"죽음과 세금 외에는 확실한 것은 없습니다."
이것은 데이터 세트가 아닙니다. 장미의 침대 또는 잘 다듬어진 녹색 잔디. 조금 더 심각합니다. 여기서 빠르게 배울 수 있는 것이 있는지 살펴봅시다. 데이터 세트는 다음과 같습니다.
"name" : "NCHS - 주요 사망 원인: 미국",
"속성" : "국립 보건 통계 센터",
대중 d아타셋은 다음에서 구입할 수 있습니다. https://data.cdc.gov/api/views/bi63-dtpu/rows.json?accessType=DOWNLOAD
1단계: 파일을 로컬 파일(예: health.json)로 다운로드합니다. 이 파일을 카우치베이스 클러스터의 노드 중 하나에 업로드합니다.
2단계라는 버킷으로 데이터를 가져옵니다. 버킷을 만든 후에는 기본 인덱스를 만듭니다. 쿼리를 위해 이 인덱스가 필요합니다.
/opt/couchbase/bin/cbimport json -c couchbase://127.0.0.1 -u 관리자 -p 비밀번호 -b 원인 -d 파일://health.json -g 원인:0 -f 샘플
> 원인에 기본 인덱스를 생성합니다;
3단계. 데이터의 구조를 검사합니다.
모든 데이터는 단일 JSON 문서로 제공됩니다. 따라서 INFER는 도움이 되지 않습니다. 구조를 수동으로 검사하고 이해해야 합니다. 이 데이터는 메타데이터에 각 엔티티의 의미와 함께 단순한 배열로 된 많은 데이터가 있는 일반적인 정부 데이터 세트입니다.
단순 배열:
|
1 |
<강한>선택 데이터 에서 원인 ;</강한> |
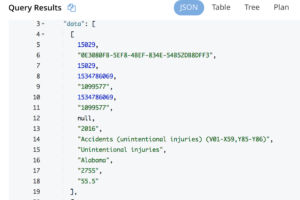
여기에는 스키마 없이 단순히 데이터 배열이 포함되어 있습니다. 공개 데이터 집합의 경우 스키마는 메타 필드에 있습니다.
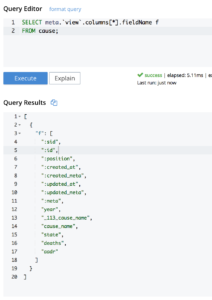
구조를 간단한 JSON 키-값 쌍으로 변환하여 좀 더 효과적으로 처리할 수 있도록 해보겠습니다. 이 마법이 어떻게 일어났는지 자세히 알아보세요. 이 문서에서.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
WITH cs AS ( 선택 메타.`보기`.열 [*].필드 이름 f, 데이터 FROM 원인 ) 선택 o FROM cs UNNEST cs.데이터 AS d1 LET o = 객체 p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END; |
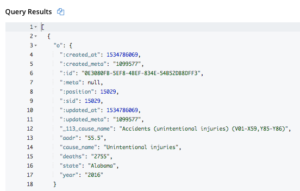
과제1: 한 주에서 연도별로 가장 많이 사망한 원인을 찾습니다.
WITH 절의 공통 테이블 표현식(CTE)은 복잡한 json 데이터를 플랫 JSON으로 변환합니다(csdata). 이 작업을 동적으로 수행하거나, 이 작업을 한 번 수행한 후 버킷에 다시 INSERT할 수 있습니다. 뉴욕 아기 이름. 이 글에서는 CTE를 사용합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
WITH csdata as ( WITH cs AS ( 선택 메타.`보기`.열 [*].필드 이름 f, 데이터 FROM 원인 ) 선택 o FROM cs UNNEST cs.데이터 AS d1 LET o = 객체 p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ) 선택 c.o.상태, c.o.년, c.o.원인_이름, COUNT(c.o.원인_이름), SUM(숫자(c.o.사망자 수)) 총 사망자 수 FROM csdata as c 어디 c.o.상태 <> "미국" 그리고 c.o.원인_이름 <> "모든 원인" 그룹 BY c.o.상태, c.o.년, c.o.원인_이름 주문 BY 총 사망자 수 DESC, c.o.상태, c.o.년 |
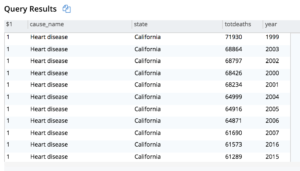
이 경우 캘리포니아의 모든 사망자는 주로 인구로 인해 가장 많이 발생합니다.
과제 2. 2016년 한 해 동안 각 주의 주요 사망 원인을 알아보세요.
쿼리 2: 이전 쿼리의 결과 집합을 사용한 다음 FIRST_VALUE() 창 함수를 사용하여 상위 원인을 확인합니다. OVER BY 절에서 상태별로 파티션을 나누면 상태별 파티션을 얻을 수 있고, OVER BY 절 내에서 ORDER BY dx.totdeaths를 사용하면 모든 상태의 상위 원인을 얻을 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
WITH csdata as ( WITH cs AS ( 선택 메타.`보기`.열 [*].필드 이름 f, 데이터 FROM 원인 ) 선택 o FROM cs UNNEST cs.데이터 AS d1 LET o = 객체 p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ), d2 as( 선택 c.o.상태, c.o.년, c.o.원인_이름, SUM(숫자(c.o.사망자 수)) 총 사망자 수 FROM csdata as c 어디 c.o.상태 <> "미국" 그리고 c.o.원인_이름 <> "모든 원인" 그리고 c.o.년 = "2016" 그룹 BY c.o.상태, c.o.년, c.o.원인_이름), d3 as ( 선택 dx.상태, dx.원인_이름, dx.총 사망자 수, FIRST_VALUE(dx.원인_이름) OVER(파티션 BY dx.상태 주문 BY dx.총 사망자 수 DESC) topreason, FIRST_VALUE(dx.총 사망자 수) OVER(파티션 BY dx.상태 주문 BY dx.총 사망자 수 DESC) topcount FROM d2 dx) 선택 d3 FROM d3 어디 d3.topcount = d3.총 사망자 수 주문 by d3.상태 |
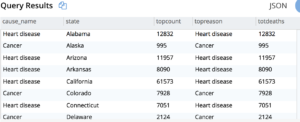
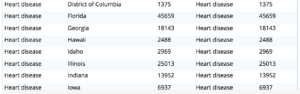
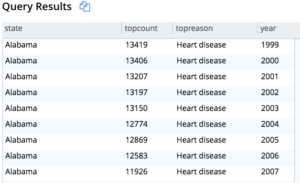
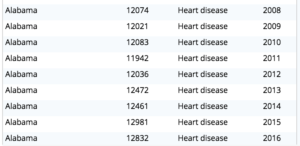
작업 3. 1999년부터 2016년까지 주별로 가장 큰 이유가 연도별로 어떻게 변화했는지 알아보세요.
쿼리 3: 모든 연도(199-2016)에 대한 보고서를 생성한 다음 주, 연도별로 그룹화하고 최고 이유에 대한 최대값(최고 수)을 구하여 최고 이유를 결정하면 최종적으로 최고 이유를 얻을 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
WITH csdata as ( WITH cs AS ( 선택 메타.`보기`.열 [*].필드 이름 f, 데이터 FROM 원인 ) 선택 o FROM cs UNNEST cs.데이터 AS d1 LET o = 객체 p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ), d2 as( 선택 c.o.상태, c.o.년, c.o.원인_이름, SUM(숫자(c.o.사망자 수)) 총 사망자 수 FROM csdata as c 어디 c.o.상태 <> "미국" 그리고 c.o.원인_이름 <> "모든 원인" 그룹 BY c.o.상태, c.o.년, c.o.원인_이름), d3 as ( 선택 dx.상태, dx.년, FIRST_VALUE(dx.원인_이름) OVER(파티션 BY dx.상태, dx.년 주문 BY dx.총 사망자 수 DESC ) topreason, FIRST_VALUE(dx.총 사망자 수) OVER(파티션 BY dx.상태, dx.년 주문 BY dx.총 사망자 수 DESC) topcount FROM d2 dx) 선택 d3.상태 , d3.년 , d3.topreason, 최대(d3.topcount) topcount FROM d3 그룹 BY d3.상태, d3.년, d3.topreason 주문 by d3.상태, d3.년 |
다음은 일부 결과입니다.
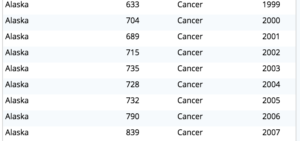
이를 시각화하면 다음과 같은 히스토그램이 나타납니다.
