Muito já foi dito sobre microsserviços nos últimos anos, mas comumente vejo novos sistemas distribuídos sendo desenvolvidos com a antiga mentalidade de monólitos. O efeito colateral de criar algo novo sem a compreensão de alguns conceitos-chave é que você acabará com mais problemas do que antes, o que definitivamente não é o objetivo que você tinha em mente.
Neste artigo, gostaria de abordar alguns conceitos que, historicamente, consideramos óbvios e que podem levar a uma arquitetura ruim quando aplicados a microsserviços:
Fazer apenas chamadas síncronas
Em uma arquitetura monolítica, estamos acostumados com a disponibilidade do tipo "tudo ou nada", sempre podemos chamar qualquer serviço a qualquer momento. No entanto, em um mundo de microsserviços, não há garantias de que um serviço do qual dependemos estará on-line. Poderia ser ainda pior, pois um serviço lento pode tornar todo o sistema mais lento, já que cada thread ficará bloqueado por um determinado período de tempo enquanto aguarda a resposta do serviço externo.
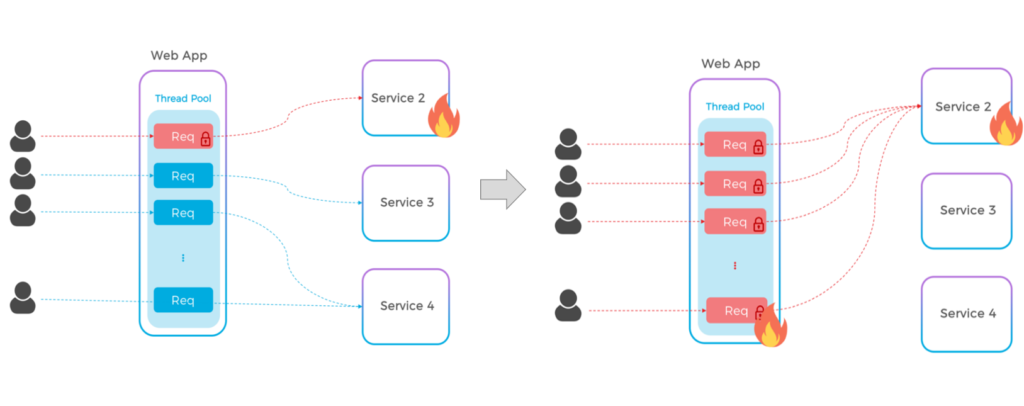
Como os threads bloqueados/lentos acabam consumindo todo o seu pool de threads
Ainda estamos aprendendo a implementar adequadamente as comunicações entre os serviços, mas a regra geral é tornar tudo assíncronoE é aí que surge um dos primeiros desafios, pois historicamente não exercitamos o suficiente nossa capacidade de transformar um fluxo síncrono em assíncrono.
Espera-se que a maioria dos casos de uso possa ser implementada de forma assíncrona com a quantidade certa de esforço. A Amazon, por exemplo, implementou todo o seu sistema de pedidos dessa forma, e você mal consegue fazer isso. sentir isso. É quase certo que eles permitirão que você faça um pedido com sucesso, mas se houver algum problema com o pagamento ou se o produto estiver fora de estoque, você receberá uma notificação por e-mail alguns minutos ou horas depois informando sobre isso e quais ações precisam ser tomadas. A vantagem dessa abordagem é clara: mesmo que o serviço de pagamento ou estoque esteja fora do ar, isso não impedirá que os usuários façam um pedido. Essa é a beleza da comunicação assíncrona.
É claro que nem tudo em seu sistema pode ser assíncrono e, para lidar com os problemas comuns de chamadas síncronas, como instabilidade de rede, alta latência ou indisponibilidade temporária de serviços, tivemos que criar um conjunto de padrões para evitar falhas em cascata, como caches locais, timeouts, novas tentativas, circuit breakers, anteparos etc. Existem muitas estruturas que implementam esses conceitos, mas o Netflix Hystrix é atualmente a biblioteca mais conhecida.
Não há nada essencialmente errado com essa abordagem; ela funciona muito bem para várias empresas. A única desvantagem é que estamos empurrando uma responsabilidade extra para cada serviço, o que torna seu microsserviço ainda menos "micro". Algumas opções foram propostas nos últimos dois anos para resolver esse problema. O padrão Service Mesh, por exemplo, tenta externalizar essa complexidade na forma de um contêiner sidecar:
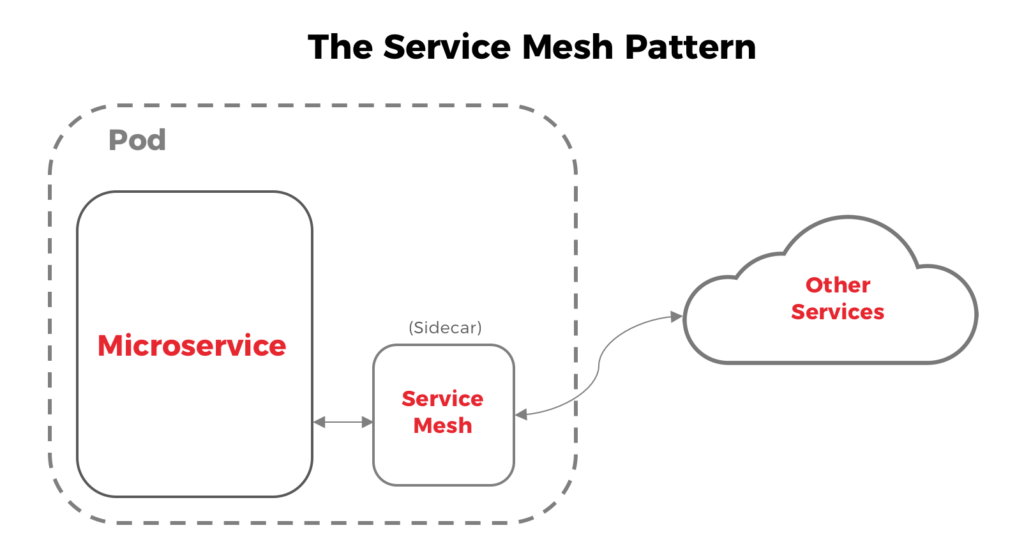
Pessoalmente, gosto dessa abordagem, especialmente porque ela é independente de linguagem, o que significa que funcionará para todos os seus microsserviços, independentemente da linguagem em que foi escrita. Outra vantagem são as métricas padronizadas, pois diferentes bibliotecas/frameworks podem usar um algoritmo ligeiramente diferente para novas tentativas, tempos limite, interrupções de circuito etc. Essas pequenas diferenças podem afetar significativamente as métricas geradas, fazendo com que o algoritmo seja mais eficiente. Essas pequenas diferenças podem afetar significativamente as métricas geradas, tornando impossível ter uma visão confiável do comportamento do sistema.
ATUALIZAÇÃO: Se você quiser saber mais sobre o padrão Service Mesh, Confira esta excelente apresentação.

Em resumo, pensar em como os serviços se comunicarão entre si é essencial para uma arquitetura bem-sucedida e deve ser planejado com antecedência para evitar uma cadeia de dependências. Quanto menos os serviços souberem uns sobre os outros, melhor será a arquitetura.
Use apenas RDBMS para tudo
Depois de 30 anos de monopólio dos RDBMS, é compreensível que muitas pessoas ainda pensem dessa forma. Entretanto, hoje em dia, praticamente todos os dias nasce um novo banco de dados (e duas estruturas JavaScript). Se antigamente a escolha de um banco de dados era uma questão de escolher um entre cinco, hoje a mesma tarefa exige muito mais atenção.
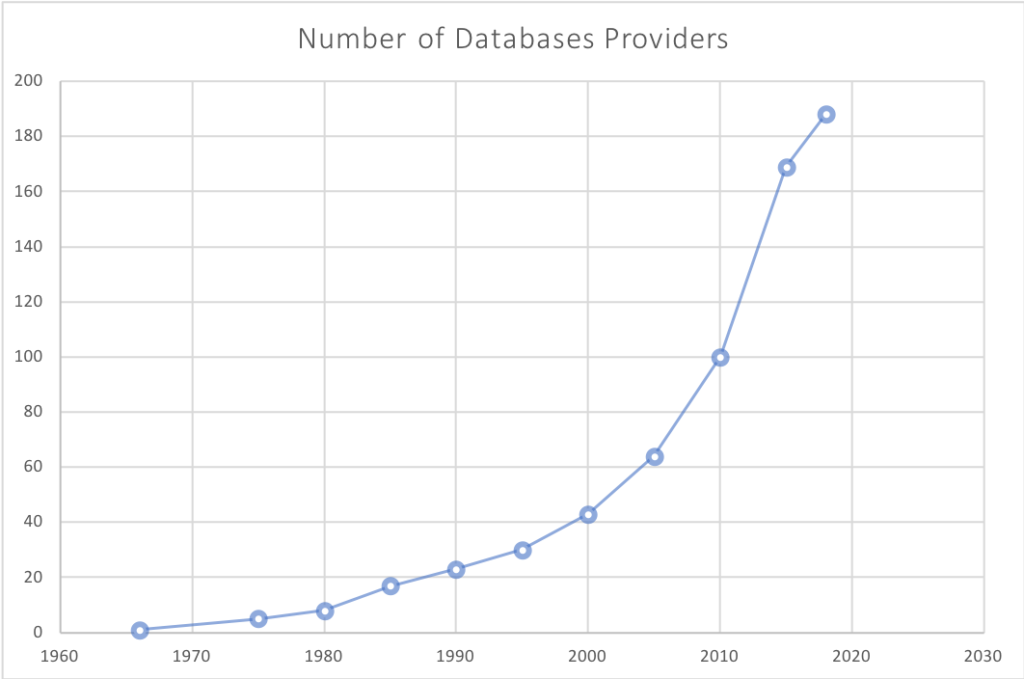
Fonte: db-engines.com - datas de lançamento iniciais
Como Martin Fowler disse Há 12 anos, há muitos benefícios na escolha de um armazenamento especializado, tais como: maior desempenho, menor custo etc. Não vou gastar seu tempo analisando todas as desvantagens do RDBMS (leituras lentas, dados esparsos, incompatibilidade de impedância, junções etc.). Em vez disso, gostaria apenas de destacar novamente como o banco de dados desempenha um papel importante no desempenho geral do sistema, e uma escolha inadequada acabará custando muito mais dinheiro.
Os benefícios da persistência poliglota são claros, e a maturidade das soluções foi comprovada por vários casos de uso críticos bem-sucedidosapenas para citar alguns: Pokémon Go, AirBnB, Viber, eBay, Céu, Amadeus, Amazon, Google, LinkedIn e Netflix
Há cinco anos, eu teria concordado com o "argumento da curva de aprendizado" do motivo pelo qual você ainda não começou a usar o NoSQL. No entanto, desde então, muita coisa mudou, e algumas empresas se esforçaram muito para facilitar a vida dos desenvolvedores e DBAs, como o Couchbase Inicialização de Primavera/Dados de Primavera ou o recém-lançado Operador de Kubernetes que visa a automatizar a maior parte do trabalho dos DBAs.
Não pense em depuração e observabilidade
Um dia, você terá um bug distribuído que espalhará inconsistências em todo o seu sistema. Então, você percebe que não há uma maneira fácil de entender onde as coisas estão falhando: Foi um bug? Foi um problema de rede? O serviço estava temporariamente indisponível?
É por isso que você precisa planejar com antecedência como vai depurar o sistema. Espera-se que, para a rede, um Service Mesh possa ser uma solução rápida, e para o registro distribuído, ferramentas como FluentD ou Logstash são úteis. Porém, quando falamos em entender como uma entidade chegou a um estado específico, ou mesmo como correlacionar dados entre serviços, não existe uma ferramenta fácil.
Para resolver esse problema, você pode usar Registro e fornecimento de eventos. Nesse padrão, cada serviço armazena (e valida) todas as alterações no estado do aplicativo em um objeto de evento e, naturalmente, sempre que você precisar verificar o que aconteceu com uma entidade específica, tudo o que precisa fazer é navegar por todo o registro de eventos relacionados a ela.
Se você também adicionar o controle de versão ao seu estado, a correção de inconsistências será ainda mais fácil, pois você poderá corrigir as mensagens inconsistentes apenas definindo o estado do objeto como era antes e, em seguida, reproduzir todas as mensagens recebidas a partir da mensagem problemática.
Tanto o controle de versão quanto o registro podem ser feitos de forma assíncrona, e você provavelmente não consultará esses dados com frequência, o que o torna uma solução interna barata para depuração/auditoria do seu sistema. Na próxima semana, publicarei uma análise aprofundada desse padrão, portanto, aguarde uma semana.
Há muitas outras estruturas/padrões para ajudá-lo a depurar seus microsserviços, mas todas elas geralmente exigem uma única estratégia distribuída para funcionar. Infelizmente, no momento em que você percebe que precisa de tal coisa, já é tarde demais e você precisará gastar uma quantidade significativa de tempo refatorando tudo. Esse é um dos principais motivos pelos quais você precisa definir como vai observar/depurar seu sistema antes mesmo de começar.
Se você tiver alguma dúvida, sinta-se à vontade para me enviar um tweet para @deniswsrosa