I was recently working on a project that made use of N1QL for querying Couchbase Server data. This was an internal Java application that I was hosting on a low budget Amazon EC2 instance. My problem here is that my queries were running incredibly slow. The reason for this was that I only had a primary index that was very generic.
We’re going to take a look at what I did to speed up my queries and some of the things I had to consider during the process.
First off, it is probably a good idea to share what version of Couchbase Server I am using. I am using Couchbase Server 4.1 on my low powered machine. The bucket I’m working with has around 100,000 documents in it of varying types. Not that it matters for this article, but the application that accesses this data was built in Java using the Couchbase Java SDK.
With my setup out of the way, let me share one of the queries I was running:
|
1 2 3 4 5 6 7 8 9 |
SELECT MILLIS_TO_UTC(date, '2006-01-12') AS tweetDate, COUNT(*) AS count FROM `default` WHERE type='tweet' GROUP BY MILLIS_TO_UTC(date, '2006-01-12') ORDER BY tweetDate ASC |
This query would return the total number of Tweets that I had saved for any particular date. Time information was not important for me. Note that at the start I only had a single index, being my primary index. The above query would take quite some time to run.
This is where I started to re-evaluate my strategy.
I decided to take advantage of covering indexes that were made available in Couchbase 4.1. This is when we make an index that covers all properties that will be used within a query. My index creation statement for the previous query looked like this:
|
1 2 3 4 5 |
CREATE INDEX twitter_by_date ON `default` (date, type) WHERE type = 'tweet' USING GSI; |
Yes, I am doing aggregations, but at the end of the day I’m only querying based on the date and type properties. So I ran the query again with the covering index, but saw no change in performance.
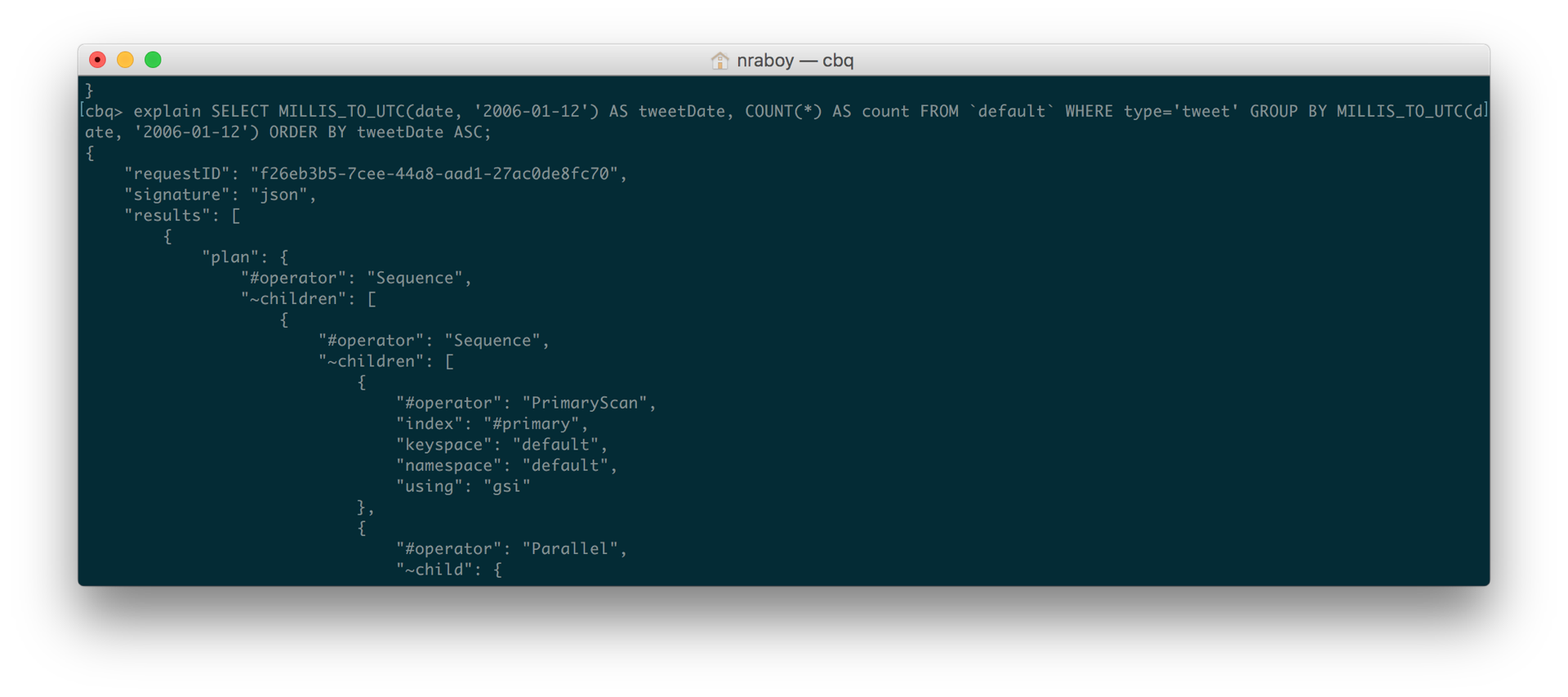
This lead me to running an EXPLAIN on the query itself to troubleshoot what was going on.
|
1 2 3 4 5 6 7 8 9 |
EXPLAIN SELECT MILLIS_TO_UTC(date, '2006-01-12') AS tweetDate, COUNT(*) AS count FROM `default` WHERE type='tweet' GROUP BY MILLIS_TO_UTC(date, '2006-01-12') ORDER BY tweetDate ASC |
When I saw the query breakdown that EXPLAIN provided me, I could see that it was still trying to use the #primary index that I had originally created. This is even after I validated that the covering index now existed in Couchbase.
Then I remembered that the Twitter documents weren’t the only types of data that existed in my bucket. In other words, not all documents had a property called date and not all documents had a property type that matched tweet. I now had to revise the query that I wanted to run to check for these scenarios.
|
1 2 3 4 5 6 7 8 9 |
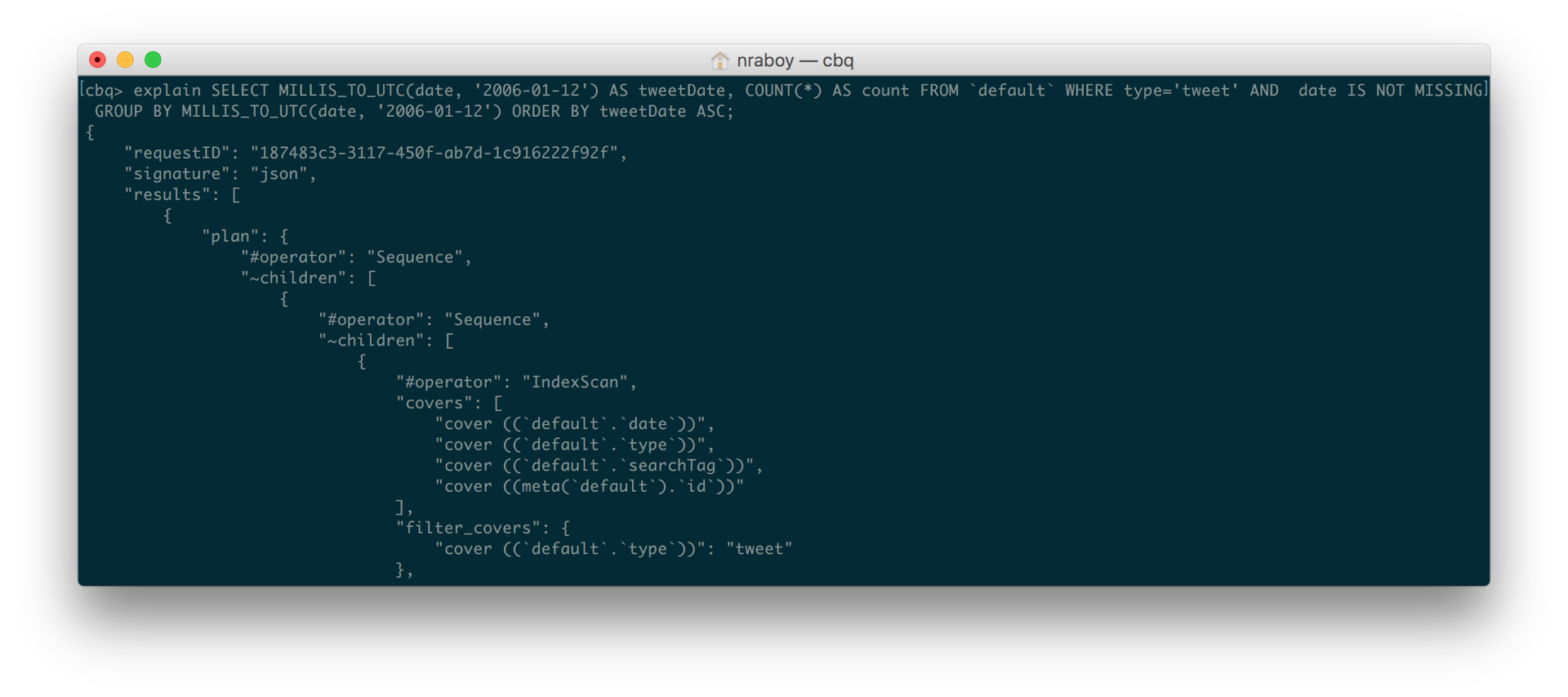
SELECT MILLIS_TO_UTC(date, '2006-01-12') AS tweetDate, COUNT(*) AS count FROM `default` WHERE type='tweet' AND date IS NOT MISSING GROUP BY MILLIS_TO_UTC(date, '2006-01-12') ORDER BY tweetDate ASC |
In the above query, notice in particular how I added AND date IS NOT MISSING. I’m first checking that the date property exists. We were already checking that property type matched tweet, but were missing the other piece.
After running the query again, it was significantly faster. When I included EXPLAIN I could immediately see that the query was now using the covering index rather than the primary index.
To learn more about covering indexes, visit the Couchbase Developer Portal.