Big Data
Apache Hadoop the big data platform. It was designed to derive value from volume. It can store and process a lot of data at rest, big data. It was designed for analytics. It was not designed for velocity.
It’s a warehouse. Is efficient to add and remove many items from a warehouse. It is not efficient to add and remove a single item from a warehouse.
Data sets are stored. Information is generated from historical data, and you can retrieve it. Pure Volume

Fast Data
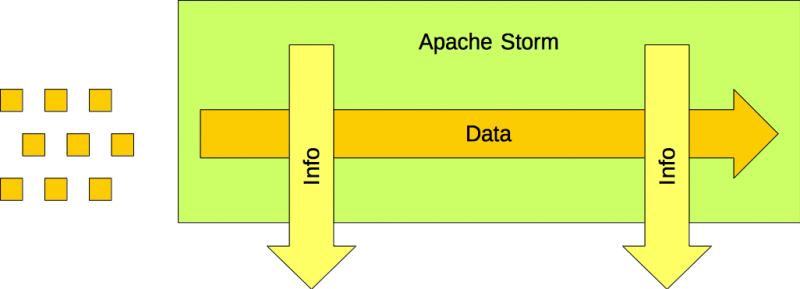
Apache Storm is the stream processing platform. It was designed to derive value from velocity. It can process data in motion, fast data. It was not designed for volume.
It’s a conveyor belt. Items are placed on conveyor belt where they can be processed until they are removed from it. Items do not stay on the conveyor belt indefinitely. They are placed on it. They are removed from it.
Data items are piped. Information is generated from current data, but you cannot retrieve it. Pure Velocity
The GAP
However, there is something missing. How do items placed on a conveyor belt end up in a warehouse?
Couchbase Server is the enterprise NoSQL database. It is designed to derive value from a combination of volume and velocity (and variety).
It is a box. At the end of the conveyor belt, items are added to boxes. It is efficient to add and remove items from a box. It is efficient to add and remove boxes from a warehouse.
Data items are stored and retrieved. Volume + Velocity + Variety

The Solution
A real-time big data architecture includes a stream processor such as Apache Storm, an enterprise NoSQL database such as Couchbase Server, and a big data platform such as Apache Hadoop.
Option #1
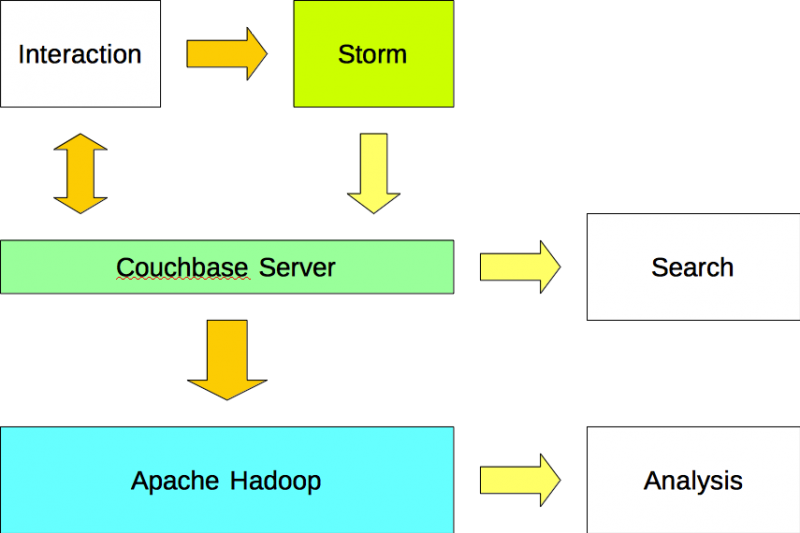
Applications read and write data to Couchbase Server and write data to Apache Storm. Apache Storm analyzes streams of data and writes the results to Couchbase Server using a plugin (i.e. bolt). The data is imported into Apache Hadoop from Couchbase Server using a Sqoop plugin.
Option #2
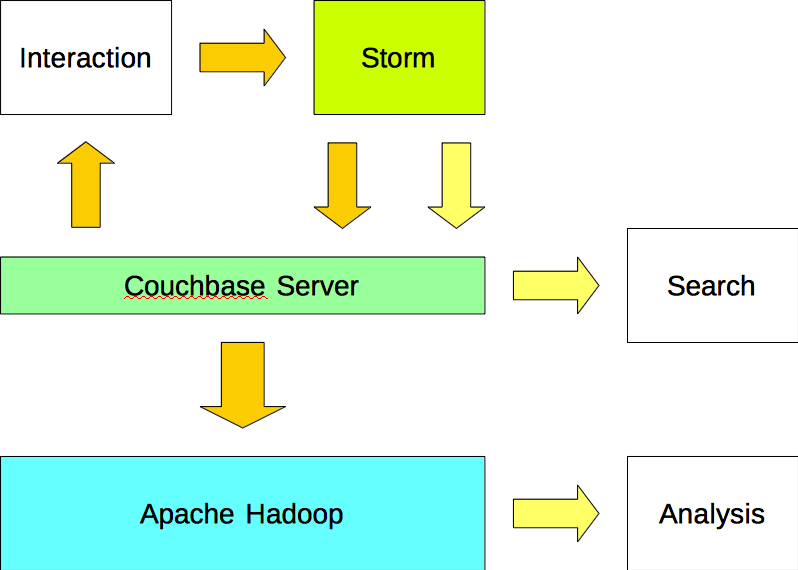
Applications write data to Apache Storm and read data from Couchbase Server. Apache Storm writes both the data (input) and the information (output) to Couchbase Server. The data is imported into Apache Hadoop from Couchbase Server using a Sqoop plugin.
Option #3
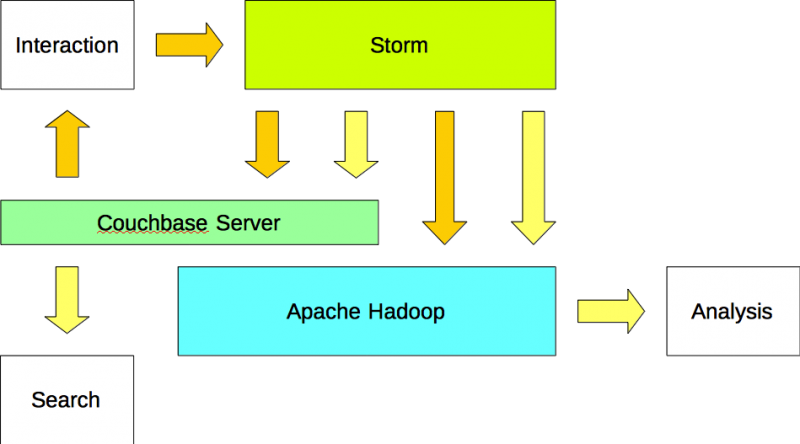
Applications write data to Apache Storm and read data from Couchbase Server. Apache Storm writes the data (input) to both Apache Couchbase and Apache Hadoop. In addition, Apache Storm writes the information (output) to both Couchbase Server and Apache Hadoop.
Summary
This article describes three real-time big data architectures. However, the best thing about designing a real-time big data architecture is that it is like playing with Legos. The components come in many shapes and sizes, and it is up to the architect(s) to select and connect the pieces necessary to build the most efficient and effective solution possible. It is an exciting challenge.
Join the conversation over at reddit (link).
Join the conversation over at Hacker News (link).
Examples
See how these enterprise customers are leveraging Apache Hadoop, Apache Storm, and more with Couchbase Server.
LivePerson – Apache Hadoop + Apache Storm + Couchbase Server
QuestPoint – Apache Hadoop + Couchbase Server
McGraw-Hill Education – Elasticsearch + Couchbase Server
AOL – Apache Hadoop + Couchbase Server
AdAction – Apache Hadoop + Couchbase Server
Reference
Couchbase Server Connectors (link)
Thank you, very good read. It seems to me the 2nd options is the cleanest approach, but they all are plausible.
Thanks. Another approach would be to configure Apache Storm to write the analyzed data (output) in real time to Couchbase Server while writing the raw data (input) to Apache Hadoop via batch writes.
[…] The Big Data/Fast Data Gap […]