Big Data
Apache Hadoop o plataforma de big data. Ela foi projetada para extrair valor do volume. Ela pode armazenar e processar muito de dados em descansobig data. Ele foi projetado para análises. Não foi projetado para a velocidade.
É um depósito. É eficiente para adicionar e remover muitos itens de um depósito. É não eficiente para adicionar e remover um único item de um depósito.
Os conjuntos de dados são armazenados. As informações são geradas a partir de dados históricos, e você pode recuperá-las. Volume puro

Dados rápidos
O Apache Storm é o plataforma de processamento de fluxo. Ela foi projetada para extrair valor da velocidade. Ela pode processar dados em movimento, dados rápidos. Ele não foi projetado para volume.
É uma esteira transportadora. Os itens são colocados na esteira transportadora, onde podem ser processados até serem removidos dela. Os itens fazem não permanecem na esteira transportadora indefinidamente. Eles são colocados nela. Eles são removidos da esteira.
Os itens de dados são canalizados. As informações são geradas a partir dos dados atuais, mas o usuário não pode recuperá-lo. Velocidade pura
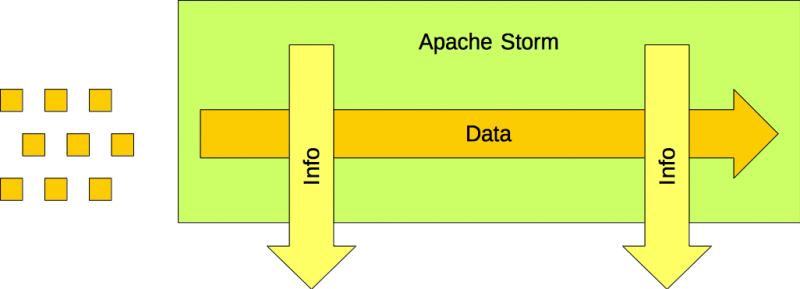
O GAP
No entanto, há algo faltando. Como os itens colocados em uma esteira transportadora acabam em um depósito?
O Couchbase Server é o banco de dados NoSQL empresarial. Ele foi projetado para extrair valor de uma combinação de volume e velocidade (e variedade).
É uma caixa. No final da esteira transportadora, os itens são adicionados às caixas. É eficiente adicionar e remover itens de uma caixa. É eficiente adicionar e remover caixas de um depósito.
Os itens de dados são armazenados e recuperados. Volume + Velocidade + Variedade

A solução
Uma arquitetura de Big Data em tempo real inclui um processador de fluxo, como o Apache Storm, um banco de dados NoSQL corporativo, como o Couchbase Server, e uma plataforma de Big Data, como o Apache Hadoop.
Opção #1
Os aplicativos leem e gravam dados no Couchbase Server e gravar dados no Apache Storm. O Apache Storm analisa fluxos de dados e grava os resultados no Couchbase Server usando um plug-in (ou seja, bolt). Os dados são importados para o Apache Hadoop a partir do Couchbase Server usando um plug-in Sqoop.
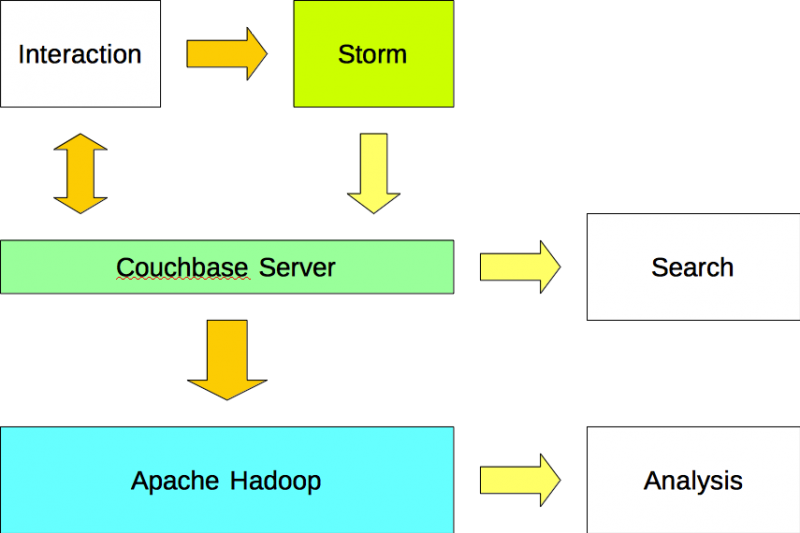
Opção #2
Os aplicativos gravam dados no Apache Storm e leem dados do Couchbase Server. O Apache Storm grava os dados (entrada) e as informações (saída) no Couchbase Server. Os dados são importados para o Apache Hadoop a partir do Couchbase Server usando um plug-in do Sqoop.
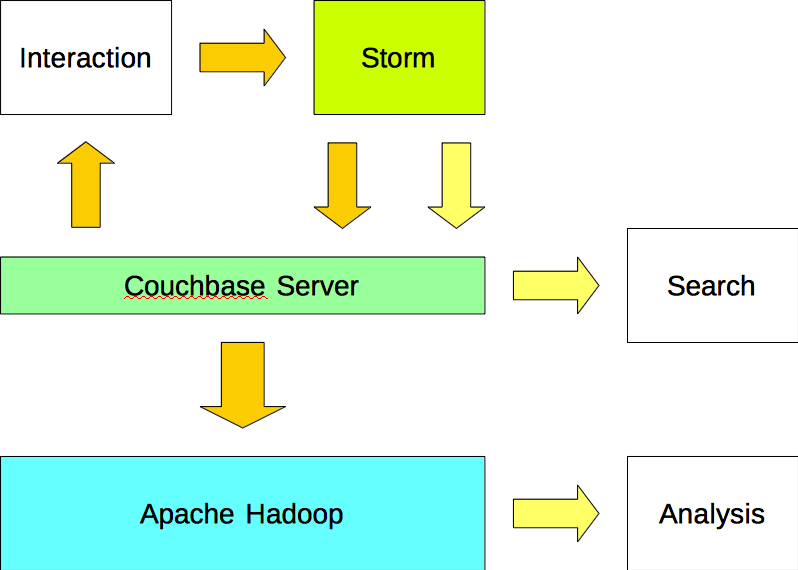
Opção #3
Os aplicativos gravam dados no Apache Storm e leem dados do Couchbase Server. O Apache Storm grava os dados (entrada) no Apache Couchbase e no Apache Hadoop. Além disso, o Apache Storm grava as informações (saída) no Couchbase Server e no Apache Hadoop.
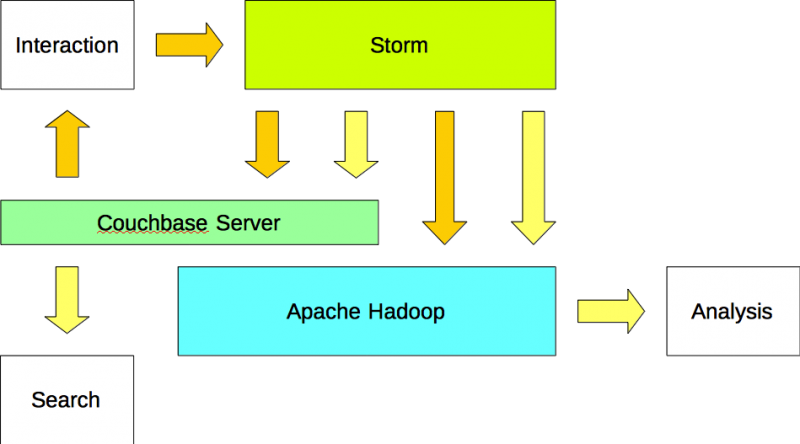
Resumo
Este artigo descreve três arquiteturas de Big Data em tempo real. Entretanto, o melhor de projetar uma arquitetura de Big Data em tempo real é que é como brincar com Legos. Os componentes vêm em várias formas e tamanhos, e cabe ao(s) arquiteto(s) selecionar e conectar as peças necessárias para criar a solução mais eficiente e eficaz possível. É um desafio empolgante.
Participe da conversa no reddit (link).
Participe da conversa no Hacker News (link).
Exemplos
Veja como esses clientes corporativos estão aproveitando o Apache Hadoop, o Apache Storm e muito mais com o Couchbase Server.
LivePerson - Apache Hadoop + Apache Storm + Servidor Couchbase
QuestPoint - Apache Hadoop + Couchbase Server
McGraw-Hill Education - Elasticsearch + Couchbase Server
AOL - Apache Hadoop + Servidor Couchbase
AdAction - Apache Hadoop + Servidor Couchbase
Referência
Conectores do servidor Couchbase (link)
Obrigado, muito boa leitura. Parece-me que a segunda opção é a abordagem mais limpa, mas todas são plausíveis.
Obrigado. Outra abordagem seria configurar o Apache Storm para gravar os dados analisados (saída) em tempo real no Couchbase Server e, ao mesmo tempo, gravar os dados brutos (entrada) no Apache Hadoop por meio de gravações em lote.
[...] A lacuna entre Big Data e dados rápidos [...]