No mundo atual, orientado por dados, a capacidade de coletar e preparar dados com eficiência é crucial para o sucesso de qualquer aplicativo. Se você estiver desenvolvendo um chatbot, um sistema de recomendação ou qualquer solução orientada por IA, a qualidade e a estrutura dos seus dados podem ser decisivas para o seu projeto. Neste artigo, vamos levá-lo em uma jornada para explorar o processo de coleta de informações e de fragmentação inteligente, com foco em como preparar os dados para Geração Aumentada por Recuperação (RAG) em qualquer aplicativo com o banco de dados de sua preferência.
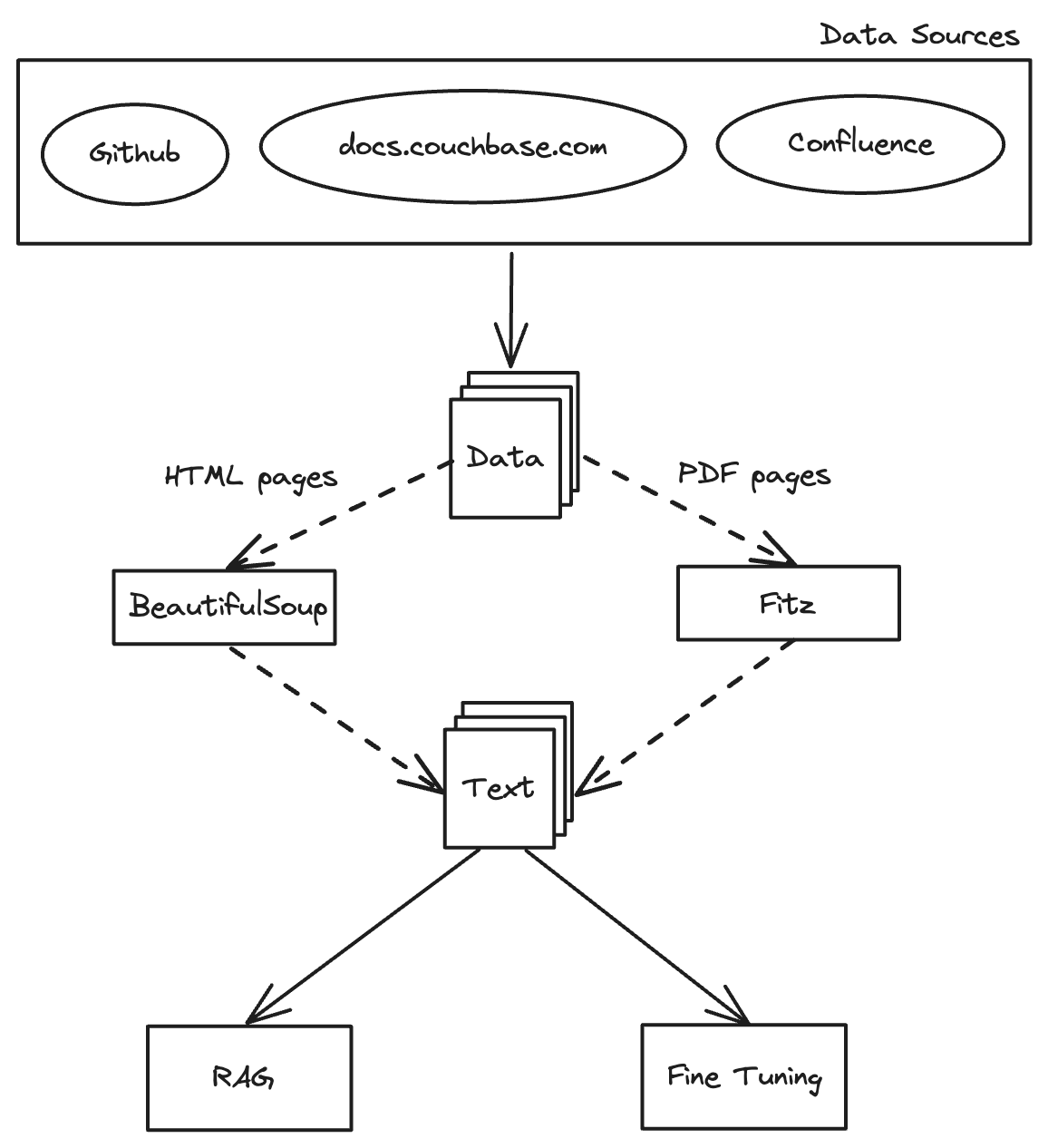
Visão geral de alto nível da conversão de documentos para RAG
Coleta de dados: A base do RAG
A magia da raspagem
Imagine uma aranha, não do tipo assustador, mas uma aranha bibliotecária diligente na enorme biblioteca da Internet. Essa aranha, personificada pelo Scrapy's Aranha começa na entrada (o URL inicial) e visita metodicamente cada cômodo (página da Web), coletando livros preciosos (páginas HTML). Sempre que encontra uma porta para outro cômodo (um hiperlink), ele a abre e continua a exploração, garantindo que nenhum cômodo deixe de ser verificado. É assim que o Scrapy funciona - coletando sistemática e meticulosamente todas as informações.
Aproveitamento do Scrapy para coleta de dados
Sucata é uma estrutura baseada em Python projetada para extrair dados de sites. É como dar superpoderes de aranha à nossa bibliotecária. Com o Scrapy, podemos criar aranhas da Web que navegam pelas páginas da Web e extraem as informações desejadas com precisão. Em nosso caso, implantamos o Scrapy para rastrear o site de documentação do Couchbase e baixar páginas HTML para processamento e análise adicionais.
Configurando seu projeto Scrapy
Antes que a nossa aranha possa iniciar sua jornada, precisamos configurar um projeto Scrapy. Veja como fazer isso:
- Instalar o Scrapy: Se você ainda não instalou o Scrapy, pode fazê-lo usando o pip:
1tubulação instalar sucata
- Criar um novo projeto Scrapy: Configure seu novo projeto Scrapy com o seguinte comando:
1sucata startproject documentos do couchbase
Criando a aranha
Com o projeto Scrapy configurado, agora criamos o spider que rastreará o site de documentação do Couchbase e baixará as páginas HTML. Veja como ele se parece:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
de biblioteca de caminhos importação Caminho importação sucata classe CouchbaseSpider(sucata.Aranha): nome = "couchbase" start_urls = ["https://docs.couchbase.com/home/index.html",] def analisar(autônomo, resposta): # Baixar o conteúdo HTML da página atual página = resposta.url.dividir("/")[-1] nome do arquivo = f"{page}.html" Caminho(nome do arquivo).write_bytes(resposta.corpo) autônomo.registro(f"Arquivo salvo {filename}") # Extrair links e segui-los para href em resposta.css("ul a::attr(href)").obter tudo(): se href.termina com(".html") ou "docs.couchbase.com" em href: rendimento resposta.seguir(href, autônomo.analisar) |
Correndo com a aranha
Para executar o spider e iniciar o processo de coleta de dados, execute o seguinte comando no diretório do projeto Scrapy:
|
1 |
sucata rastejar couchbase |
Esse comando iniciará o spider, que começará a rastrear os URLs especificados e a salvar o conteúdo HTML. O spider extrai links de cada página e os segue recursivamente, garantindo uma coleta de dados abrangente.
Ao automatizar a coleta de dados com o Scrapy, garantimos que todo o conteúdo HTML relevante do site de documentação do Couchbase seja recuperado de forma eficiente e sistemática, criando uma base sólida para processamento e análise adicionais.
Extração de conteúdo de texto: Transformando dados brutos
Depois de coletar as páginas HTML do site de documentação do Couchbase, a próxima etapa crucial é extrair o conteúdo do texto. Isso transforma os dados brutos em um formato utilizável para análise e processamento posterior. Além disso, podemos ter arquivos PDF contendo dados valiosos, que também serão extraídos. Aqui, discutiremos como usar scripts Python para analisar arquivos HTML e PDFs, extrair dados de texto e armazená-los para processamento posterior.
Extração de texto de páginas HTML
Para extrair o conteúdo de texto das páginas HTML, usaremos um script Python que analisa os arquivos HTML e recupera os dados de texto contidos em <p> tags. Essa abordagem captura o corpo principal do texto de cada página, excluindo qualquer marcação HTML ou elementos estruturais.
Função Python para extração de texto
Abaixo está uma função Python que demonstra como extrair conteúdo de texto de páginas HTML e armazená-lo em arquivos de texto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
de bs4 importação BeautifulSoup def get_data(conteúdo_ html): sopa = BeautifulSoup(conteúdo_ html, "html.parser") título = str(sopa).dividir(' se " | Documentos do Couchbase" em título: título = título[:(título.índice(" | Documentos do Couchbase"))].substituir(" ", "_") mais: título = título.substituir(" ", "_") dados = "" linhas = sopa.find_all('p') para linha em linhas: dados += " " + linha.texto retorno título, dados |
Como usar?
Para usar o get_data() incorpore-a em seu script ou aplicativo Python e forneça o conteúdo HTML como parâmetro. A função retornará o conteúdo de texto extraído.
|
1 2 3 4 |
conteúdo_ html = '<html><head><title>Sample Page</title></head><body><p>Este é um exemplo de parágrafo.</p></body></html>' título, texto = get_data(conteúdo_ html) impressão(título) Saída #: Sample_Page impressão(texto) # Output: Este é um exemplo de parágrafo. |
Extração de conteúdo de texto de PDFs
Para extrair o conteúdo de texto de PDFs, usaremos um script Python que lê um arquivo PDF e recupera seus dados. Esse processo garante que todas as informações textuais relevantes sejam capturadas para análise.
Função Python para extração de texto
Abaixo está uma função Python que demonstra como extrair conteúdo de texto de PDFs:
|
1 2 3 4 5 6 7 8 |
de PyPDF2 importação PdfReader def extract_text_from_pdf(pdf_file): leitor = PdfReader(pdf_file) texto = '' para página em leitor.páginas: texto += página.extract_text() retorno texto |
Como usar?
Para usar a função extract_text_from_pdf(), incorpore-a em seu script ou aplicativo Python e forneça o caminho do arquivo PDF como parâmetro. A função retornará o conteúdo do texto extraído.
|
1 2 |
pdf_path = 'sample.pdf' texto = extract_text_from_pdf(pdf_path) |
Com o conteúdo de texto extraído e salvo, concluímos o processo de obtenção de dados da documentação do Couchbase.
Agrupamento: Tornando os dados gerenciáveis
Imagine que você tenha um romance longo e queira criar um resumo. Em vez de ler o livro inteiro de uma vez, você o divide em capítulos, parágrafos e frases. Dessa forma, você pode entender e processar facilmente cada parte, tornando a tarefa mais gerenciável. Da mesma forma, o chunking no processamento de texto ajuda a dividir textos grandes em unidades menores e significativas. Ao organizar o texto em partes gerenciáveis, podemos facilitar o processamento, a recuperação e a análise das informações.
Chunking semântico e de conteúdo para RAG
Para o Retrieval-Augmented Generation (RAG), a fragmentação é particularmente importante. Implementamos métodos de fragmentação semântica e de conteúdo para otimizar os dados para o processo RAG, que envolve a recuperação de informações relevantes e a geração de respostas com base nessas informações.
Divisor de texto de caracteres recursivo

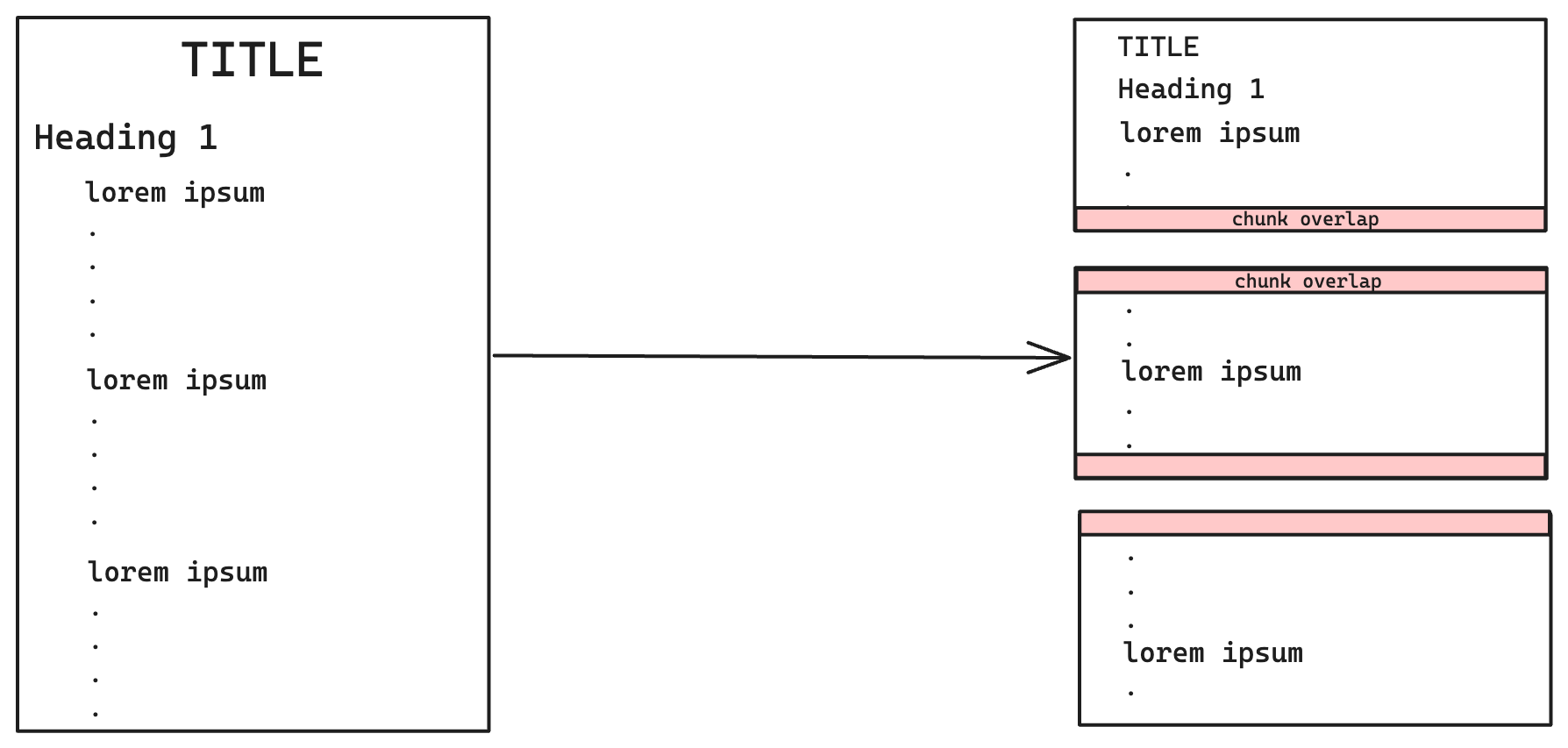
Divisor de texto de caracteres recursivo O chunking by Langchain envolve a divisão de um trecho de texto em pedaços menores usando padrões recursivos nos caracteres do texto. Essa técnica utiliza separadores como \n\n (nova linha dupla), \n (nova linha), (espaço) e "" (string vazia).
Agrupamento semântico


A fragmentação semântica é uma técnica de processamento de texto que se concentra no agrupamento de palavras ou frases com base em seu significado semântico ou contexto. Essa abordagem melhora a compreensão ao criar blocos significativos que capturam as relações subjacentes no texto. Ela é particularmente útil para tarefas que exigem uma análise detalhada da estrutura do texto e da organização do conteúdo.
Implementação de fragmentação semântica e de conteúdo
Em nosso projeto, implementamos métodos de fragmentação semântica e de conteúdo. A fragmentação semântica preserva a estrutura hierárquica do texto, garantindo que cada bloco mantenha sua integridade contextual. A fragmentação de conteúdo foi aplicada para remover pedaços redundantes e otimizar a eficiência do armazenamento e do processamento.
Implementação do Python
Aqui está uma implementação em Python de chunking semântico e de conteúdo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
importação hashlib de langchain.divisor de texto importação RecursiveCharacterTextSplitter # Conjunto global para armazenar valores de hash de bloco exclusivos em todos os arquivos global_unique_hashes = definir() def hash_text(texto): # Gerar um valor de hash para o texto usando SHA-256 objeto_hash = hashlib.sha256(texto.codificar()) retorno objeto_hash.hexadecimal() def chunk_text(texto, título, Tamanho do pedaço=2000, Sobreposição=50, Função_de_comprimento=len, debug_mode=0): global global_unique_hashes pedaços = RecursiveCharacterTextSplitter( tamanho do bloco=Tamanho do pedaço, chunk_overlap=Sobreposição, função_de_comprimento=Comprimento_função ).criar_documentos([texto]) se debug_mode: para idx, pedaço em enumerar(pedaços): impressão(f"Chunk {idx+1}: {chunk}\n") impressão('\n') # Mecanismo de desduplicação pedaços únicos = [] para pedaço em pedaços: chunk_hash = hash_text(pedaço.conteúdo_da_página) se chunk_hash não em global_unique_hashes: pedaços únicos.anexar(pedaço) global_unique_hashes.adicionar(chunk_hash) para sentença em pedaços únicos: sentença.conteúdo_da_página = título + " " + sentença.página_conteúdo retorno pedaços únicos |
Esses blocos otimizados são então incorporados e armazenados no cluster do Couchbase para recuperação eficiente, garantindo uma integração perfeita com o processo RAG.
Ao empregar técnicas de chunking semântico e de conteúdo, estruturamos e otimizamos efetivamente os dados textuais para o processo RAG e o armazenamento no cluster do Couchbase. A próxima etapa é incorporar os blocos que acabamos de gerar.
Incorporação de partes: Mapeando a galáxia de dados
Imagine cada bloco de texto como uma estrela em uma vasta galáxia. Ao incorporar esses pedaços, atribuímos a cada estrela um local preciso nessa galáxia, com base em suas características e relacionamentos com outras estrelas. Esse mapeamento espacial nos permite navegar pela galáxia com mais eficiência, encontrando conexões e compreendendo o universo mais amplo de informações.
Incorporação de partes de texto para RAG
A incorporação de partes de texto é uma etapa crucial no processo de Geração Aumentada por Recuperação (RAG). Ela envolve a transformação do texto em vetores numéricos que capturam o significado semântico e o contexto de cada bloco, facilitando a análise e a geração de respostas pelos modelos de aprendizado de máquina.
Utilização do modelo BGE-M3 da BAAI
Para incorporar os blocos, usamos o BAAI modelo BGE-M3. Esse modelo é capaz de incorporar o texto em um espaço vetorial de alta dimensão, capturando o significado semântico e o contexto de cada bloco.
Função de incorporação
A função de incorporação pega os blocos gerados na etapa anterior e incorpora cada bloco em um espaço vetorial de 1024 dimensões usando o modelo BAAI BGE-M3. Esse processo aprimora a representação de cada bloco, facilitando uma análise mais precisa e contextualmente rica.
Script Python para incorporação
Aqui está um script Python que demonstra como incorporar blocos de texto usando o modelo BAAI BGE-M3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
importação json importação numérico como np de json importação Codificador JSONE de baai_model importação BGEM3FlagModel embed_model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=Verdadeiro) classe NumpyEncoder(Codificador JSONE): def padrão(autônomo, obj): se isinstância(obj, np.ndarray): retorno obj.Lista de usuários() retorno Codificador JSONE.padrão(autônomo, obj) def incorporar(pedaços): embedded_chunks = [] para sentença em pedaços: emb = embed_model.codificar(str(sentença.conteúdo_da_página), tamanho_do_lote=12, max_length=600)['dense_vecs'] incorporação = np.matriz(emb) np.set_printoptions(suprimir=Verdadeiro) json_dump = json.lixeiras(incorporação, cls=NumpyEncoder) pedaço incorporado = { "dados": str(sentença.conteúdo_da_página), "vector_data": json.cargas(json_dump) } embedded_chunks.anexar(pedaço incorporado) retorno embedded_chunks |
Como usar?
Para usar a função embed(), incorpore-a em seu script ou aplicativo Python e forneça os blocos gerados nas etapas anteriores como entrada. A função retornará uma lista de blocos incorporados.
|
1 2 3 4 5 6 7 |
pedaços = [ # Assume chunks is a list of text chunks generated previously {"page_content": "Esta é a primeira parte do texto."}, {"page_content": "Esta é a segunda parte do texto."} ] embedded_chunks = incorporar(pedaços) |
Esses blocos otimizados, agora incorporados em um espaço vetorial de alta dimensão, estão prontos para armazenamento e recuperação, garantindo a utilização eficiente dos recursos e a integração perfeita com o processo RAG. Ao incorporar os blocos de texto, transformamos o texto bruto em um formato que os modelos de aprendizado de máquina podem processar e analisar com eficiência, permitindo respostas mais precisas e contextualmente conscientes no sistema RAG.
Armazenamento de blocos incorporados: Garantindo uma recuperação eficiente
Depois que os blocos de texto forem incorporados, a próxima etapa é armazenar esses vetores em um banco de dados. Esses blocos incorporados podem ser inseridos em bancos de dados de vetores ou em bancos de dados tradicionais com suporte à pesquisa de vetores, como Couchbase, Elasticsearch ou Pinecone, para facilitar a recuperação eficiente para aplicativos Retrieval-Augmented Generation (RAG).
Bancos de dados vetoriais
Os bancos de dados vetoriais são projetados especificamente para manipular e pesquisar vetores de alta dimensão com eficiência. Ao armazenar partes incorporadas em um banco de dados vetorial, podemos aproveitar os recursos avançados de pesquisa para recuperar rapidamente as informações mais relevantes com base no contexto e no significado semântico das consultas.
Integração com aplicativos RAG
Com os dados preparados e armazenados, eles agora estão prontos para serem usados nos aplicativos RAG. Os vetores incorporados permitem que esses aplicativos recuperem informações contextualmente relevantes e gerem respostas mais precisas e significativas, aprimorando a experiência geral do usuário.
Conclusão
Seguindo este guia, preparamos com sucesso os dados para a Geração Aumentada por Recuperação. Cobrimos a coleta de dados usando o Scrapy, a extração de conteúdo de texto de HTML e PDFs, as técnicas de fragmentação e a incorporação de blocos de texto usando o modelo BAAI BGE-M3. Essas etapas garantem que os dados sejam organizados, otimizados e estejam prontos para uso em aplicativos RAG.
Para obter mais conteúdo técnico e envolvente, confira outros blogs relacionados à pesquisa de vetores em nosso site e fique atento à próxima parte desta série.