저는 최근에 쿼리에 N1QL을 사용하는 프로젝트를 진행 중이었습니다. 카우치베이스 서버 데이터. 이것은 저예산 Amazon EC2 인스턴스에서 호스팅하던 내부 Java 애플리케이션이었습니다. 여기서 제 문제는 쿼리가 엄청나게 느리게 실행된다는 것이었습니다. 그 이유는 매우 일반적인 기본 인덱스만 가지고 있었기 때문입니다.
쿼리 속도를 높이기 위해 제가 수행한 작업과 그 과정에서 고려해야 했던 몇 가지 사항을 살펴보겠습니다.
먼저 제가 사용하고 있는 Couchbase Server 버전을 공유하는 것이 좋을 것 같습니다. 저는 저전력 컴퓨터에서 Couchbase Server 4.1을 사용하고 있습니다. 제가 작업하고 있는 버킷에는 다양한 유형의 문서가 약 10만 개 들어 있습니다. 이 글에서는 중요하지 않지만, 이 데이터에 액세스하는 애플리케이션은 Couchbase Java SDK를 사용하여 Java로 빌드되었습니다.
설정을 마쳤으니 이제 제가 실행한 쿼리 중 하나를 공유해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 |
선택 MILLIS_TO_UTC(날짜, '2006-01-12') AS 트윗 날짜, COUNT(*) AS 카운트 FROM `기본값` 어디 유형='트윗' 그룹 BY MILLIS_TO_UTC(날짜, '2006-01-12') 주문 BY 트윗 날짜 ASC |
이 쿼리는 특정 날짜에 저장한 총 트윗 수를 반환합니다. 시간 정보는 저에게는 중요하지 않았습니다. 처음에 저는 기본 인덱스인 단일 인덱스만 가지고 있었습니다. 위의 쿼리는 실행하는 데 상당한 시간이 걸립니다.
바로 이 지점에서 전략을 재평가하기 시작했습니다.
저는 Couchbase 4.1에서 제공된 커버링 인덱스를 활용하기로 결정했습니다. 쿼리 내에서 사용될 모든 속성을 포함하는 인덱스를 만들 때입니다. My 인덱스 생성 문은 다음과 같습니다:
|
1 2 3 4 5 |
만들기 INDEX twitter_by_date 켜기 `기본값` (날짜, 유형) 어디 유형 = '트윗' 사용 GSI; |
예, 집계를 수행하고 있지만 하루가 끝날 때만 날짜 그리고 유형 속성으로 변경했습니다. 그래서 커버링 인덱스를 사용하여 쿼리를 다시 실행했지만 성능에는 아무런 변화가 없었습니다.
이로 인해 저는 설명 를 쿼리 자체에 추가하여 문제를 해결하세요.
|
1 2 3 4 5 6 7 8 9 |
설명 선택 MILLIS_TO_UTC(날짜, '2006-01-12') AS 트윗 날짜, COUNT(*) AS 카운트 FROM `기본값` 어디 유형='트윗' 그룹 BY MILLIS_TO_UTC(날짜, '2006-01-12') 주문 BY 트윗 날짜 ASC |
쿼리 분석 결과를 보았을 때 설명 를 제공하면 여전히 사용하려고 하는 것을 볼 수 있습니다. #초급 인덱스를 삭제했습니다. 이는 커버링 인덱스가 이제 Couchbase에 존재한다는 것을 확인한 후에도 마찬가지입니다.
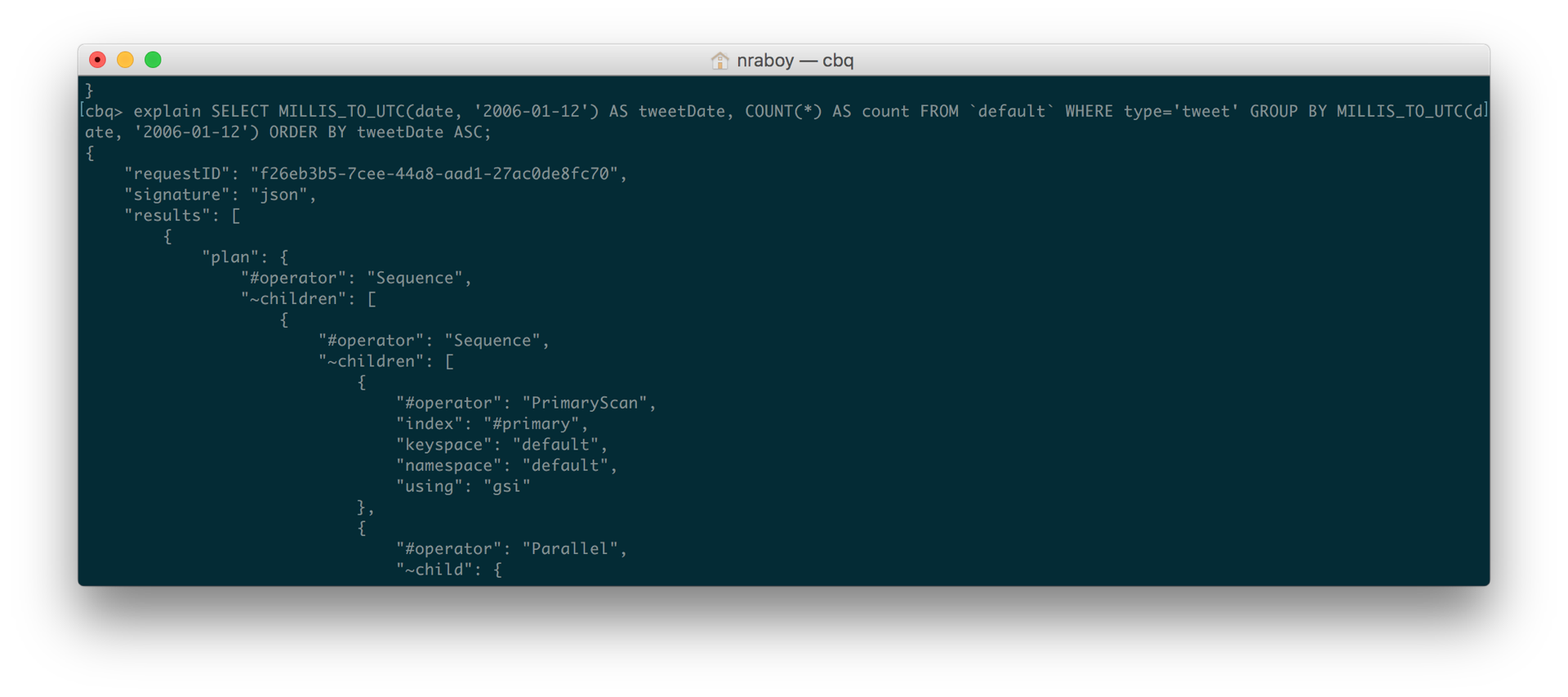
그러다가 제 버킷에 존재하는 데이터 유형이 트위터 문서만 있는 것이 아니라는 사실을 깨달았습니다. 다시 말해, 모든 문서에 날짜 모든 문서에 속성이 있는 것은 아닙니다. 유형 일치하는 트윗. 이제 이러한 시나리오를 확인하기 위해 실행하려는 쿼리를 수정해야 했습니다.
|
1 2 3 4 5 6 7 8 9 |
선택 MILLIS_TO_UTC(날짜, '2006-01-12') AS 트윗 날짜, COUNT(*) AS 카운트 FROM `기본값` 어디 유형='트윗' AND 날짜 IS NOT 누락 그룹 BY MILLIS_TO_UTC(날짜, '2006-01-12') 주문 BY 트윗 날짜 ASC |
위의 쿼리에서 특히 다음과 같이 추가한 것을 주목하세요. 날짜가 누락되지 않았습니다.. 먼저 날짜 속성이 존재합니다. 이미 해당 속성을 확인하고 있었습니다. 유형 일치 트윗가 있지만 다른 한 조각을 놓치고 있었습니다.
쿼리를 다시 실행한 결과 훨씬 빨라졌습니다. 다음을 포함했을 때 설명 이제 쿼리가 기본 인덱스가 아닌 커버링 인덱스를 사용하고 있음을 즉시 확인할 수 있었습니다.
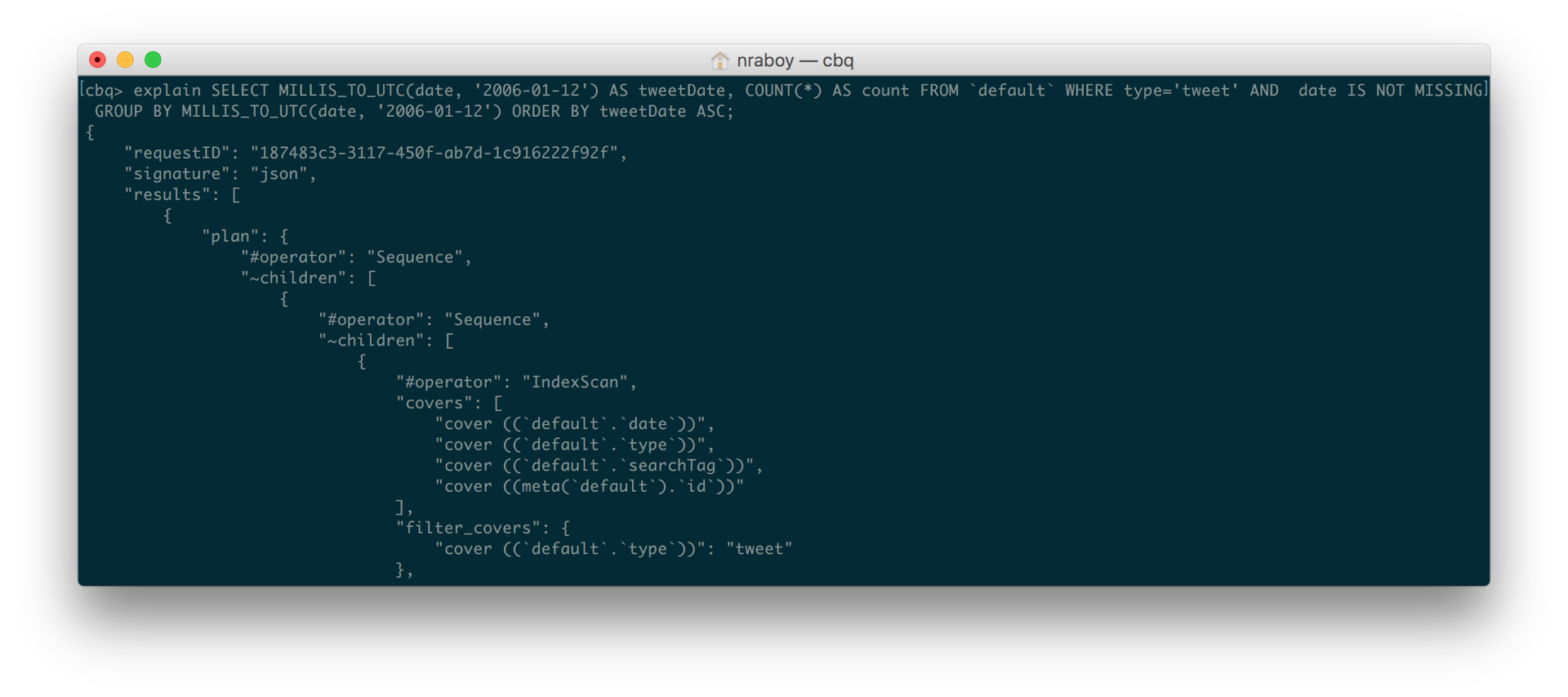
인덱스 커버링에 대해 자세히 알아보려면 다음을 방문하세요. 카우치베이스 개발자 포털.