 NoSQL database systems have firmly established their presence for more than a decade, garnering substantial market share in the OLTP database domain. The rapid adoption of NoSQL databases for OLTP use cases can be attributed to key factors such as scalability and availability, along with robust support for agile development through flexible schema design and enhanced performance.
NoSQL database systems have firmly established their presence for more than a decade, garnering substantial market share in the OLTP database domain. The rapid adoption of NoSQL databases for OLTP use cases can be attributed to key factors such as scalability and availability, along with robust support for agile development through flexible schema design and enhanced performance.
The cornerstone of agile development practices for modern application developers lies in the flexibility offered by a document model, enabling swift adaptation to evolving business requirements. This has effectively liberated developers from dependency on database administrators, eliminating bottlenecks and the need to adhere to enterprise database change windows.
Let us consider a sample library application having a JSON Schema
|
1 2 3 4 5 6 7 8 9 |
{ “book_id”: 1, “title”: “The Great Gatsby”, “author”: “F. Scott Fitzgerald”, “publishers”: [ {“name”: “Scribner”, “year”: 1925}, {“name”: “Vintage Books”, “year”: 1995} ] } |
Introducing the genre of a book into our library application is a straightforward task for the application developer. This entails a simple adjustment—adding a new array field called genre to the document. Given that a book can belong to multiple genres, this flexible approach accommodates the dynamic nature of book categorization effortlessly.
|
1 2 3 4 5 6 7 8 9 10 |
{ “book_id”: 1, “title”: “The Great Gatsby”, “author”: “F. Scott Fitzgerald”, “genres”: [“Fiction”, “Classic”], “publishers”: [ {“name”: “Scribner”, “year”: 1925}, {“name”: “Vintage Books”, “year”: 1995} ] } |
Does the data lifecycle culminate with an OLTP application? The unequivocal answer is no.
Many OLTP applications seamlessly flow into downstream analytical systems, such as real-time analytics, data marts, data warehouses, or data lakes. However, a significant challenge arises because the majority of analytics database systems worldwide are built on relational database models, expecting a fixed, tabular, relational format for stored data.
Herein lies a noteworthy predicament: while upstream OLTP NoSQL database systems boast a flexible schema with a document model—where each document may possess a distinct schema, and documents can encapsulate nested documents or arrays—converting this diverse data back into the relational world induces considerable ETL (Extract, Transform, Load) challenges. However, the issue extends beyond ETL challenges alone.
The flexibility of schema and document model support in OLTP applications means that developers are no longer bound to coordinate database changes with a Database Administrator (DBA), leading to rapid and dynamic evolution of the application schema. In contrast, downstream systems, inherently relational in nature, struggle to keep pace with the constant evolution of the schema. To illustrate this issue, let’s revisit our example of the library application.
Assuming this library application has a underlying relational analytical database, the schema would look something like the following.
Book Table
| book_id | title | author |
|---|---|---|
| 1 | The Great Gatsby | F. Scott Fitzgerald |
Publisher Table
| publisher_id | name | year |
|---|---|---|
| 1 | Scribner | 1925 |
| 2 | Vintage Books | 1995 |
Book_Publisher Table
| book_id | publisher_id |
|---|---|
| 1 | 1 |
| 1 | 2 |
If we need to convey the straightforward addition of the genre field in the NoSQL OLTP database documents to the downstream analytics system, the process involves the following.
We would introduce 2 new tables: Genre and Book_Genre.
Genre Table
| genre_id | name |
|---|---|
| 1 | Fiction |
| 2 | Classic |
Book_Genre Table
| book_id | genre_id |
|---|---|
| 1 | 1 |
| 1 | 2 |
Furthermore, the ETL application responsible for supplying data to the relational analytical system must undertake the task of decomposing the genre array within each document and populating the resulting information into the corresponding tables for every document.
From the examples provided above, it’s evident that constructing real-time analytical applications and synchronizing with the dynamic changes in upstream OLTP NoSQL databases pose challenges for Relational Analytical systems. Despite these challenges, why do enterprises persist in building relational analytical systems, especially when the upstream OLTP systems lean towards a NoSQL document-oriented nature? To delve deeper into this, let’s explore the fundamental principles that underpin database systems designed for analytics.
Analytical queries often involve handling extensive datasets with intricate joins, aggregations, and multiple layers of filtering. Many of these operations can be significantly expedited by executing them in parallel across a network of servers. This necessitates that database systems designed for analytics possess robust Massive Parallel Processing capabilities, enabling the distribution of a query plan across multiple physical servers to enhance the speed of query execution.
Analytical queries commonly focus on retrieving a specific subset of columns from the entire dataset. Therefore, Column-oriented databases are favored in analytical use cases because they optimize I/O operations. By selectively fetching only the columns relevant to a query, these databases minimize the need to retrieve all column information from the disk, resulting in more efficient query performance.
Analytical queries are inherently intricate and can yield multiple potential execution plans. In the realm of database systems for analytics, it is paramount for these systems to go beyond rule-based planning and employ a Cost-Based Query Optimizer. This optimizer plays a crucial role in identifying the most efficient query plan by considering a range of cost factors, ensuring optimal execution of complex analytical queries.
Analytical databases are designed for horizontal scalability, enabling the seamless addition of compute resources to an existing database cluster. This scalability serves to reduce query runtimes and accommodate additional queries. Particularly in cloud environments, where the swift addition and removal of compute resources is feasible, it becomes imperative to adopt an analytics database architecture that emphasizes Storage-Compute Separation. This design facilitates the swift scaling or contraction of the database cluster, ensuring adaptability to varying workloads.
Historically, NoSQL document-oriented databases did not meet the above four essential principles required by analytical database systems. Consequently, enterprises persisted in utilizing relational databases for analytical systems, even when the upstream OLTP database adopted a NoSQL approach. This decision was driven by the limitations outlined earlier.
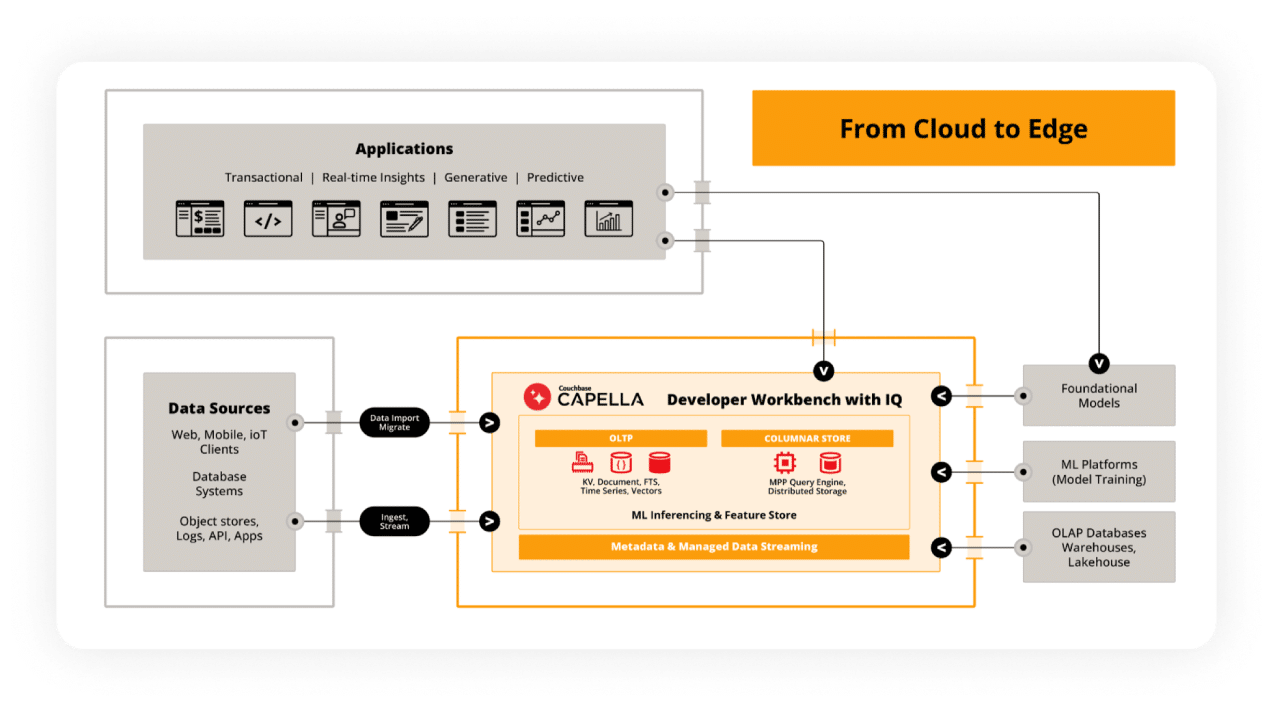
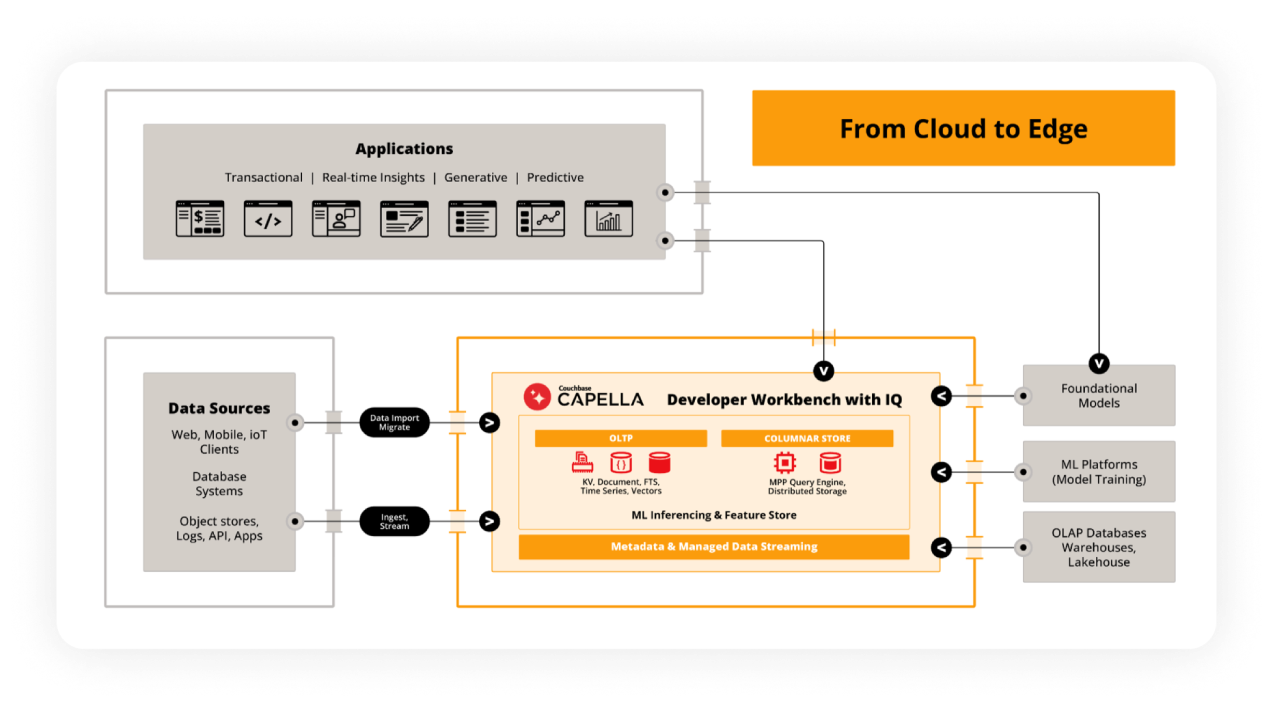
Couchbase Analytics to the rescue!
Couchbase Analytics stands as a NoSQL Document-oriented, Storage-Compute Separated, Massively Parallel Columnar Database Cloud Service equipped with an integrated Cost-Based Optimizer. Addressing all the crucial principles of a high-performance analytical database, Couchbase Analytics preserves the beloved Flexible Document-Oriented data model. Empowering enterprises to construct real-time analytical systems, it significantly reduces the ETL effort and time required for ingesting data from upstream NoSQL OLTP databases. Moreover, it ensures that analytical applications stay synchronized with the most recent business data arriving from upstream transactional systems.
Learn more about how Couchbase Analytics addresses your needs:
- Read Couchbase Analytics Adds Real-time Data Service
- Watch Couchbase Announces New Analytics Service
Leave a comment
You must be logged in to post a comment.