e eles são feitos com base nas necessidades de seu aplicativo.
Veja, por exemplo, o índice local. Quando os índices locais são criados no cluster, cada nó indexa os dados que mantém localmente. Essa é uma solução que funciona bem para uma implantação de nó único, mas quando você começa a aumentar o número de nós no cluster, a latência da consulta começa a ser prejudicada. Isso ocorre porque a coleta dispersa precisa ocorrer entre os nós disponíveis antes de retornar os dados ao cliente.
À medida que você cria um cluster de vários nós, faz mais sentido começar a usar índices secundários globais (GSI). Nesse cenário, o índice é colocado longe dos nós de dados e existe em menor quantidade. Em vez de usar o scatter gather em cada índice local, a consulta vai para o índice global que conhece os dados que queremos e os retorna. Isso melhora significativamente a latência da consulta.
Então, como você cria um índice secundário global em seu cluster? Tente executar algo como o seguinte:
|
1 |
CRIAR ÍNDICE pessoas ON padrão(primeiro nome, sobrenome) ONDE tipo = "pessoa" USO GSI; |
Tanto os índices locais quanto os índices secundários globais podem ser lidos em um ótima postagem no blog.
Isso nos leva a um dos mais novos recursos de indexação do Couchbase. A partir do Couchbase 4.5, há o que é conhecido como índices secundários globais otimizados para memória (MOI).
Agora, em vez de os índices existirem no disco e serem executados em velocidades de disco, eles podem existir na memória com um desempenho muito maior. Mais informações sobre índices otimizados para memória podem ser lidas em esta postagem do blog.
Então, como você sabe quais índices suas consultas estão usando? Faz sentido executar um EXPLICAR em uma de suas consultas:
|
1 |
EXPLICAR SELECIONAR primeiro nome, sobrenome DE padrão ONDE tipo = "pessoa"; |
Os resultados sobre o EXPLICAR informam qual índice a consulta usou, além de várias informações de métricas sobre o que foi feito no processo. Se estiver usando o índice que criei para essa consulta, o EXPLICAR deve dizer que estamos usando o pessoas índice.
Pronto para a produção com um poderoso apoio do cliente
Tanto o Couchbase Community quanto o Enterprise Edition estão prontos para produção e estão sendo usados ativamente por organizações bem conhecidas. Prepare-se para alguns nomes.
Empresas enormes e altamente respeitadas, como, entre outras, LinkedIn, PayPal, eBay, United, Marriott, GE e Verizon, estão usando milhares de nós do Couchbase para alimentar a camada de dados de suas organizações. Algumas dessas empresas falaram no Couchbase Connect e as gravações podem ser assistidas em YouTube.
Para obter uma lista de mais clientes do Couchbase, confira a lista aqui.
Conclusão
O Couchbase é um banco de dados de documentos NoSQL rico em recursos que certamente está pronto para produção. Com a capacidade de usar um modelo de dados JSON flexível e ferramentas e consultas avançadas, o Couchbase se torna um banco de dados perfeito para praticamente qualquer cenário.
Para obter mais informações sobre como usar o Couchbase, consulte o Portal do desenvolvedor do Couchbase para tutoriais e outras documentações.