오늘날의 데이터 중심 세상에서는 데이터를 효율적으로 수집하고 준비하는 능력이 모든 애플리케이션의 성공에 매우 중요합니다. 챗봇, 추천 시스템 또는 모든 AI 기반 솔루션을 개발하든, 데이터의 품질과 구조가 프로젝트의 성패를 좌우할 수 있습니다. 이 문서에서는 다음을 위해 데이터를 준비하는 방법에 중점을 두고 정보 수집 및 스마트 청킹 프로세스를 살펴보는 여정을 안내합니다. 검색 증강 세대(RAG) 선택한 데이터베이스가 있는 모든 애플리케이션에서 사용할 수 있습니다.
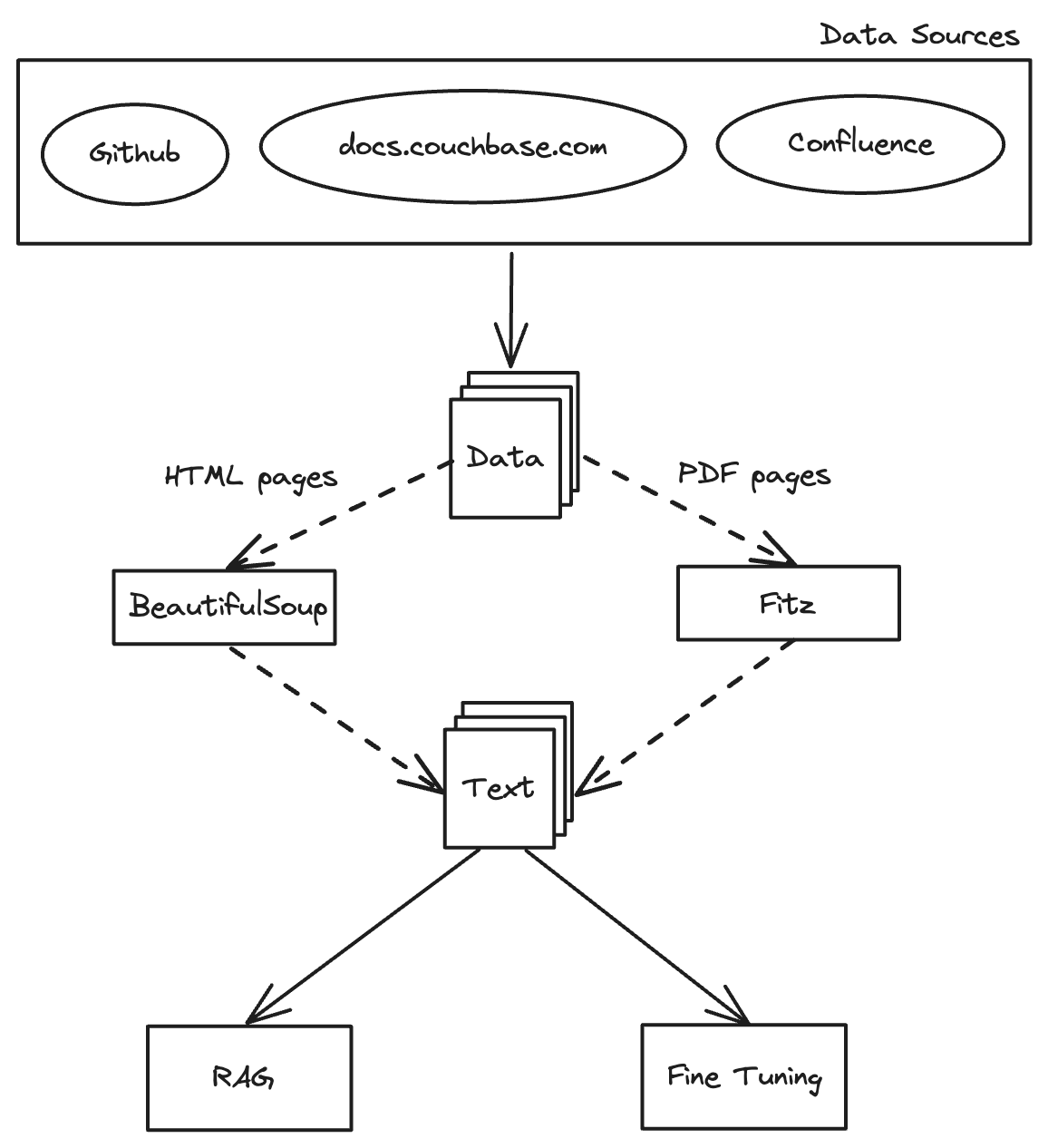
RAG용 문서 변환에 대한 높은 수준의 개요
데이터 수집: RAG의 기초
스크랩의 마법
소름 끼치는 거미가 아니라 인터넷의 거대한 도서관에서 부지런히 일하는 사서 거미를 상상해 보세요. 이 거미는 스크랩의 Spider 클래스의 입구(시작 URL)에서 시작하여 모든 방(웹 페이지)을 체계적으로 방문하면서 소중한 책(HTML 페이지)을 수집합니다. 다른 방으로 통하는 문(하이퍼링크)을 발견할 때마다 그 문을 열고 탐험을 계속하여 어느 방도 놓치지 않습니다. 모든 정보를 체계적이고 꼼꼼하게 수집하는 스크랩의 작동 방식입니다.
데이터 수집을 위한 스크랩 활용
스크랩 는 웹사이트에서 데이터를 추출하도록 설계된 Python 기반 프레임워크입니다. 사서 거미에게 초능력을 부여하는 것과 같습니다. 스크랩을 사용하면 웹 페이지를 탐색하고 원하는 정보를 정확하게 추출하는 웹 스파이더를 구축할 수 있습니다. 저희의 경우, 스크랩을 배포하여 Couchbase 문서 웹사이트를 크롤링하고 추가 처리 및 분석을 위해 HTML 페이지를 다운로드합니다.
스크랩 프로젝트 설정
거미가 여정을 시작하기 전에 스크랩 프로젝트를 설정해야 합니다. 방법은 다음과 같습니다:
- 스크랩 설치: 아직 스크랩을 설치하지 않았다면 pip를 사용하여 설치할 수 있습니다:
1pip 설치 스크랩
- 새 스크랩 프로젝트 만들기: 다음 명령어로 새 스크랩 프로젝트를 설정합니다:
1스크랩 프로젝트 시작 couchbase_docs
거미 제작하기
스크랩 프로젝트가 설정되었으므로 이제 Couchbase 문서 웹사이트를 크롤링하고 HTML 페이지를 다운로드할 스파이더를 만듭니다. 그 모습은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
에서 pathlib 가져오기 경로 가져오기 스크랩 클래스 카우치베이스스파이더(스크랩.Spider): 이름 = "couchbase" start_urls = ["https://docs.couchbase.com/home/index.html",] def parse(self, 응답): # 현재 페이지의 HTML 콘텐츠 다운로드 페이지 = 응답.URL.분할("/")[-1] 파일 이름 = f"{page}.html" 경로(파일 이름).쓰기_바이트(응답.body) self.로그(f"{파일 이름} 저장됨") # 링크 추출 및 팔로우 에 대한 href in 응답.css("UL A::ATTR(href)").getall(): 만약 href.끝(".html") 또는 "docs.couchbase.com" in href: 수익률 응답.팔로우(href, self.parse) |
스파이더 실행
스파이더를 실행하고 데이터 수집 프로세스를 시작하려면 스크랩 프로젝트 디렉토리에서 다음 명령을 실행합니다:
|
1 |
스크랩 크롤링 카우치베이스 |
이 명령은 스파이더를 시작하여 지정된 URL을 크롤링하고 HTML 콘텐츠를 저장하기 시작합니다. 스파이더는 각 페이지에서 링크를 추출하고 이를 재귀적으로 따라가며 포괄적인 데이터 수집을 보장합니다.
스크랩으로 데이터 수집을 자동화함으로써 Couchbase 문서 웹사이트의 모든 관련 HTML 콘텐츠를 효율적이고 체계적으로 검색하여 추가 처리 및 분석을 위한 탄탄한 기반을 마련할 수 있습니다.
텍스트 콘텐츠 추출하기: 원시 데이터 변환
Couchbase 문서 웹사이트에서 HTML 페이지를 수집한 후, 다음 중요한 단계는 텍스트 콘텐츠를 추출하는 것입니다. 이렇게 하면 원시 데이터가 분석 및 추가 처리에 사용할 수 있는 형식으로 변환됩니다. 또한 중요한 데이터가 포함된 PDF 파일이 있을 수 있으며, 이 파일도 추출할 것입니다. 여기서는 Python 스크립트를 사용하여 HTML 파일과 PDF를 파싱하고 텍스트 데이터를 추출하여 추가 처리를 위해 저장하는 방법에 대해 설명합니다.
HTML 페이지에서 텍스트 추출
HTML 페이지에서 텍스트 콘텐츠를 추출하기 위해 HTML 파일을 파싱하고 그 안에 포함된 텍스트 데이터를 검색하는 Python 스크립트를 사용합니다. <p> 태그를 사용합니다. 이 접근 방식은 HTML 마크업이나 구조적 요소를 제외한 각 페이지의 텍스트 본문을 캡처합니다.
텍스트 추출을 위한 파이썬 함수
아래는 HTML 페이지에서 텍스트 콘텐츠를 추출하여 텍스트 파일에 저장하는 방법을 보여주는 Python 함수입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
에서 bs4 가져오기 아름다운 수프 def get_data(html_content): 수프 = 아름다운 수프(html_content, "html.parser") title = str(수프).분할(' 만약 " | 카우치베이스 문서" in title: title = title[:(title.색인(" | 카우치베이스 문서"))].대체(" ", "_") else: title = title.대체(" ", "_") 데이터 = "" 라인 = 수프.find_all('p') 에 대한 라인 in 라인: 데이터 += " " + 라인.텍스트 반환 title, 데이터 |
어떻게 사용하나요?
사용하려면 get_data() 함수를 Python 스크립트나 애플리케이션에 통합하고 HTML 콘텐츠를 매개변수로 제공하세요. 이 함수는 추출된 텍스트 콘텐츠를 반환합니다.
|
1 2 3 4 |
html_content = '<html><head><title>Sample Page</title></head><body><p>다음은 예시 문단입니다.</p></body></html>' title, 텍스트 = get_data(html_content) 인쇄(title) # 출력: Sample_Page 인쇄(텍스트) # 출력: 샘플 문단입니다. |
PDF에서 텍스트 콘텐츠 추출
PDF에서 텍스트 콘텐츠를 추출하기 위해 PDF 파일을 읽고 데이터를 검색하는 Python 스크립트를 사용합니다. 이 프로세스를 통해 분석을 위해 모든 관련 텍스트 정보를 캡처할 수 있습니다.
텍스트 추출을 위한 파이썬 함수
아래는 PDF에서 텍스트 콘텐츠를 추출하는 방법을 보여주는 Python 함수입니다:
|
1 2 3 4 5 6 7 8 |
에서 PyPDF2 가져오기 PdfReader def PDF에서 텍스트 추출(PDF_파일): reader = PdfReader(PDF_파일) 텍스트 = '' 에 대한 페이지 in reader.페이지: 텍스트 += 페이지.추출_텍스트() 반환 텍스트 |
어떻게 사용하나요?
extract_text_from_pdf() 함수를 사용하려면 Python 스크립트 또는 애플리케이션에 이 함수를 통합하고 PDF 파일 경로를 매개변수로 제공하세요. 이 함수는 추출된 텍스트 콘텐츠를 반환합니다.
|
1 2 |
pdf_path = 'sample.pdf' 텍스트 = PDF에서 텍스트 추출(pdf_path) |
텍스트 콘텐츠를 추출하고 저장한 후 Couchbase 문서에서 데이터를 가져오는 프로세스를 완료했습니다.
청킹: 관리 가능한 데이터 만들기
긴 소설을 읽고 요약본을 만들고 싶다고 상상해 보세요. 책 전체를 한 번에 읽는 대신 장, 단락, 문장으로 나눠서 읽습니다. 이렇게 하면 각 부분을 쉽게 이해하고 처리할 수 있어 작업을 더 쉽게 관리할 수 있습니다. 마찬가지로 텍스트 처리에서 청킹은 큰 텍스트를 의미 있는 작은 단위로 나누는 데 도움이 됩니다. 텍스트를 관리하기 쉬운 청크로 구성하면 정보를 더 쉽게 처리, 검색 및 분석할 수 있습니다.
RAG를 위한 시맨틱 및 콘텐츠 청크
검색 증강 생성(RAG)의 경우 청킹이 특히 중요합니다. 관련 정보를 검색하고 해당 정보를 기반으로 응답을 생성하는 RAG 프로세스에 맞게 데이터를 최적화하기 위해 시맨틱 및 콘텐츠 청킹 방법을 모두 구현했습니다.
재귀 문자 텍스트 분할기

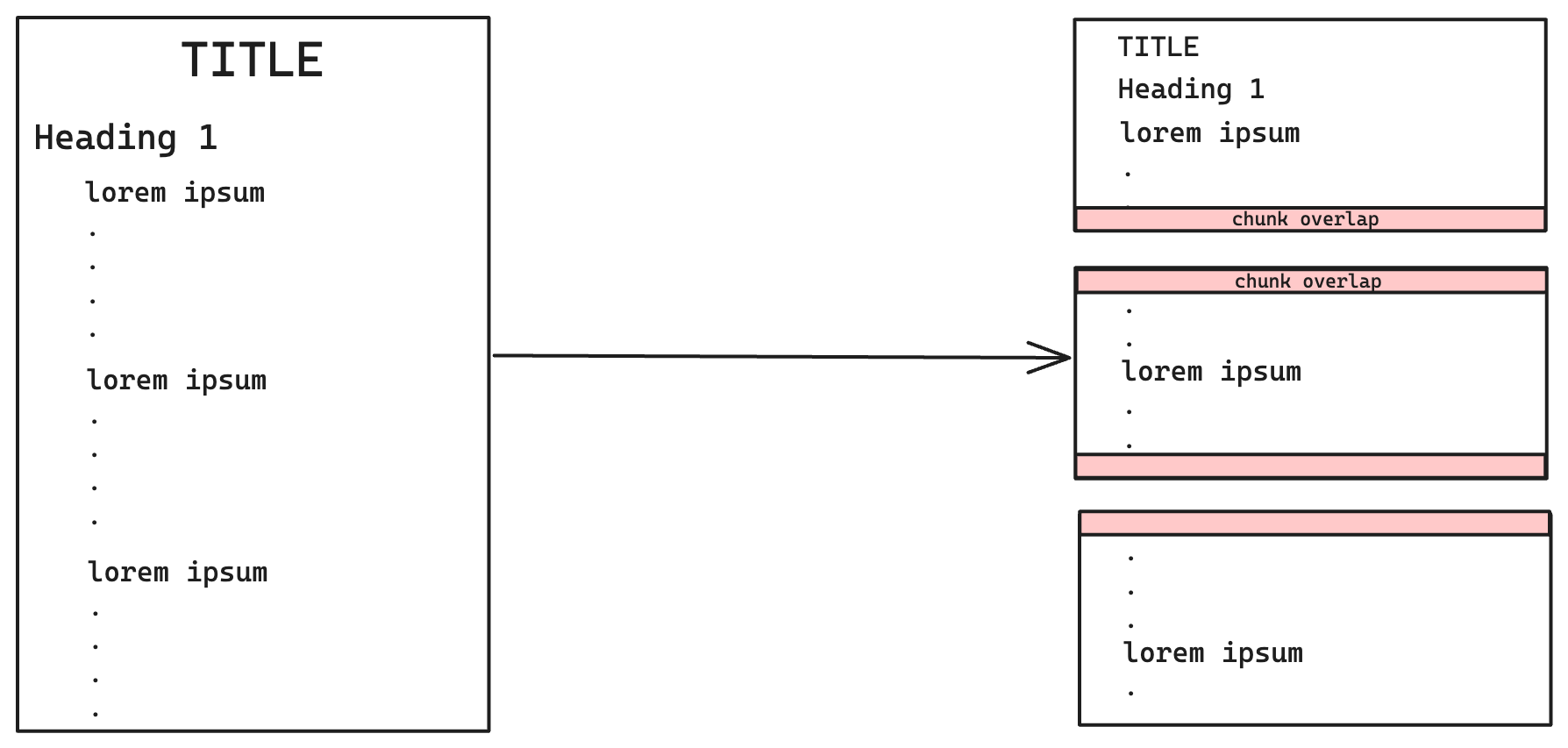
재귀적 문자 텍스트 분할기 의 청킹은 텍스트 문자 내에서 재귀 패턴을 사용하여 텍스트 조각을 더 작은 덩어리로 분해하는 것입니다. 이 기술은 다음과 같은 구분 기호를 활용합니다. \n\n (이중 줄 바꿈), \n (줄 바꿈), (공백) 및 "" (빈 문자열).
시맨틱 청킹


시맨틱 청킹은 의미론적 의미 또는 문맥에 따라 단어나 구를 그룹화하는 데 중점을 둔 텍스트 처리 기법입니다. 이 접근 방식은 텍스트의 기본 관계를 포착하는 의미 있는 청크를 생성하여 이해도를 높입니다. 텍스트 구조와 콘텐츠 구성에 대한 상세한 분석이 필요한 작업에 특히 유용합니다.
시맨틱 및 콘텐츠 청킹 구현
저희 프로젝트에서는 시맨틱 청킹과 콘텐츠 청킹 방법을 모두 구현했습니다. 시맨틱 청킹은 텍스트의 계층 구조를 보존하여 각 청크가 문맥 무결성을 유지하도록 보장합니다. 콘텐츠 청킹은 중복 청크를 제거하고 저장 및 처리 효율성을 최적화하기 위해 적용되었습니다.
Python 구현
다음은 시맨틱 및 콘텐츠 청크의 Python 구현입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
가져오기 hashlib 에서 랭체인.text_splitter 가져오기 리커시브 문자 텍스트 스플리터 모든 파일에 고유한 청크 해시 값을 저장하도록 설정된 # 글로벌 글로벌_유니크_해시 = set() def 해시_텍스트(텍스트): # SHA-256을 사용하여 텍스트의 해시값을 생성합니다. 해시객체 = hashlib.sha256(텍스트.encode()) 반환 해시객체.헥스다이제스트() def 청크_텍스트(텍스트, title, 청크 크기=2000, 오버랩=50, 길이_함수=len, debug_mode=0): 글로벌 글로벌_유니크_해시 청크 = 리커시브 문자 텍스트 스플리터( 청크 크기=청크 크기, 청크_오버랩=오버랩, 길이_함수=길이_함수 ).create_documents([텍스트]) 만약 debug_mode: 에 대한 idx, 청크 in 열거(청크): 인쇄(f"청크 {idx+1}: {청크}\n") 인쇄('\n') # 중복 제거 메커니즘 고유_청크 = [] 에 대한 청크 in 청크: 청크_해시 = 해시_텍스트(청크.페이지_콘텐츠) 만약 청크_해시 not in 글로벌_유니크_해시: 고유_청크.추가(청크) 글로벌_유니크_해시.추가(청크_해시) 에 대한 문장 in 고유_청크: 문장.페이지_콘텐츠 = title + " " + 문장.페이지_콘텐츠 반환 고유_청크 |
이렇게 최적화된 청크는 효율적인 검색을 위해 Couchbase 클러스터에 임베드되고 저장되어 RAG 프로세스와의 원활한 통합을 보장합니다.
시맨틱 및 콘텐츠 청킹 기술을 모두 사용하여 텍스트 데이터를 효과적으로 구조화하고 최적화하여 RAG 프로세스 및 Couchbase 클러스터의 저장소에 저장했습니다. 다음 단계는 방금 생성한 청크를 임베드하는 것입니다.
청크 임베딩하기: 데이터의 은하계 매핑
각 텍스트 덩어리를 광활한 은하계의 별이라고 상상해 보세요. 이러한 청크를 삽입함으로써 우리는 각 별의 특징과 다른 별과의 관계를 기반으로 은하계에서 정확한 위치를 할당합니다. 이러한 공간 매핑을 통해 은하계를 보다 효과적으로 탐색하고, 연결 고리를 찾고, 더 넓은 정보 세계를 이해할 수 있습니다.
RAG용 텍스트 청크 임베딩
텍스트 청크를 임베딩하는 것은 검색 증강 생성(RAG) 프로세스에서 중요한 단계입니다. 여기에는 텍스트를 숫자 벡터로 변환하여 각 청크의 의미론적 의미와 문맥을 포착함으로써 머신 러닝 모델이 더 쉽게 분석하고 응답을 생성할 수 있도록 하는 작업이 포함됩니다.
BAAI 모델 BGE-M3 활용하기
청크를 삽입하기 위해서는 BAAI 모델 BGE-M3. 이 모델은 텍스트를 고차원 벡터 공간에 삽입하여 각 청크의 의미론적 의미와 컨텍스트를 포착할 수 있습니다.
임베딩 기능
임베딩 기능은 이전 단계에서 생성된 청크를 가져와 BAAI 모델 BGE-M3을 사용해 각 청크를 1024차원 벡터 공간에 임베딩합니다. 이 과정을 통해 각 청크의 표현이 향상되어 보다 정확하고 맥락이 풍부한 분석이 가능해집니다.
임베딩용 Python 스크립트
다음은 BAAI 모델 BGE-M3을 사용하여 텍스트 청크를 임베드하는 방법을 보여주는 Python 스크립트입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
가져오기 json 가져오기 numpy as np 에서 json 가져오기 JSONEncoder 에서 baai_model 가져오기 BGEM3FlagModel embed_model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) 클래스 넘피 인코더(JSONEncoder): def 기본값(self, 객체): 만약 인스턴스(객체, np.ndarray): 반환 객체.토리스트() 반환 JSONEncoder.기본값(self, 객체) def embed(청크): 임베디드_청크 = [] 에 대한 문장 in 청크: emb = embed_model.encode(str(문장.페이지_콘텐츠), 배치 크기=12, max_length=600)['dense_vecs'] 임베딩 = np.배열(emb) np.set_print옵션(suppress=True) json_dump = json.덤프(임베딩, cls=넘피 인코더) embedded_chunk = { "데이터": str(문장.페이지_콘텐츠), "벡터_데이터": json.로드(json_dump) } 임베디드_청크.추가(embedded_chunk) 반환 임베디드_청크 |
어떻게 사용하나요?
embed() 함수를 사용하려면 Python 스크립트 또는 애플리케이션에 이 함수를 통합하고 이전 단계에서 생성된 청크를 입력으로 제공합니다. 이 함수는 임베드된 청크의 목록을 반환합니다.
|
1 2 3 4 5 6 7 |
청크 = [ # 청크는 이전에 생성된 텍스트 청크의 목록이라고 가정합니다. {"page_content": "이것이 첫 번째 텍스트 덩어리입니다."}, {"page_content": "이것은 두 번째 텍스트 덩어리입니다."} ] 임베디드_청크 = embed(청크) |
이렇게 최적화된 청크는 이제 고차원 벡터 공간에 임베드되어 저장 및 검색이 가능하며, 리소스의 효율적인 활용과 RAG 프로세스와의 원활한 통합을 보장합니다. 텍스트 청크를 임베드함으로써 원시 텍스트를 머신러닝 모델이 효율적으로 처리하고 분석할 수 있는 형식으로 변환하여 RAG 시스템에서 보다 정확하고 맥락에 맞는 응답을 가능하게 합니다.
임베디드 청크 저장하기: 효율적인 검색 보장
텍스트 청크가 임베드되면 다음 단계는 이러한 벡터를 데이터베이스에 저장하는 것입니다. 이렇게 임베드된 청크는 벡터 데이터베이스나 벡터 검색을 지원하는 기존 데이터베이스(예: Couchbase, Elasticsearch 또는 Pinecone)에 푸시하여 검색 증강 세대(RAG) 애플리케이션에서 효율적으로 검색할 수 있도록 할 수 있습니다.
벡터 데이터베이스
벡터 데이터베이스는 고차원 벡터를 효율적으로 처리하고 검색할 수 있도록 특별히 설계되었습니다. 벡터 데이터베이스에 포함된 청크를 저장함으로써 고급 검색 기능을 활용하여 쿼리의 문맥과 의미론적 의미에 따라 가장 관련성이 높은 정보를 신속하게 검색할 수 있습니다.
RAG 애플리케이션과 통합
데이터가 준비되고 저장되었으므로 이제 RAG 애플리케이션에서 사용할 준비가 되었습니다. 내장된 벡터를 통해 이러한 애플리케이션은 상황에 맞는 정보를 검색하고 보다 정확하고 의미 있는 응답을 생성하여 전반적인 사용자 경험을 향상시킬 수 있습니다.
결론
이 가이드에 따라 검색 증강 세대를 위한 데이터를 성공적으로 준비했습니다. 스크랩을 사용한 데이터 수집, HTML과 PDF에서 텍스트 콘텐츠 추출, 청킹 기법, BAAI 모델 BGE-M3을 사용한 텍스트 청크 임베딩을 다루었습니다. 이러한 단계를 통해 데이터를 정리하고 최적화하여 RAG 애플리케이션에서 사용할 수 있도록 준비할 수 있습니다.
이러한 기술적이고 흥미로운 콘텐츠가 더 궁금하다면 다른 벡터 검색 관련 블로그 를 확인하시고 이 시리즈의 다음 편을 기대해 주세요.