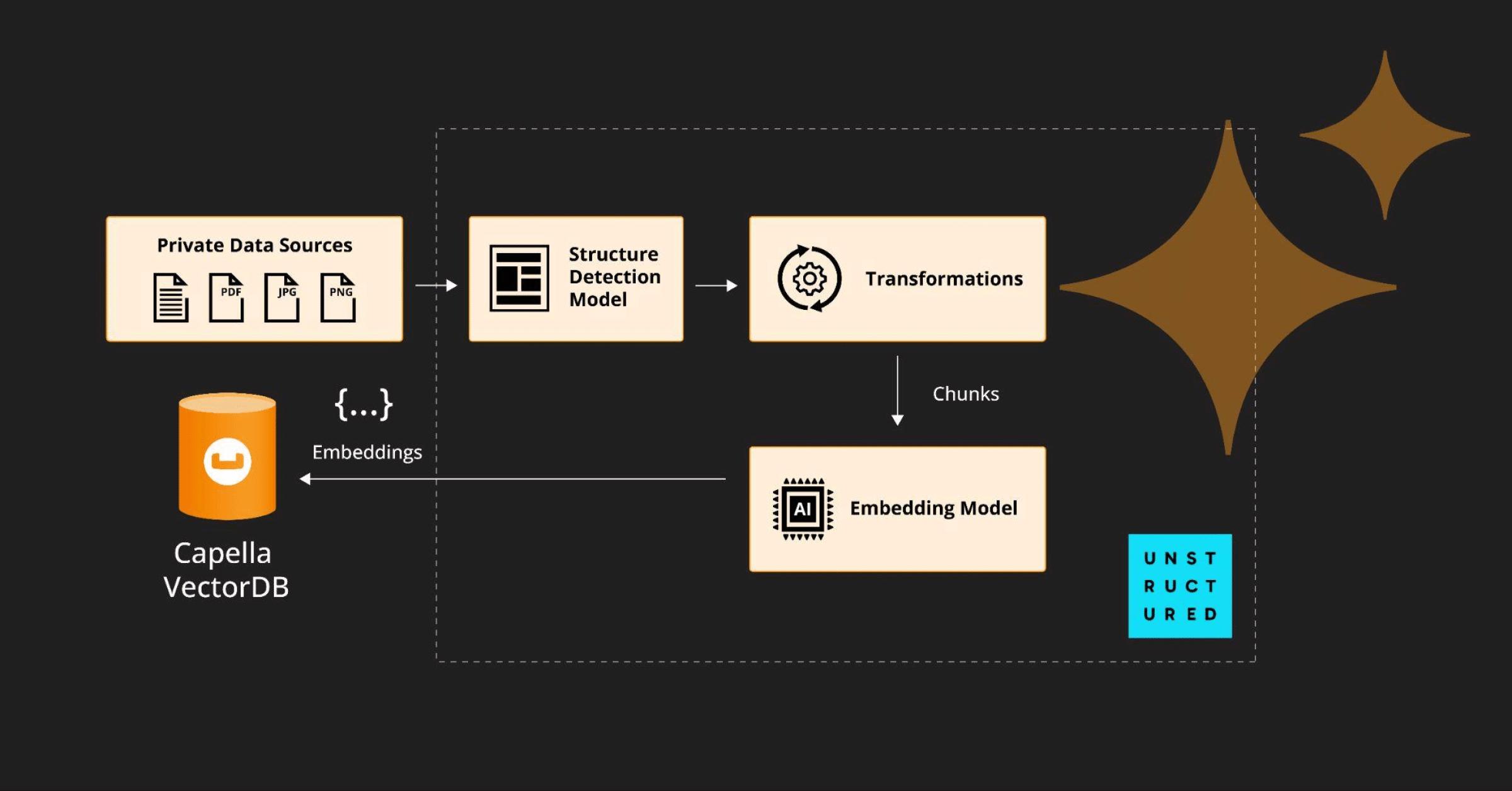
Today we’re excited to announce the launch of the Couchbase and Unstructured.io connector which streamlines the process of ingesting unstructured data into your RAG pipeline built on top of Couchbase as the vector store. Using this connector, you can now convert unstructured and loosely-structured documents into JSON files and make them ready for consumption by RAG applications via the generation of vector embeddings in just a few lines of code.
Why is unstructured data ingestion important for developers?
An overwhelming amount of enterprise data is unstructured and this is unlikely to change in the foreseeable future. The presence of data in unstructured formats has implications for developers beyond time and cost. It means that decision making in enterprises is predicated on the limited amount of consumable, structured data instead of all data residing within it. In addition to this, it means that a large variety of enterprise workflows (internal and customer facing) require manual intervention making them costlier, slower, and more error-prone. This problem is likely to become more acute as enterprise data footprints grow.
How is unstructured data leveraged by developers?
One of the most effective ways of leveraging unstructured data is to ingest it into a RAG pipeline, making the data available for retrieval via vector searches. This has wide-ranging applications in various industries. RAG applications can be leveraged to drive operational efficiency by making it easier to access more relevant documents, resulting in faster resolution times and lower costs. Some of the use cases that can be solved for are:
- Enabling customer support teams across industries to find relevant troubleshooting documents
- Enabling medical professionals to extract relevant articles and patient records stored in document databases to assist in diagnosis and treatment planning
- Recommendation systems that leverage customer data to suggest the most suitable product
What is the current way of processing unstructured data?
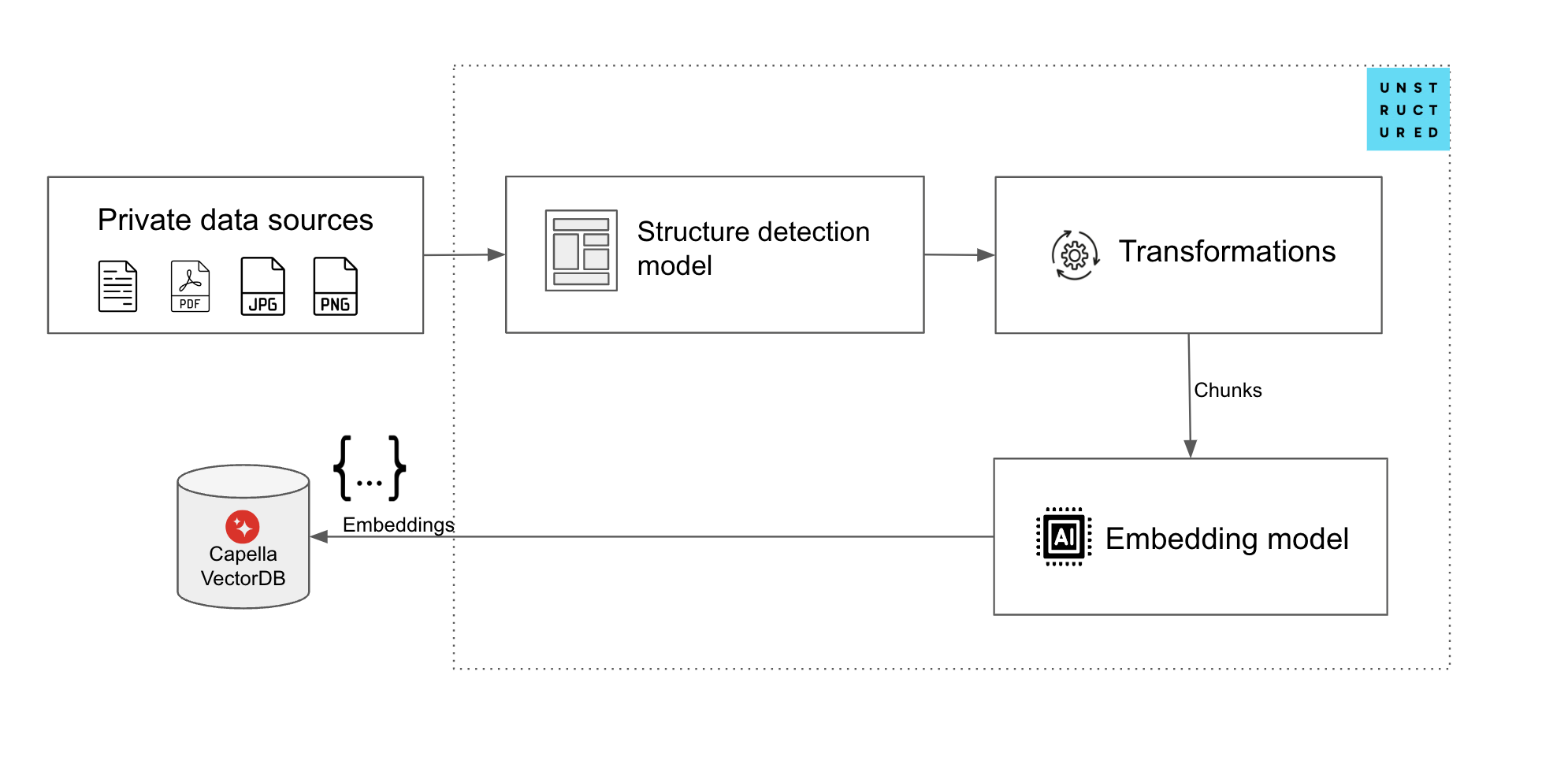
The current way of accomplishing this (ingesting unstructured data for RAG applications) with Couchbase Capella, would require developers to write applications to connect to an unstructured data extractor, parse its output, chunk it, and then send it to an embedding model for generating vectors which then would have to be sent to a vector DB on Couchbase Capella.
How does our connector improve the current method of ingesting unstructured data?
The unstructured.io – Couchbase connectors simplify the process of connecting the two aforementioned primary elements of the ingestion pipeline, making it easier to:
- Convert unstructured text data into structured JSON documents
- Generate the corresponding vectors
- Insert them into Couchbase Capella
The source connector helps fetch data from Couchbase Capella before it is chunked (and optionally vectorized) while the destination connector helps ingest processed data from unstructured.io into Couchbase Capella.
Capella is a high performance vector database that lets you swiftly set up, index, and query a vector database. Here’s how you can leverage the connectors to start processing your documents with just a few lines of code.
Step 1: Prerequisites
Before you start using the connector you will need to get a few prerequisites in place. You will need:
- An API key from unstructured.io which can be obtained by creating an unstructured.io account
- An active Capella account with a cluster and database set up as well as scope and collections defined within the database
- To configure the cluster to use your IP address
- To configure the database credentials
Step 2: Define the source of your unstructured data and the destination
Once the prerequisites are in place you can define the source for the documents that you want to process and use as inputs for your production RAG pipeline. The connector supports ingestion from various sources: Couchbase, local directories, S3 buckets, and other storage services. Unstructured.io supports a wide variety of unstructured document formats including PDFs, image files (JPEG, PNG), text documents (DOCX, DOC), emails, spreadsheets, and presentation file formats (PPT).
Similarly, define the intermediate location that will be used to store the output generated by unstructured.io before the text is vectorized. This can be a collection on a performant, scalable database on Couchbase or any other storage service that you’re currently using. You can then define the Vector database collection on Couchbase where the JSON documents containing the original text, metadata, and the corresponding embedding vector will be stored.
Step 3: Define your chunking strategy and select an embedding model for generation of vector embeddings
Once the input and output locations are defined, you can select one of the chunking strategies supported by unstructured.io and pick an embedding model of your choice. Unstructured.io supports embedding models from several providers such as Huggingface, OpenAI and Bedrock among others.
Step 4: Run your application!
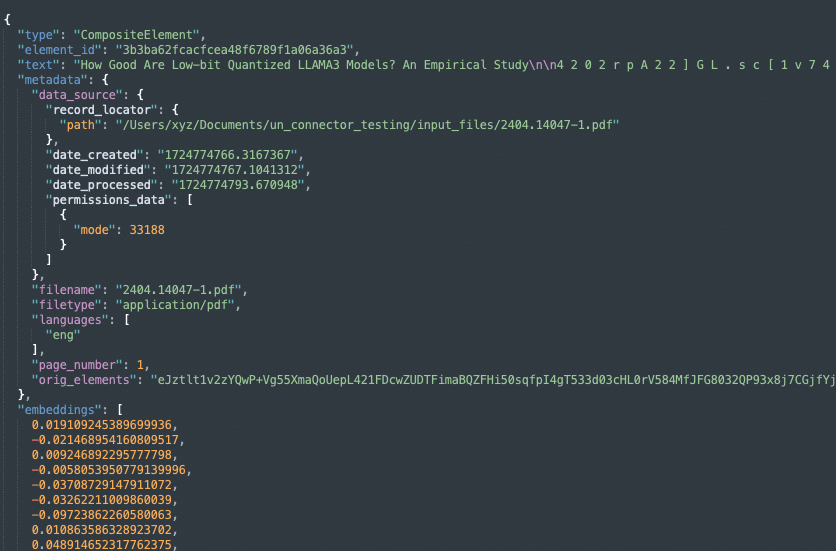
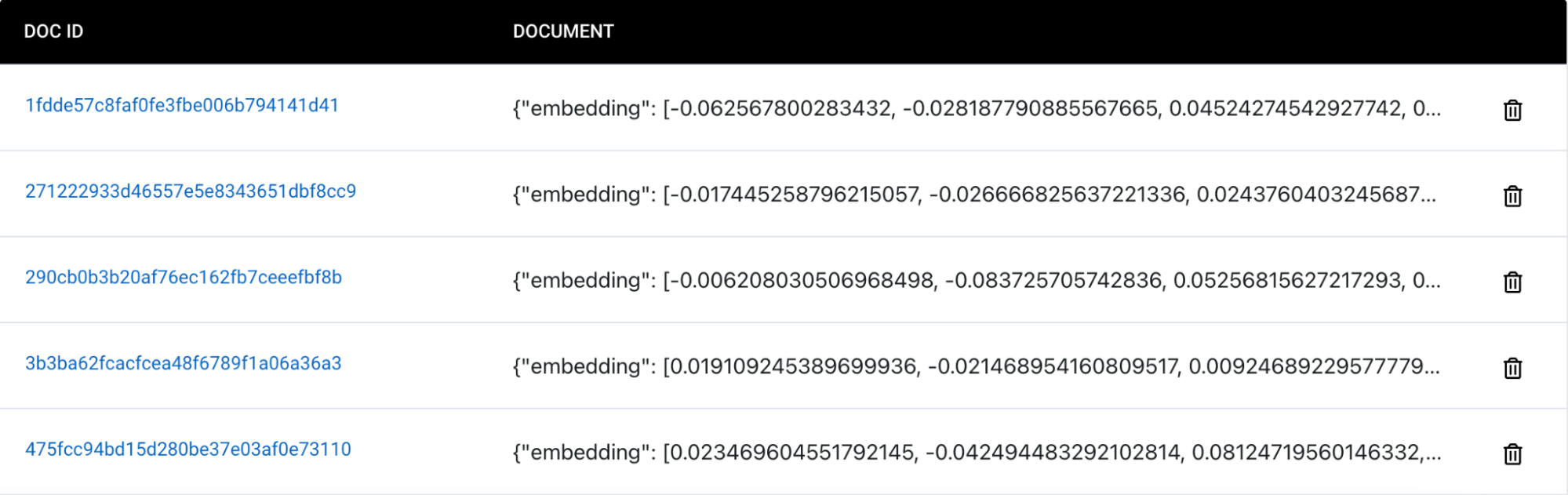
Test your application. You should be able to view the new structured JSON documents inserted into your Capella collection after all the processing steps executed via unstructured.io. Below is an example of the files that we converted from a PDF to JSON and ingested into a Couchbase Capella collection. For a step-by-step guide along with the code on how to do this, check out our full tutorial here. You can also use our notebook to follow along.
Unstructured document example:

Output from unstructured.io:
Documents ingested into Capella:
You can now run your application to process unstructured text documents, identify the components, extract them as JSON documents and generate vector embeddings before inserting them into your Capella collection.
Resources
- Building End-to-End RAG Applications With Couchbase Vector Search
- Build Performant RAG Applications Using Couchbase Vector Search and Amazon Bedrock
- Coding With AI: Vector Search and RAG (Webcast)
- Try Couchbase Capella for free today
Deixe um comentário
Você precisa fazer o login para publicar um comentário.