Me complace anunciar Escalado multidimensional.
Hemos reimaginado y redefinido la forma en que las empresas escalan una base de datos distribuida con Multi-Dimensional Scaling. Se trata de la opción de separar, aislar y escalar servicios de bases de datos individuales (consultas, índices y datos) para mejorar el rendimiento y la utilización de los recursos.
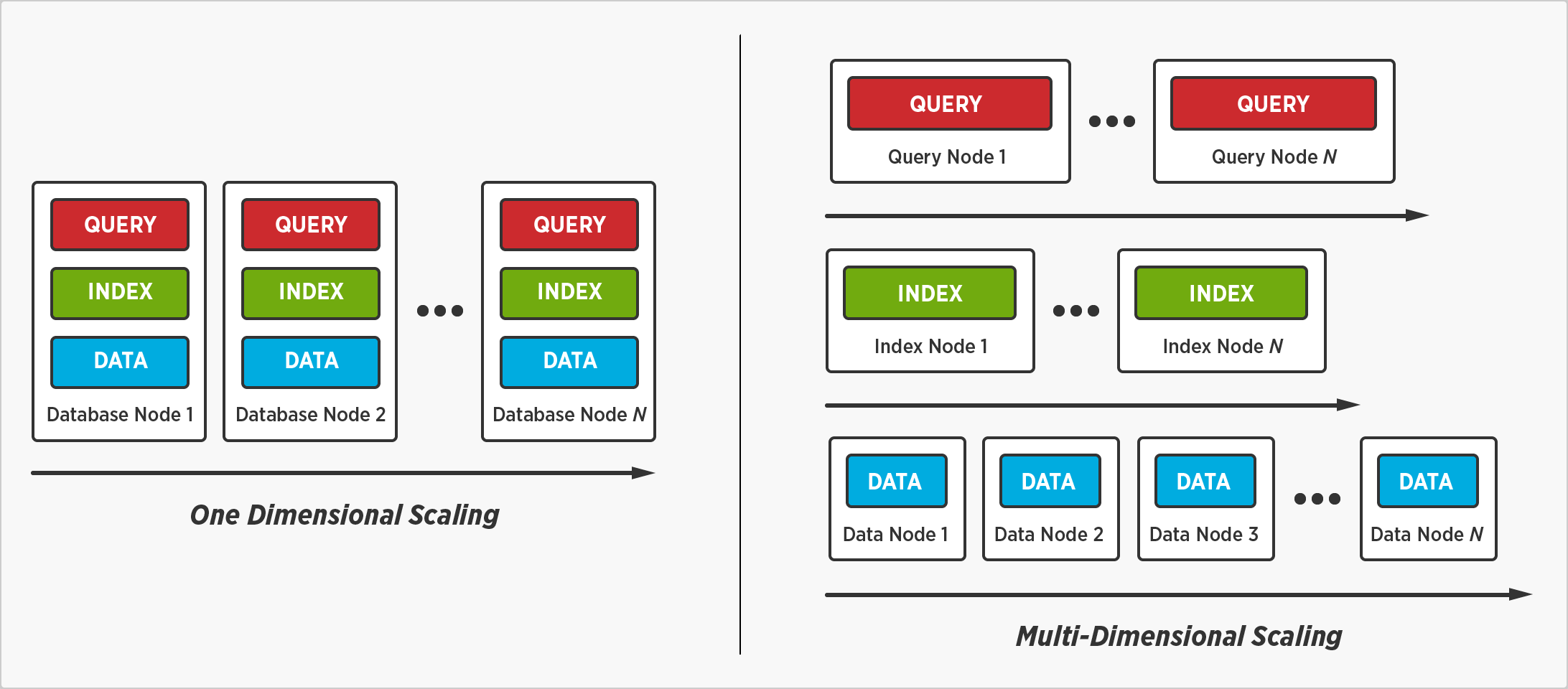
Distribuir datos, no ejecución de consultas e índices
El escalado multidimensional nos permite distribuir los datos sin distribuir la ejecución de las consultas y los índices. Una consulta se completará más rápido cuando no se ejecute en todos los nodos, y un índice se buscará más rápido cuando no se almacene en todos los nodos.
Optimizar el hardware para el servicio, no para la base de datos
El escalado multidimensional nos permite admitir varios perfiles de hardware ejecutando diferentes servicios en distintos nodos. Como resultado, cada nodo no requiere el procesador más rápido, la unidad de estado sólido más rápida y la mayor cantidad de memoria.
- Mientras que los nodos de consulta requieren un procesador más rápido, los de índice y datos no.
- Mientras que los nodos de índice requieren una unidad de estado sólido más rápida, los nodos de consulta no.
- Mientras que los nodos de datos requieren más memoria, los de consulta e índice no.
Eliminar la contención de recursos
El escalado multidimensional nos permite eliminar la contención de recursos ejecutando diferentes servicios en distintos nodos. Cuando las consultas se ejecutan en nodos separados, no hay contención de CPU entre consultas y lecturas o escrituras. Cuando los índices se almacenan en nodos distintos, no hay contención de E/S de disco entre índices y lecturas o escrituras.
El escalado multidimensional mejora el rendimiento:
- Almacenamiento de datos e índices en nodos separados: sin contención de IO en disco
- Almacenamiento de datos y ejecución de consultas en nodos separados: sin contención de CPU.
- Ejecutar una consulta sin distribuirla a todos los nodos: sin sobrecarga de red
- Almacenamiento de un índice sin distribuirlo a todos los nodos: sin sobrecarga de red
El escalado multidimensional mejora la utilización de los recursos:
- Configuración de nodos de servicio de consulta con procesadores rápidos, sin SSD y menos memoria
- Configuración de nodos de servicio de índices con unidades SSD rápidas y menos memoria.
- Configuración de nodos de servicio de datos con más memoria y un disco duro o SSD.
Conceptos
Servicios elásticos permiten el escalado independiente de los servicios de datos, índices y consultas. El servicio de datos puede escalarse sin escalar los servicios de consulta o índice.
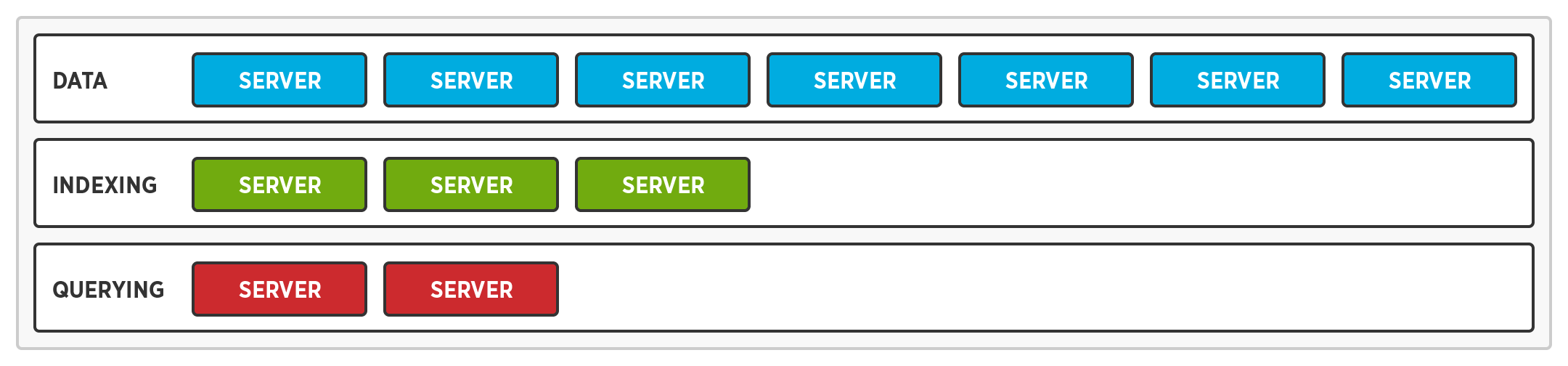
Optimización de los servicios permite optimizar el hardware de un nodo en función del servicio que esté ejecutando. Al fin y al cabo, los requisitos de hardware para los servicios de consulta, índice y datos son diferentes.
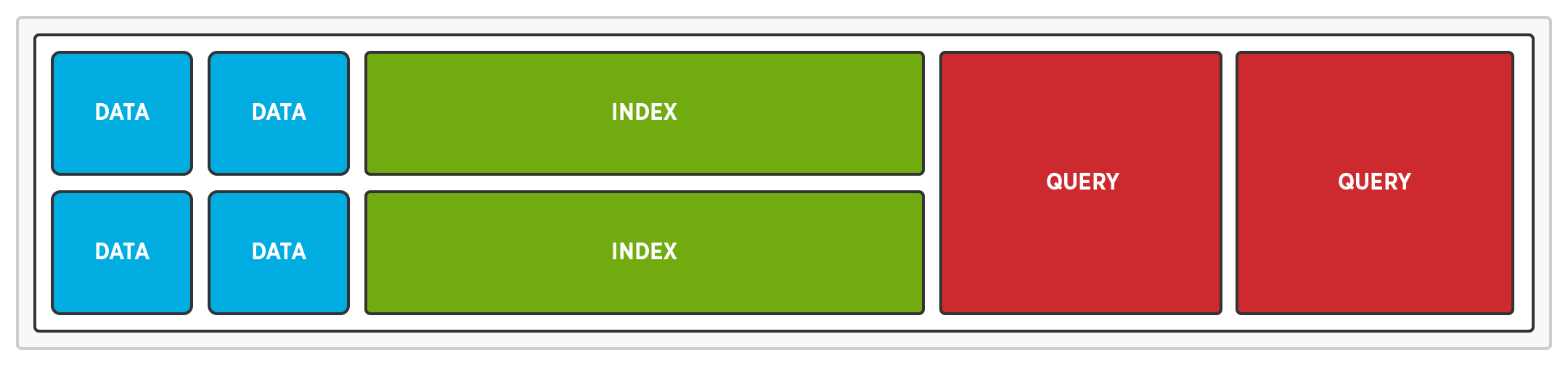
Aislamiento de servicios garantiza que los servicios de consulta, índice y datos no sufran contención de recursos. Aísla los servicios de consulta, índice y datos para evitar que las consultas y los índices ralenticen las lecturas y escrituras.

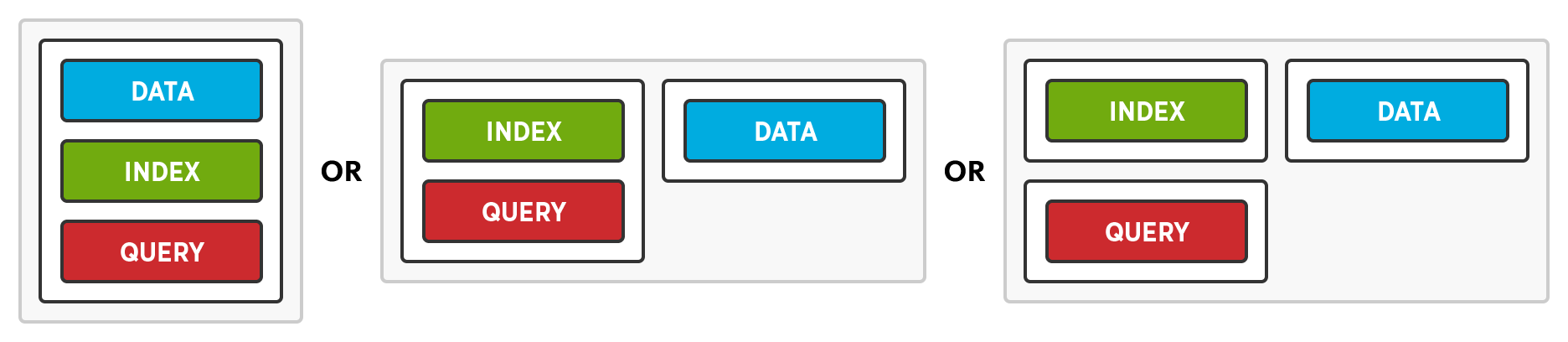
Despliegue flexible permite a los administradores decidir si aprovechan o no el Escalado Multidimensional. Cuando se añade un nodo, los administradores pueden habilitar todos los servicios, algunos de los servicios o solo uno de los servicios.
Más información sobre el escalado multidimensional y novedades de Couchbase Server 4.0 aquí.
Debatir sobre Noticias Hacker
¿Habéis pensado alguna vez en la localización de datos? Separación por una columna personalizada
como "user_id\", de esta manera todos los datos estarán en 1 nodo y
las consultas complejas serán más rápidas, ya que no se transferirán datos entre
nodos.
O incluso la fragmentación por un subconjunto de la clave primaria (como la fragmentación regex realizada por redislabs).
Gracias por la mención - Me alegro de que te guste la función de fragmentación regex, estamos muy orgullosos de ella :)
¿No limitaría eso las consultas a un único campo, la columna personalizada? Se podría dividir por ciudad del usuario y consultar a los usuarios por ciudad, pero ¿y si también se quiere consultar a los usuarios por edad? ¿Y si la consulta une usuarios y compras?
Si quieres que tu consulta llegue a un nodo/parcela específico tienes que incluir la cláusula "user_id\" y añadir otras cláusulas.
Si desea consultar por otro atributo (obtener todos los usuarios donde la edad), entonces usted va a golpear cada nodo.
El problema con tu método, es que almacenas el índice en un nodo separado (por lo que SIEMPRE tendrás tráfico entre nodos incluso para consultas básicas "select column from user where whatever_filter (column is not indexed))\".
En tu caso, cada consulta afectará a todos los nodos de índice, y por muy rápidos que sean, se desmoronarán al cabo de un tiempo, ya que cada nodo tendrá que responder a cada consulta, aunque todos los datos estén en memoria y cada servidor tenga una capacidad limitada de CPU.
La única manera de tener escalabilidad REAL (no se puede construir aplicaciones con sólo kv-access, se puede construir sólo algunas características) es ir por el camino de partición automática de rangos (como hbase, hypertable,).
Otra forma (más fácil de hacer, menos características) es hacer sharding por una columna personalizada.
Esa es la ventaja del MDS. No llegaremos a todos los nodos. Puedo crear un índice para la ciudad. Todo el índice se almacenará en uno de los nodos de índice. Un nodo de consulta enviará una solicitud a este nodo índice. Devolverá todos los identificadores de usuario que coincidan (ciudad=Chicago). El nodo de consulta obtendrá entonces esos usuarios (y sólo de los nodos que los contengan). No tiene que enviar una petición a cada nodo.
¿Y si el índice crece más de 1 nodo?
Creo que consideraríamos dividir un índice y almacenarlo en múltiples nodos de índice. Sin embargo, no puedo evitar preguntarme cuántos índices requerirán terabytes de espacio en disco, ya que se comprimirán con Snappy.
Suponga que quiere indexar cada objeto de su tabla (normalmente lo hace). Ahora, cada inserción/actualización/borrado tiene que ir a ese nodo índice.
La forma más frecuente es colocar datos+índice en el mismo nodo.
Más o menos, los índices se actualizarán de forma asíncrona por defecto. No ralentizarán las escrituras, independientemente de cuántos sean. Dicho esto, una consulta puede ser enviada con una opción para forzar una actualización del índice en primer lugar. Un par de los problemas con la co-localización de datos e índices son la sobrecarga de la red y las uniones. Es la forma más frecuente porque a) es fácil y b) otros proveedores han estado dispuestos a excluir las uniones. Como recordatorio, estamos hablando de índices secundarios, no del índice primario.