O Couchbase Lançamento do Sync Gateway 2.8 anunciou o suporte à sincronização de dados de nuvem para borda de nível empresarial. A nova tecnologia de replicação inter-Sync Gateway permite a sincronização segura e dimensionável de nível empresarial entre os data centers de nuvem e de borda em um ambiente de nuvem distribuída para atender às demandas dos aplicativos de computação de borda.
Nesta postagem, apresentamos uma visão geral do recurso com alguns exemplos de como configurar sua implantação. Para obter mais detalhes, consulte a seção documentação páginas.
Primeiro, alguns casos de uso ...
Casos de uso
As implantações de nuvem distribuída, em que o armazenamento e o processamento de dados são distribuídos e tratados mais perto dos aplicativos, estão ganhando relevância à medida que os aplicativos exigem alta disponibilidade garantida, respostas em tempo real, adesão à privacidade dos dados e restrições regulatórias e estão lidando com grandes volumes de dados. Esse paradigma de computação é chamado de "Edge Computing" (computação de borda). Você pode saber mais sobre isso neste blog sobre "Arquitetando soluções de computação de borda com o Couchbase".
Aqui estão alguns exemplos de aplicativos que se beneficiam dessa arquitetura de nuvem distribuída
- Varejo :
As grandes lojas de varejo continuarão a atender seus clientes mesmo em caso de interrupções na Internet, executando a partir de servidores em seus servidores locais no local. Tempo de inatividade da empresa não é apenas prejudicial à experiência do cliente, mas também pode ter um impacto duradouro na reputação. Nesse caso, a garantia de alta disponibilidade de aplicativos e a resiliência são os principais fatores - Viagens :
Os passageiros de navios de cruzeiro podem aproveitar todos os serviços a bordo, mesmo quando os navios ficam desconectados da Internet por dias ou meses. Nesse caso, o data center no cruzeiro continuará a atender aos passageiros durante a viagem. Esse é outro exemplo em que a garantia de alta disponibilidade de aplicativos e a resiliência são os principais fatores. - Hospitalidade :
As propriedades hoteleiras podem garantir que os hóspedes façam o check-in mesmo quando houver uma queda na Internet. Os sistemas de gerenciamento de propriedades (PMS) na propriedade garantirão que a experiência do hóspede não seja comprometida. Esse é outro exemplo em que a garantia de alta disponibilidade de aplicativos e a resiliência são os principais fatores. - Assistência médica :
Os sistemas de monitoramento de pacientes em hospitais podem processar localmente os dados dos pacientes e tomar medidas corretivas imediatas. O processamento de dados em tempo real e a privacidade dos dados são os principais fatores nesse caso. - IoT :
Os aplicativos de IoT são um dos principais impulsionadores das arquiteturas de Edge Computing. Os aplicativos nesse espaço geram grandes volumes de dados que precisam ser analisados em tempo real. A transferência de todos esses dados para os servidores de back-end impõe muita sobrecarga à rede e aos servidores. Além disso, muitos dos dados costumam ser efêmeros por natureza e não faz muito sentido transferi-los para servidores remotos apenas para serem processados e descartados. Como um exemplo específico no espaço da IIoT, as fábricas podem monitorar, coletar e analisar dados de sensores de equipamentos localmente para manutenção preventiva. Somente os dados agregados são enviados para o data center na nuvem. O processamento de dados em tempo real e a economia de custos com a redução do uso da largura de banda são os principais motivadores nesse caso.
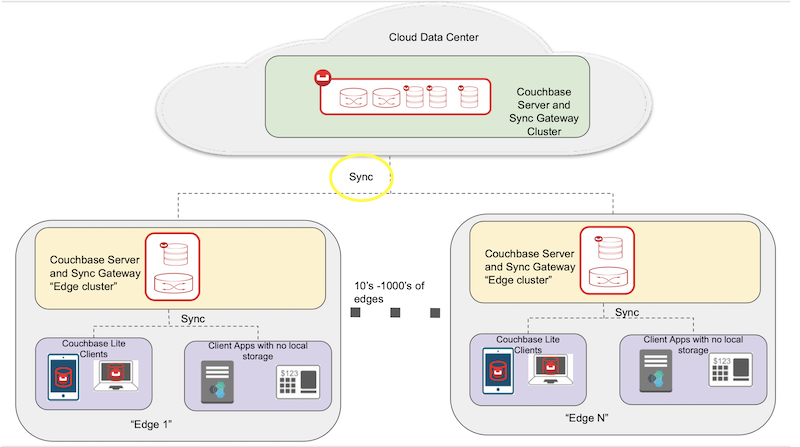
Implantação típica de nuvem para borda
Uma implantação típica de uma arquitetura de nuvem distribuída usando o Couchbase é mostrada abaixo.
Como o Couchbase se encaixa? Você tem o Couchbase Server nos data centers de nuvem remota e é responsável pelo armazenamento e processamento de dados em todos os data centers de borda. Em seguida, você tem uma área de cobertura menor do Couchbase Server em cada um dos data centers de borda. O tamanho dos servidores nos data centers de borda será significativamente menor do que o dos data centers de nuvem, pois atende a uma população menor de clientes na borda. Os dados locais da borda são processados pelo cluster do servidor Couchbase no local.
Mas e quanto à movimentação de dados? Em outras palavras, como os dados entre a nuvem e a borda permanecem sincronizados. É aí que entra a replicação entre os Gateways de sincronização. Para isso, você tem o Sync Gateway implantado na nuvem e nos data centers de borda, que é responsável pela replicação dos dados. Além disso, é preciso considerar que a sincronização está ocorrendo pela Internet, que não é confiável. Portanto, é necessário garantir que os dados sejam criptografados e que haja controles de segurança rigorosos para garantir o acesso autorizado aos dados. Além disso, você pode ter diferentes políticas de controle de acesso implementadas na nuvem e na borda e pode garantir que uma borda comprometida não afete a nuvem ou os outros data centers de borda.
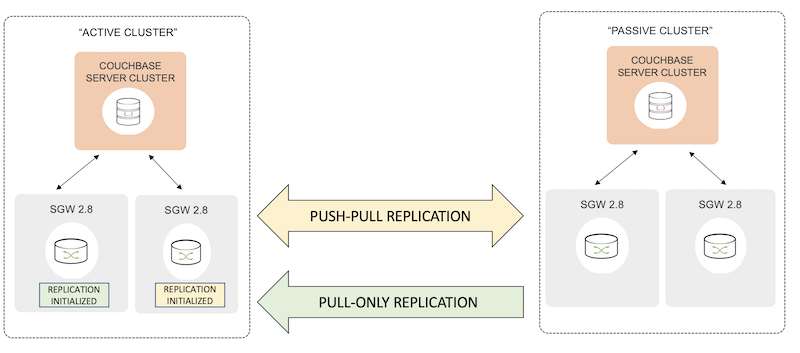
Dica de configuração de implantação
O cluster do Sync Gateway no qual a replicação é inicializada ou agendada é o "Cluster ativo" e o cluster remoto do Sync Gateway que é o destino da replicação é o "Cluster passivo".
Se você tiver várias replicações a serem configuradas entre dois clusters, é recomendável escolher um cluster como o cluster ativo para todas as suas replicações. Isso é válido independentemente da direção de sua replicação - push, pull ou push-pull. Essa configuração simplifica a implementação, a administração e a solução de problemas de suas replicações
Particularmente no contexto da sincronização de nuvem para borda, prevemos que a borda será o cluster ativo que iniciará as replicações para o cluster de nuvem remoto. É provável que os clusters de borda não sejam acessíveis por uma rede externa.
Atributos da tecnologia Sync
Lidar com a sincronização em escala em uma rede não confiável e em condições de rede não confiáveis não é um desafio fácil. Há várias considerações a serem feitas e aqui está uma visão geral de como a replicação do Gateway inter-Sync. Consulte a seção documentação para obter detalhes
| Recurso | Replicação inter-Sync Gateway |
|---|---|
| Escalabilidade | O número de dados de borda pode variar de 10s a 100s a 1000s. O protocolo é capaz de ser dimensionado para lidar com esse número de bordas |
| Segurança | A sincronização está ocorrendo pela Internet, que é inerentemente não confiável. Todos os dados são criptografados por TLS e há controles de acesso rigorosos para evitar o acesso não autorizado aos dados. Além disso, você pode ter diferentes políticas de controle de acesso implementadas na nuvem e na borda e pode garantir que uma borda comprometida não afete a nuvem ou os outros data centers de borda. |
| Resiliência da rede | O protocolo implementa um algoritmo de tentativa de backoff exponencial. O período de backoff é configurável |
| Eficiência | Para otimizar o uso da largura de banda da rede e reduzir os custos de transferência, o protocolo suporta a sincronização delta - capacidade de sincronizar partes do documento que foram alteradas. A sincronização pode operar tanto no modo contínuo quanto no modo de disparo único, sob demanda. Assim, os aplicativos têm controle sobre quando sincronizar os dados e, por exemplo, podem optar por fazê-lo fora dos horários de pico |
| Conflitos de dados | Estratégia abrangente de resolução de conflitos. O Sync Gateway oferece suporte à resolução automática de conflitos com resolvedores prontos para uso e você pode definir seu próprio resolvedor de conflitos - de forma semelhante à maneira como a função de sincronização é definida, você pode definir uma função JS como parte do arquivo de configuração do Sync Gateway. |
| Facilidade operacional | Alta disponibilidade de replicações, balanceamento de carga/distribuição automática de replicações uniformemente entre os nós do Sync Gateway e uma interface REST para administração e gerenciamento remotos |
| Topologias flexíveis | Hierárquico. O número de níveis na hierarquia pode ser maior que 1 - por exemplo, o data center em nuvem pode se comunicar com data centers downstream que, por sua vez, podem se comunicar com mais data centers downstream. |
Configurações de amostra
Nesta seção, apresentamos alguns exemplos de configurações típicas de replicadores.
As réplicas têm o escopo de um banco de dados e podem ser configuradas no Arquivo de configuração do Sync Gateway e programados durante o lançamento ou podem ser inicializados por meio do _replicação em qualquer ponto após a inicialização.
Por padrão, todos os nós participam das replicações. Isso implica que as replicações configuradas para um cluster de nós do Sync Gateway são distribuídas uniformemente entre todos os nós. Um nó do Sync Gateway pode ser configurado para não participar da replicação usando o parâmetro sgreplicate_enabled opção de configuração.
Replicação pull-only one-shot com resolução de conflitos padrão
Neste exemplo, uma replicação com Id pull-from-target-oneshot é configurado para fazer uma extração única de documentos pertencentes ao canal channel:storechannel do lojas no banco de dados do remoto endpoint. Os documentos são replicados para o endpoint local minha_loja_local banco de dados. As credenciais do usuário replicante são especificadas por meio do parâmetro nome de usuário e senha parâmetros.
A replicação está inicialmente em estado interrompido e pode ser iniciada em um momento posterior por meio de status da replicação endpoint. Os conflitos são tratados automaticamente pelo Sync Gateway usando políticas predefinidas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
enrolar -X PUT https://localhost:4985/minha_loja_local/_replicação/puxar-de-alvo-uma foto -H 'Accept: application/json' -H 'Authorization: Basic ZGVtbzpwYXNzd29yZA==' -H 'Content-Type: application/json' -d ' { "replication_id": "pull-from-target-oneshot" (puxar do alvo para um único tiro), "remoto": "https://remote-sgw-cluster:4984/stores", "direção": "puxar", "nome de usuário":"store1", "senha":"sdfhdgsfh676767", "contínuo": falso, "filtro":"sync_gateway/bychannel", "query_params": { "canais":["channel:storechannel"] }, "initial_state": "parado" }' |
Replicação contínua bidirecional com resolução de conflitos pronta para uso
Neste exemplo, uma replicação com Id pushandpull-com-alvo-contínuo é configurado para fazer um push e pull contínuos de documentos pertencentes ao canal channel:storechannel de lojas no banco de dados do remoto endpoint. Os documentos são replicados para o endpoint local minha_loja_local banco de dados. As credenciais do usuário replicante são especificadas por meio do parâmetro nome de usuário e senha parâmetros.
A replicação é iniciada automaticamente quando programada - esse é o valor padrão de initial_state bandeira. Em caso de conflito, o lado remoto é o vencedor.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
enrolar -X PUT http://localhost:4985/minha_loja_local/_replicação/empurrar e puxar-com-alvo-contínuo -H 'Accept: application/json' -H 'Authorization: Basic ZGVtbzpwYXNzd29yZA==' -H 'Content-Type: application/json' -d ' { "replication_id": "pushandpull-with-target-continuous" (empurrar e puxar com alvo contínuo), "remoto": "https://remote-sgw-cluster:4984/stores", "direção": "pushAndPull", "nome de usuário":"store1", "senha":"sdfhdgsfh676767", "conflict_resolution_type": "remoteWins", "filtro": "sync_gateway/bychannel", "query_params": { "canais":["channel:storechannel"] } }' |
Replicação contínua bidirecional com resolução de conflitos personalizada
Este exemplo é idêntico ao caso anterior, exceto pelo fato de associarmos um resolvedor de conflitos personalizado ao replicador. Agora, toda vez que o Sync Gateway detecta um conflito durante a replicação, o resolvedor de conflitos é chamado com as revisões conflitantes. O resolvedor tem acesso ao corpo completo do documento e aos metadados que podem ser usados para resolver o conflito. Obviamente, você pode optar por retornar qualquer uma das revisões conflitantes para implementar o equivalente à estratégia "LocalWins" ou "RemoteWins".
A propósito, não se prenda muito aos detalhes do que está acontecendo no resolvedor ou à sua precisão/eficiência. Tenho certeza de que há maneiras melhores de fazer isso em Javascipt - isso é apenas para demonstrar o conceito.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
enrolar -X PUT http://localhost:4985/minha_loja_local/_replicação/empurrar e puxar-com-alvo-contínuo -H 'Accept: application/json' -H 'Authorization: Basic ZGVtbzpwYXNzd29yZA==' -H 'Content-Type: application/json' -d ' { "replication_id": "pushandpull-with-target-continuous" (empurrar e puxar com alvo contínuo), "remoto": "https://remote-sgw-cluster:4984/stores", "direção": "pushAndPull", "nome de usuário":"store1", "senha":"sdfhdgsfh676767", "custom_conflict_resolver": "função(conflito) { função(conflito) { se ( (conflitoLocalDocument.tipo != nulo) && (conflito.RemoteDocument.tipo != nulo) && (conflitoLocalDocument.tipo == \"foo\")) { retorno defaultPolicy(conflito); } mais { var remoteDoc = conflito.RemoteDocument; var localDoc = conflitoLocalDocument; var mergedDoc = estender({}, localDoc, remoteDoc); retorno mergedDoc; função estender(alvo) { var fontes = [].slice.chamada(argumentos, 1); fontes.forEach(função (fonte) { para (var suporte em fonte) { alvo[suporte] = fonte[suporte]; } }); retorno alvo; } } }", "filtro": "sync_gateway/bychannel", "query_params": { "canais":["channel:storechannel"] } }' |
É claro que há muitos outros configuração opções para escolher, o que permitirá que você o personalize para atender às necessidades do seu aplicativo. Você pode consultar nossa documentação para obter detalhes.
Monitoramento de réplicas
Quando suas configurações estiverem em funcionamento, você poderá monitorá-las por meio do status da replicação . Na versão 2.8, também lançamos um novo endpoint de métricas no modo Developer Preview. Esse endpoint também exporta estatísticas no formato Prometheus, o que facilitaria muito o monitoramento com o Prometheus e a visualização usando o Grafana. Você poderá saber mais sobre isso em um próximo blog.
E quanto ao "SG-Replicate"?
Se você tem trabalhado com o gateway Sync, provavelmente está familiarizado com a função SG-Replicar que pode ser usado para replicação entre os nós do Sync Gateway em diferentes clusters. A nova versão do protocolo, que é baseada em websockets, foi reprojetada desde o início para oferecer vários recursos de nível empresarial, como balanceamento automático de carga de replicações entre os nós do Sync Gateway participantes, alta disponibilidade (HA), resolução automática de conflitos integrada com resolvedores de conflitos personalizados, suporte à sincronização delta, melhorias significativas na escalabilidade e no desempenho e muito mais.
Embora o "SG-Replicate" continue a ter suporte na versão 2.8, ele foi descontinuado e os aplicativos existentes devem migrar para a nova versão da tecnologia de replicação do Gateway de sincronização interna.
O que vem a seguir
A solução de sincronização da nuvem para a borda do Couchbase Sync Gateway é segura, dimensionável e fácil de configurar e gerenciar. O sync é a única solução de sincronização de banco de dados ponto a ponto que permite que os clientes se comuniquem diretamente entre si em ambientes desconectados.
Você pode download do Sync Gateway e avaliar a funcionalidade gratuitamente.
Se quiser se aprofundar nos detalhes, veja aqui onde você pode encontrar mais informações
– Vídeo de conexão com demonstração: Usando a replicação do Gateway inter-Sync
– Documentação: Replicação do gateway inter-Sync
– Página de soluções: Computação de borda
O Fóruns do Couchbase é um ótimo lugar para entrar em contato com perguntas. Deixe um comentário abaixo ou sinta-se à vontade para entrar em contato comigo via Twitter ou enviar-me um e-mail