다차원 스케일링을 발표하게 되어 기쁩니다.
다차원 확장을 통해 기업이 분산 데이터베이스를 확장하는 방식을 재구상하고 재정의했습니다. 쿼리, 인덱스, 데이터 등 개별 데이터베이스 서비스를 분리, 격리, 확장하여 성능과 리소스 활용도를 개선할 수 있는 옵션입니다.
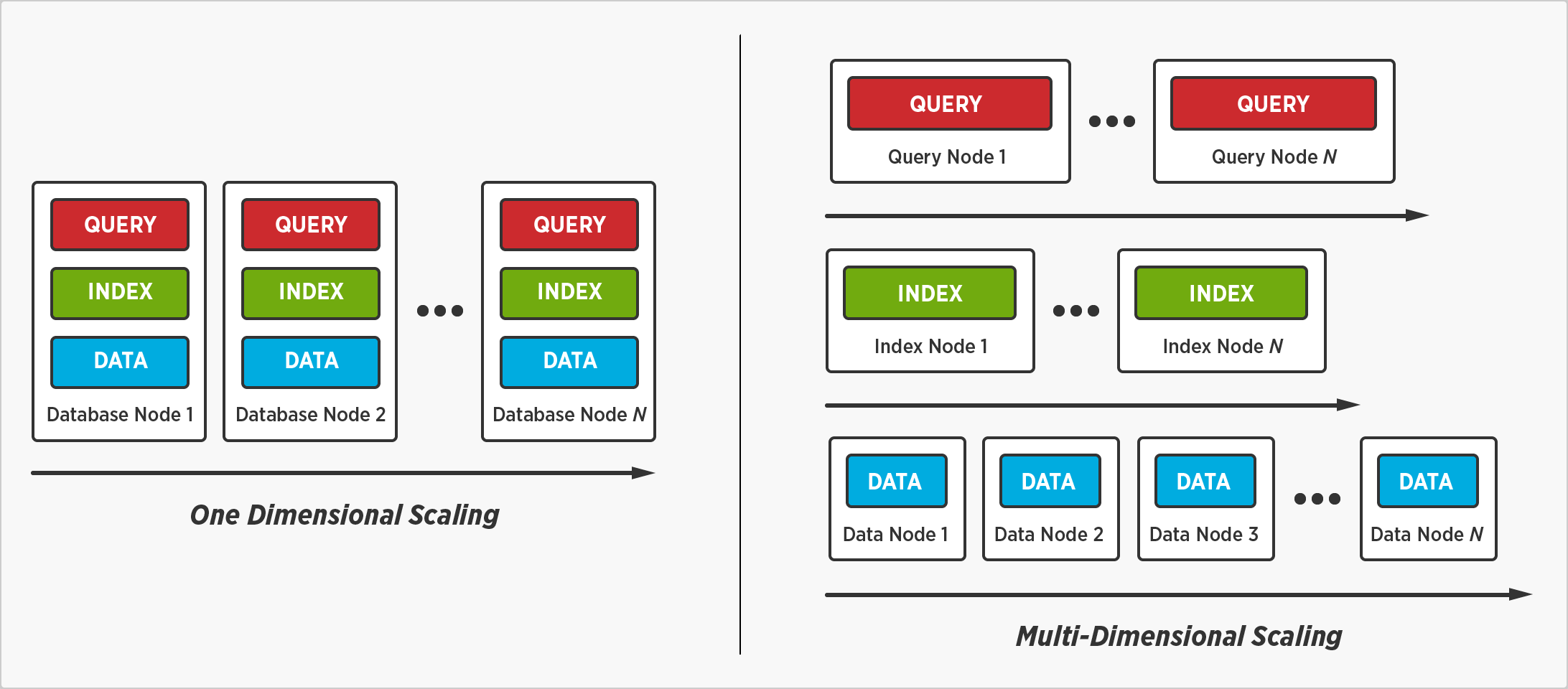
쿼리 실행 및 인덱스가 아닌 데이터 배포
다차원 스케일링을 사용하면 쿼리 실행과 인덱스를 분산하지 않고도 데이터를 분산할 수 있습니다. 쿼리는 모든 노드에서 실행되지 않을 때 더 빨리 완료되며, 인덱스는 모든 노드에 저장되지 않을 때 더 빨리 검색됩니다.
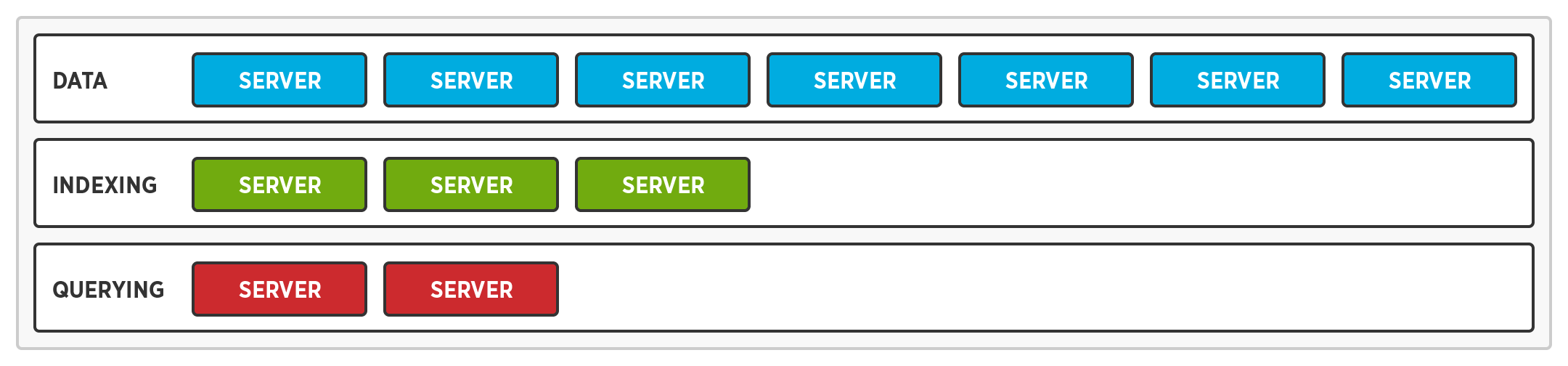
데이터베이스가 아닌 서비스용 하드웨어 최적화
다차원 확장을 사용하면 서로 다른 노드에서 서로 다른 서비스를 실행하여 여러 하드웨어 프로필을 지원할 수 있습니다. 따라서 모든 노드에 가장 빠른 프로세서, 가장 빠른 솔리드 스테이트 드라이브, 가장 많은 메모리를 필요로 하지 않습니다.
- 쿼리 노드에는 더 빠른 프로세서가 필요하지만 인덱스 및 데이터 노드에는 그렇지 않습니다.
- 인덱스 노드에는 더 빠른 솔리드 스테이트 드라이브가 필요하지만 쿼리 노드에는 필요하지 않습니다.
- 데이터 노드에는 더 많은 메모리가 필요하지만 쿼리 및 인덱스 노드는 그렇지 않습니다.
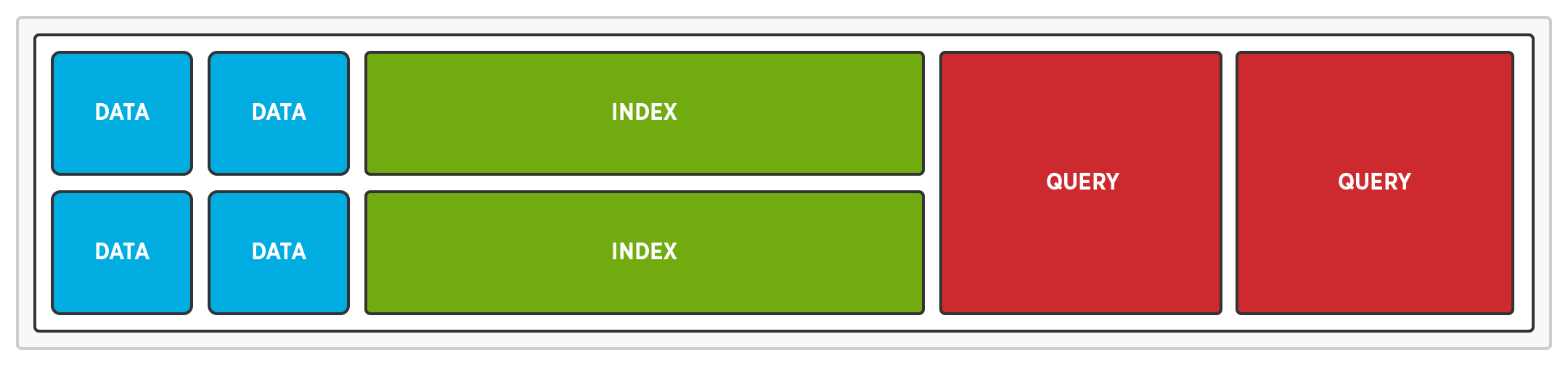
리소스 경합 제거
다차원 확장을 사용하면 서로 다른 노드에서 서로 다른 서비스를 실행하여 리소스 경합을 없앨 수 있습니다. 쿼리가 별도의 노드에서 실행되는 경우, 쿼리와 읽기 또는 쓰기 간에 CPU 경합이 발생하지 않습니다. 인덱스가 전용 노드에 저장되면 인덱스와 읽기 또는 쓰기 간에 디스크 IO 경합이 발생하지 않습니다.
다차원 스케일링은 다음과 같이 성능을 향상시킵니다:
- 별도의 노드에 데이터와 인덱스 저장 - 디스크 IO 경합 없음
- 별도의 노드에 데이터 저장 및 쿼리 실행 - CPU 경합 없음
- 모든 노드에 쿼리를 배포하지 않고 쿼리 실행 - 네트워크 오버헤드 없음
- 모든 노드에 인덱스를 배포하지 않고 저장 - 네트워크 오버헤드 없음
다차원 확장은 다음과 같이 리소스 활용도를 향상시킵니다:
- 빠른 프로세서, SSD 없음, 적은 메모리로 쿼리 서비스 노드 구성하기
- 빠른 SSD와 적은 메모리로 인덱스 서비스 노드 구성하기.
- 더 많은 메모리와 HDD 또는 SSD로 데이터 서비스 노드 구성하기.
개념
Elastic 서비스 데이터, 인덱스, 쿼리 서비스를 독립적으로 확장할 수 있습니다. 쿼리 또는 인덱스 서비스를 확장하지 않고도 데이터 서비스를 확장할 수 있습니다.
서비스 최적화 를 사용하면 실행 중인 서비스에 따라 노드의 하드웨어를 최적화할 수 있습니다. 결국 쿼리, 인덱스, 데이터 서비스에 대한 하드웨어 요구 사항은 서로 다릅니다.
서비스 격리 는 쿼리, 인덱스, 데이터 서비스가 리소스 경합을 겪지 않도록 보장합니다. 쿼리, 인덱스, 데이터 서비스를 격리하여 쿼리와 인덱스로 인해 읽기 및 쓰기 속도가 느려지는 것을 방지합니다.

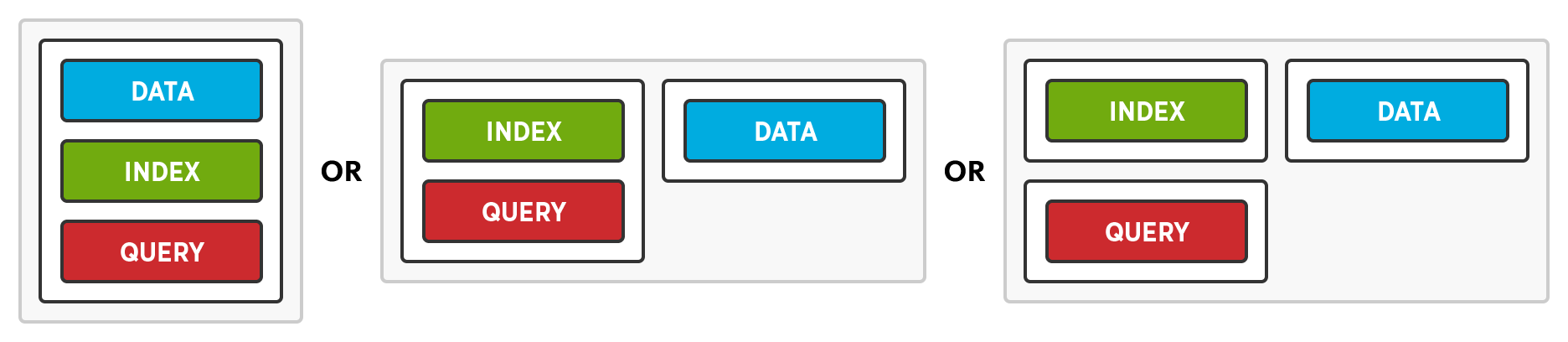
유연한 배포 를 통해 관리자는 다차원 확장을 활용할지 여부를 결정할 수 있습니다. 노드가 추가되면 관리자는 모든 서비스, 일부 서비스 또는 서비스 중 하나만 활성화할 수 있습니다.
다차원 확장에 대해 자세히 알아보고 Couchbase Server 4.0의 새로운 기능에 대해 알아보세요. 여기.
토론하기 해커 뉴스
데이터 로컬리티에 대해 생각해 본 적이 있나요? 사용자 정의 열에 의한 샤딩
"user_id\"와 같이 모든 데이터가 하나의 노드에 있고
간에 데이터가 전송되지 않으므로 복잡한 쿼리가 더 빨라집니다.
노드.
또는 기본 키의 하위 집합으로 샤딩할 수도 있습니다(redislabs에서 수행하는 정규식 샤딩처럼).
언급해 주셔서 감사합니다 - 정규식 샤딩 기능이 마음에 드신다니 정말 자랑스럽습니다 :)
그러면 쿼리가 사용자 정의 열이라는 단일 필드로 제한되지 않을까요? 사용자 도시별로 샤딩하여 도시별로 사용자를 쿼리할 수 있지만, 연령별로도 사용자를 쿼리하려면 어떻게 해야 할까요? 쿼리가 사용자와 구매를 결합하는 경우에는 어떻게 해야 할까요?
특정 노드/샤드를 대상으로 쿼리를 수행하려면 \"user_id\"를 포함하고 다른 절을 추가해야 합니다.
다른 속성으로 쿼리하려면(나이를 기준으로 모든 사용자를 가져오는 경우) 모든 노드를 조회해야 합니다.
이 방법의 문제점은 인덱스를 별도의 노드에 저장한다는 것입니다(따라서 기본 쿼리인 \"select column from user where whatever_filter (열이 색인되지 않음))\"에 대해서도 항상 노드 간 트래픽이 발생하게 됩니다).
귀하의 경우, 각 쿼리는 모든 인덱스 노드에 도달하게 되며, 아무리 빠르더라도 모든 데이터가 메모리에 있더라도 각 서버가 가진 CPU의 양이 한정되어 있기 때문에 모든 노드가 모든 쿼리에 응답해야 하므로 시간이 지나면 무너질 것입니다.
실제 확장성을 확보하는 유일한 방법은 자동 범위 파티셔닝 방식(예: hbase, hypertable)을 사용하는 것입니다(kv-access만으로는 애플리케이션을 구축할 수 없고, 일부 기능만 구축할 수 있습니다).
다른 방법(더 쉽고 기능은 적지만)은 사용자 정의 열로 샤딩을 만드는 것입니다.
이것이 바로 MDS의 장점입니다. 모든 노드를 공격하지는 않습니다. 도시에 대한 인덱스를 만들 수 있습니다. 전체 인덱스는 인덱스 노드 중 하나에 저장됩니다. 쿼리 노드는 이 인덱스 노드에 요청을 보냅니다. 이 인덱스 노드는 일치하는 모든 사용자 ID(도시=시카고)를 반환합니다. 그러면 쿼리 노드는 해당 사용자가 포함된 노드에서만 해당 사용자를 가져옵니다. 모든 노드에 요청을 보낼 필요는 없습니다.
인덱스가 1노드보다 커지면 어떻게 되나요?
인덱스를 분할하여 여러 인덱스 노드에 저장하는 것을 고려할 수 있을 것 같습니다. 하지만 Snappy로 압축할 때 얼마나 많은 인덱스가 테라바이트의 디스크 공간이 필요할지 궁금합니다.
테이블의 모든 객체를 인덱싱하고 싶다고 가정해 보겠습니다(보통 그렇게 하죠). 이제 모든 삽입/업데이트/삭제는 해당 인덱스 노드 1개로 이동해야 합니다.
가장 자주 사용하는 방법은 데이터+인덱스를 동일한 노드에 코로케이션하는 것입니다.
일종의 인덱스는 기본적으로 비동기식으로 업데이트됩니다. 인덱스 수에 관계없이 쓰기 속도가 느려지지 않습니다. 즉, 인덱스 업데이트를 먼저 강제하는 옵션과 함께 쿼리를 제출할 수 있습니다. 데이터와 인덱스를 함께 배치할 때 발생하는 몇 가지 문제는 네트워크 오버헤드와 조인입니다. 이 방법이 가장 많이 사용되는 이유는 1) 쉽고 2) 다른 벤더들이 조인을 제외하기 때문입니다. 다시 한 번 말씀드리지만, 여기서는 주 인덱스가 아닌 보조 인덱스에 대해 이야기하고 있습니다.