빅 데이터 아키텍처를 구축한다는 것은 NoSQL 또는 Hadoop 중 하나를 선택하는 것을 의미하지 않습니다. 그 대신 NoSQL과 Hadoop이 함께 작동하도록 만드는 것입니다. Hadoop은 배치 및 스트리밍 분석 워크로드를 위해 설계되었습니다. NoSQL 데이터베이스는 엔터프라이즈 웹, 모바일 및 IoT 운영 워크로드를 위해 설계되었습니다. NoSQL 데이터베이스의 운영 빅 데이터는 Hadoop을 위한 연료입니다.
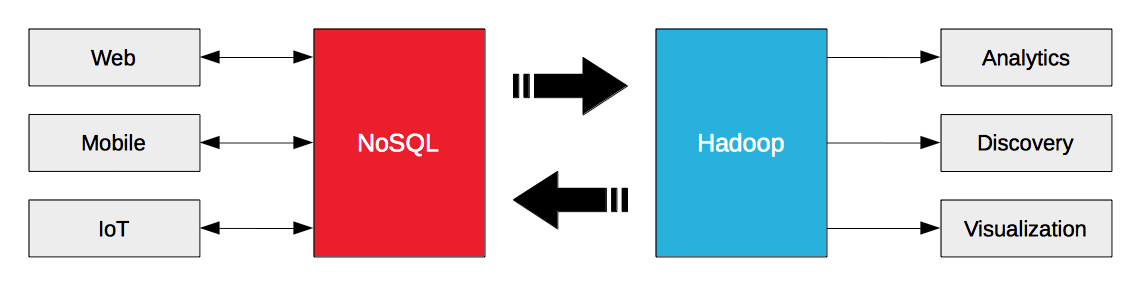
운영 빅데이터의 가치를 실현하기 위한 핵심은 NoSQL 데이터베이스와 Hadoop 간의 데이터 흐름을 간소화하는 것이며, 이것이 바로 오늘 Hortonworks와 Couchbase가 전략적 파트너십을 발표한 이유입니다. Couchbase Server 3.0은 내부 대상(예: 노드/클러스터)뿐만 아니라 외부 대상(예: Hadoop)으로도 데이터를 스트리밍하기 위해 데이터베이스 변경 프로토콜(DCP)을 도입했습니다. Hortonworks 데이터 플랫폼(HDP) 2.2에는 데이터 가져오기/내보내기를 위한 Sqoop뿐만 아니라 높은 처리량 메시징을 위한 Kafka와 스트림 처리를 위한 Storm이 포함되어 있습니다.
카우치베이스 서버는 외부 대상에 데이터를 스트리밍할 수 있습니다. HDP는 외부 소스에서 데이터를 수집하여 스트림으로 처리할 수 있습니다. 이러한 기능을 통해 기업은 다음을 내보낼 수 있습니다. 그리고 카우치베이스 서버에서 HDP로 또는 그 반대로 데이터를 스트리밍할 수 있습니다.
카우치베이스 서버 하둡 커넥터
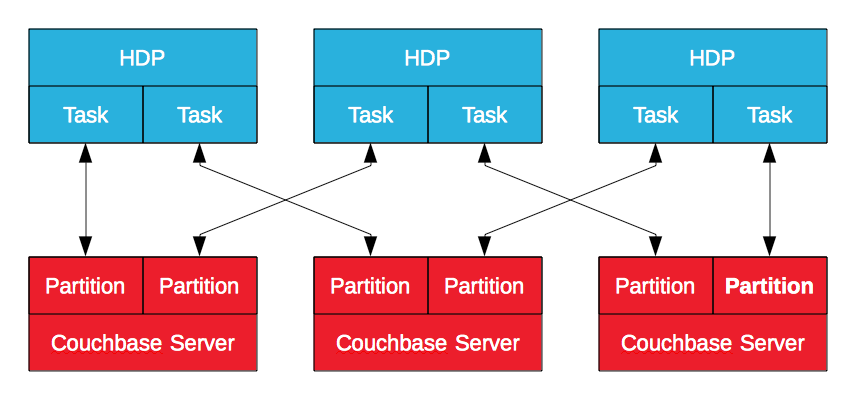
Hortonworks에서 인증한 Couchbase Server Hadoop 커넥터는 MapReduce를 활용하여 Couchbase Server에서 HDP로 또는 그 반대로 데이터를 내보냅니다. Couchbase Server의 데이터는 논리적 파티션에 저장되며, 노드는 그 하위 집합을 소유합니다. Apache Sqoop 하위 프로젝트를 기반으로 구축된 이 프로젝트는 HDP에서 MapReduce 작업을 생성하여 데이터를 가져오거나 Couchbase Server로 데이터를 내보냅니다. 이를 통해 Hadoop은 여러 작업으로 데이터를 가져오고 내보낼 수 있습니다, 병렬로를 사용하여 여러 Couchbase Server 노드에 연결할 수 있습니다. 일괄 처리 프로세스이지만 특히 운영 데이터를 보강하고 정제하는 것이 목표일 때 효과적입니다.
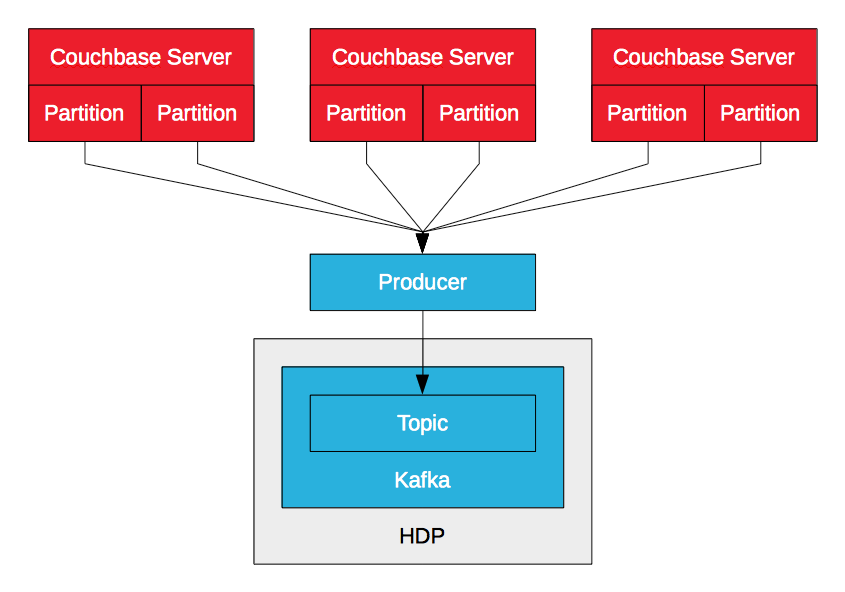
카우치베이스 서버 카프카 프로듀서
Couchbase Server Kafka 프로듀서는 DCP를 활용하여 Couchbase Server의 데이터 변이(삽입, 업데이트, 삭제)를 Kafka 토픽으로 스트리밍합니다. 프로듀서는 논리적 파티션당 하나씩 여러 노드에서 여러 스트림을 수신하여 병합합니다. 돌연변이를 수신하면 토픽으로 전송합니다. 이를 통해 처리량이 높고 지연 시간이 짧은 데이터를 Kafka를 통해 HDP로 수집할 수 있습니다. Sqoop을 사용하면 기업이 일괄 처리를 통해 Couchbase Server에서 데이터를 가져올 수 있는 반면, Kafka를 사용하면 스트림을 통해 데이터를 가져올 수 있습니다. 예를 들어, 데이터는 LinkedIn의 Camus를 사용하여 HDFS에 쓰거나 Storm 또는 Spark Streaming을 통해 실시간 처리를 위해 소비될 수 있습니다.
카우치베이스 서버 카프카를 오픈소스화한 PayPal 프로듀서 Couchbase Server 2.5용.
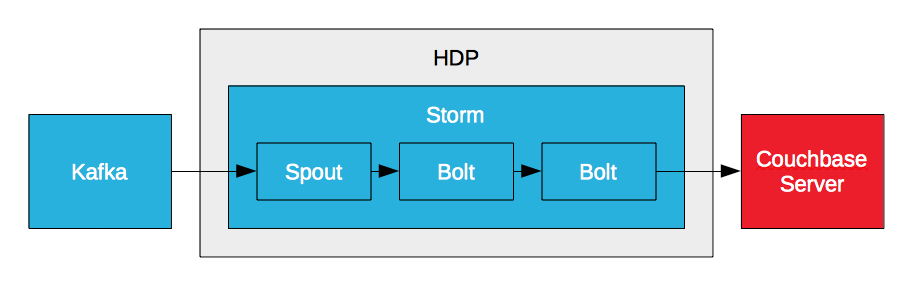
카우치베이스 서버 스톰 볼트
Storm은 데이터 스트림을 실시간으로 처리할 수는 있지만 데이터를 보존할 수 없고 데이터에 대한 액세스를 제공할 수 없습니다. 하지만 볼트를 통해 Couchbase Server에 데이터를 쓸 수는 있습니다. Storm은 높은 처리량과 짧은 지연 시간 요구 사항을 충족하기 위해 고성능 데이터베이스가 필요합니다. 이것이 바로 PayPal과 같은 기업이 Couchbase Server 볼트를 만드는 이유입니다. 이를 통해 데이터 스트림을 실시간으로 처리하고 처리된 데이터를 Couchbase Server에 기록할 수 있습니다. 실시간 분석의 핵심은 짧은 지연 시간입니다. 지연 시간이 짧은 입력, 이동 중인 데이터 분석, 지연 시간이 짧은 출력, 보고 및 시각화를 위한 결과 액세스가 바로 그것입니다.
카우치베이스 서버 스톰 볼트(예시 #1)
카우치베이스 서버 스톰 볼트(예시 #2)
실시간 빅 데이터
PayPal과 같은 기업들은 다음과 같은 데이터 흐름을 간소화하여 실시간 빅 데이터 솔루션을 만들기 위해 Kafka, Storm, Flume을 활용하고 있습니다. 카우치베이스 서버 및 HDP와 같은 Hadoop 배포를 지원합니다. 카우치베이스 서버에서 카프카, 스톰에서 HDFS로. Kafka에서 Storm에서 HDFS로, 그리고 Couchbase Server로. 여러분에게 달려 있습니다. HDP에는 Couchbase Server와의 데이터 흐름을 지원하는 데 필요한 모든 구성 요소가 포함되어 있습니다. 실시간 빅 데이터 아키텍처는 어떤 모습일까요?
스트라타+하둡 월드
카우치베이스는 오늘 LinkedIn과 함께 카우치베이스 서버 및 카프카에 대해 발표할 예정입니다. 링크드인의 카우치베이스에서 하둡으로: 빅데이터 파이프라인을 활성화하는 Kafka
리소스
카우치베이스 커넥트 2014에서 페이팔 프레젠테이션 발표
빅 데이터 센트럴