"퍼지 매칭이란 무엇인가요?"라는 질문을 스스로에게 던져본 적이 있나요? 퍼지 매칭을 사용하면 대상 항목과 정확히 일치하지 않는 항목을 식별할 수 있습니다. 이는 많은 검색 엔진 프레임워크의 초석이며, 검색어에 오타가 있거나 시제가 다른 경우에도 관련 검색 결과를 얻을 수 있는 주된 이유 중 하나입니다.
예상할 수 있듯이 텍스트에 사용할 수 있는 퍼지 검색 알고리즘은 많지만 사실상 모든 검색 엔진 프레임워크( bleve) 퍼지 문자열 매칭에는 주로 레벤슈타인 거리를 사용합니다:
레벤슈타인 거리
다른 이름으로도 알려져 있습니다. 거리 편집는 소스 문자열을 대상 문자열로 변환하는 데 필요한 변환(삭제, 삽입 또는 치환) 횟수입니다. 퍼지 검색의 예로, 대상 용어가 "book"이고 소스가 "back"인 경우 첫 번째 "o"를 "a"로, 두 번째 "o"를 "c"로 변경하면 레벤슈타인 거리가 2가 됩니다. 편집 거리는 구현하기가 매우 쉬우며 코드 인터뷰 중 인기 있는 과제입니다(여기에서 JavaScript, Kotlin, Java 등으로 구현된 레벤슈타인을 확인할 수 있습니다.).
또한 일부 프레임워크는 다메라우-레벤슈타인 거리도 지원합니다:
다메라우-레벤슈타인 거리
레벤슈타인 거리의 확장 기능으로, 한 번의 추가 작업이 가능합니다: 전치 두 개의 인접한 문자로 구성됩니다:
Ex: TSAR에서 STAR로
다메라우-레벤슈타인 거리 = = 1 (S와 T 위치 전환은 한 번만 작동하면 됩니다)
레벤슈타인 거리 = 2 (S를 T로, T를 S로 바꾸기)
퍼지 매칭 및 관련성
퍼지 매칭에는 한 가지 큰 부작용이 있는데, 바로 연관성을 엉망으로 만든다는 것입니다. 다메라우-레벤슈타인은 일반적인 사용자의 철자 오류를 대부분 고려하는 퍼지 매칭 알고리즘이지만, 다음과 같은 경우도 상당수 포함할 수 있습니다. 오탐를 사용하는 경우, 특히 단어당 평균 5글자에 불과와 같은 영어를 사용합니다. 그렇기 때문에 대부분의 검색 엔진 프레임워크는 레벤슈타인 거리를 고수하는 것을 선호합니다. 실제 퍼지 매칭의 예를 살펴봅시다:
먼저 이 영화 카탈로그 데이터 세트. 전체 텍스트 검색을 해보고 싶으시다면 적극 추천합니다. 그런 다음 "책"를 제목에 추가합니다. 간단한 코드는 다음과 같습니다:
|
1 2 3 4 5 6 |
문자열 인덱스 이름 = "movies_index"; 매치 쿼리 쿼리 = 검색 쿼리.일치("book").필드("title"); 검색 쿼리 결과 결과 = 영화 저장소.getCouchbaseOperations().카우치베이스 버킷 가져오기().쿼리( new 검색 쿼리(인덱스 이름, 쿼리).하이라이트().limit(6)); printResults(영화); |
위의 코드는 다음과 같은 결과를 가져옵니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) 그리고 예약 도둑 점수: 4.826942606027416 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 도둑] ----------------------------- 2) 그리고 예약 의 Eli 점수: 4.826942606027416 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 Eli] ----------------------------- 3) 그리고 예약 의 생활 점수: 4.826942606027416 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 생활] ----------------------------- 4) 블랙 예약 점수: 4.826942606027416 히트 위치: 필드:title 용어:책 조각:[블랙 <mark>예약</mark>] ----------------------------- 5) 그리고 정글 예약 점수: 4.826942606027416 히트 위치: 필드:title 용어:책 조각:[그리고 정글 <mark>예약</mark>] ----------------------------- 6) 그리고 정글 예약 2 점수: 3.9411821308689627 히트 위치: 필드:title 용어:책 조각:[그리고 정글 <mark>예약</mark> 2] ----------------------------- |
기본적으로 결과는 대소문자를 구분하지 않지만, 다른 분석기를 사용하여 새 인덱스를 생성하면 이 동작을 쉽게 변경할 수 있습니다.
이제 퍼지를 1(레벤슈타인 거리 1)로 설정하여 쿼리에 퍼지 매칭 기능을 추가해 보겠습니다. 즉, "책" 및 "보기'는 동일한 관련성을 갖습니다.
|
1 2 3 4 5 6 |
문자열 인덱스 이름 = "movies_index"; 매치 쿼리 쿼리 = 검색 쿼리.일치("book").필드("title").흐릿함(1); 검색 쿼리 결과 결과 = 영화 저장소.getCouchbaseOperations().카우치베이스 버킷 가져오기().쿼리( new 검색 쿼리(인덱스 이름, 쿼리).하이라이트().limit(6)); printResults(영화); |
다음은 흐릿한 검색 결과입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Hook 점수: 1.1012248063242538 히트 위치: 필드:title 용어:hook 조각:[<mark>Hook</mark>] ----------------------------- 2) 여기 온다 의 Boom 점수: 0.7786835148361213 히트 위치: 필드:title 용어:붐 조각:[여기 온다 의 <mark>Boom</mark>] ----------------------------- 3) 보기 Who's Talking Too 점수: 0.7047266634351538 히트 위치: field:title 용어:보기 조각:[보기 누구's 말하기 Too] ----------------------------- 4) 보기 Who의 이야기 점수: 0.7047266634351538 히트 위치: field:title 용어:보기 조각:[보기 누구's 말하기] ----------------------------- 5) 그리고 예약 도둑 점수: 0.5228811753737184 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 도둑] ----------------------------- 6) 그리고 예약 의 Eli 점수: 0.5228811753737184 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 Eli] ----------------------------- |
이제 영화 "Hook"를 검색할 때 사용자가 기대하는 것과는 다른 첫 번째 검색 결과가 표시될 수 있습니다.예약".
퍼지 조회 중 오탐을 최소화하는 방법
이상적인 세상에서는 사용자가 무언가를 검색하는 동안 오타가 발생하지 않을 것입니다. 하지만 현실은 그렇지 않으며, 사용자에게 쾌적한 경험을 제공하려면 최소 1의 편집 거리를 처리해야 합니다. 따라서 진짜 문제는 어떻게 하면 관련성 손실을 최소화하면서 퍼지 문자열 일치를 만들 수 있는가 하는 것입니다.
대부분의 검색 엔진 프레임워크의 한 가지 특징을 활용할 수 있습니다: 일반적으로 편집 거리가 더 짧은 일치 항목이 더 높은 점수를 받습니다. 이 특성을 통해 퍼지 수준이 서로 다른 두 쿼리를 하나로 결합할 수 있습니다:
|
1 2 3 4 5 6 7 8 |
문자열 인덱스 이름 = "movies_index"; 문자열 단어 = "예약"; 매치 쿼리 titleFuzzy = 검색 쿼리.일치(단어).흐릿함(1).필드("title"); 매치 쿼리 titleSimple = 검색 쿼리.일치(단어).필드("title"); 분리 쿼리 ftsQuery = 검색 쿼리.분리(titleSimple, titleFuzzy); 검색 쿼리 결과 결과 = 영화 저장소.getCouchbaseOperations().카우치베이스 버킷 가져오기().쿼리( new 검색 쿼리(인덱스 이름, ftsQuery).하이라이트().limit(20)); printResults(결과); |
위의 퍼지 쿼리 결과는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
1) 그리고 예약 도둑 점수: 2.398890092610849 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 도둑] ----------------------------- 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 도둑] ----------------------------- 2) 그리고 예약 의 Eli 점수: 2.398890092610849 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 Eli] ----------------------------- 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 Eli] ----------------------------- 3) 그리고 예약 의 생활 점수: 2.398890092610849 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 생활] ----------------------------- 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 생활] ----------------------------- 4) 블랙 예약 점수: 2.398890092610849 히트 위치: 필드:title 용어:책 조각:[블랙 <mark>예약</mark>] ----------------------------- 필드:title 용어:책 조각:[블랙 <mark>예약</mark>] ----------------------------- 5) 그리고 정글 예약 점수: 2.398890092610849 히트 위치: 필드:title 용어:책 조각:[그리고 정글 <mark>예약</mark>] ----------------------------- 필드:title 용어:책 조각:[그리고 정글 <mark>예약</mark>] ----------------------------- 6) 그리고 정글 예약 2 점수: 1.958685557004688 히트 위치: 필드:title 용어:책 조각:[그리고 정글 <mark>예약</mark> 2] ----------------------------- 필드:title 용어:책 조각:[그리고 정글 <mark>예약</mark> 2] ----------------------------- 7) 국가 보물: 예약 의 비밀 점수: 1.6962714808368062 히트 위치: 필드:title 용어:책 조각:[국가 보물: <mark>예약</mark> 의 비밀] ----------------------------- 필드:title 용어:책 조각:[국가 보물: <mark>예약</mark> 의 비밀] ----------------------------- 8) 미국 Pie 선물: 그리고 예약 의 사랑 점수: 1.517191317611584 히트 위치: 필드:title 용어:책 조각:[미국 Pie 선물: 그리고 <mark>예약</mark> 의 사랑] ----------------------------- 필드:title 용어:책 조각:[미국 Pie 선물: 그리고 <mark>예약</mark> 의 사랑] ----------------------------- 9) Hook 점수: 0.5052232518679681 히트 위치: 필드:title 용어:hook 조각:[<mark>Hook</mark>] ----------------------------- 10) 여기 온다 의 Boom 점수: 0.357246781294941 히트 위치: 필드:title 용어:붐 조각:[여기 온다 의 <mark>Boom</mark>] ----------------------------- 11) 보기 Who's Talking Too 점수: 0.32331663301992025 히트 위치: field:title 용어:보기 조각:[보기 누구's 말하기 Too] ----------------------------- 12) 보기 Who의 이야기 점수: 0.32331663301992025 히트 위치: field:title 용어:보기 조각:[보기 누구's 말하기] ----------------------------- |
보시다시피, 이 결과는 사용자가 기대하는 것과 훨씬 더 가깝습니다. 현재 DisjunctionQuery라는 클래스를 사용하고 있으며, 분절은 "또는" 연산자를 사용합니다.
퍼지 매칭 알고리즘의 부작용을 줄이기 위해 또 어떤 점을 개선할 수 있을까요? 문제를 다시 분석하여 추가 개선이 필요한지 알아봅시다:
퍼지 조회가 예상치 못한 결과를 가져올 수 있다는 것을 이미 알고 있습니다(예: Book -> Look, Hook). 그러나 단일 용어 검색은 사용자가 정확히 무엇을 하려는 것인지에 대한 힌트를 거의 제공하지 않기 때문에 일반적으로 끔찍한 쿼리입니다.
가장 고도로 발달된 퍼지 검색 알고리즘을 사용하고 있는 구글조차도 ""를 검색하면 내가 무엇을 찾고 있는지 정확히 알지 못합니다.테이블":
그렇다면 검색 쿼리에서 키워드의 평균 길이는 얼마일까요? 이 질문에 답하기 위해 다음 그래프를 보여드리겠습니다. 랜드 피쉬킨의 2016년 프레젠테이션. (그는 SEO 업계에서 가장 유명한 구루 중 한 명입니다.)
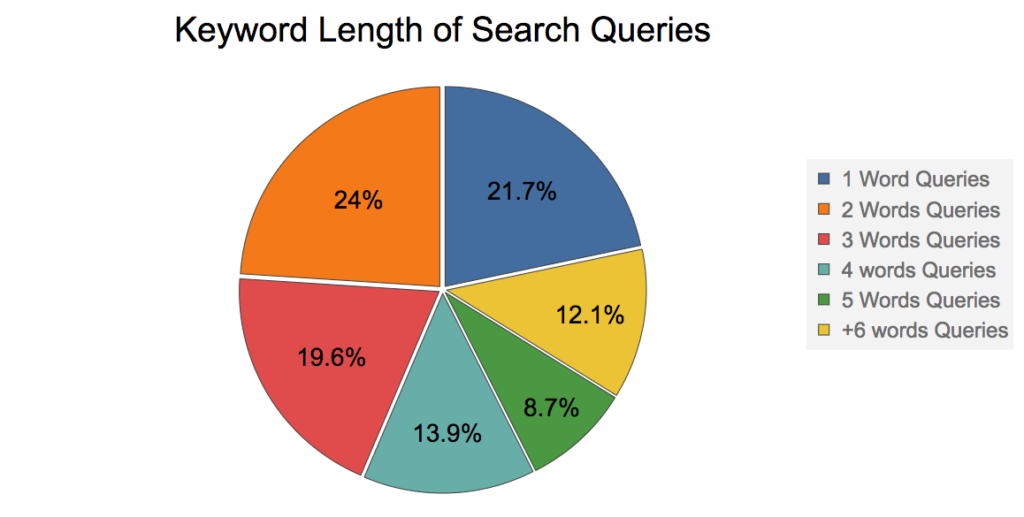
위의 그래프에 따르면 ~80% 검색어 중 키워드가 2개 이상인 경우, 퍼지 1을 사용하여 영화 '블랙북'을 검색해 보겠습니다:
|
1 2 3 4 5 6 |
문자열 인덱스 이름 = "movies_index"; 매치 쿼리 쿼리 = 검색 쿼리.일치("블랙북").필드("title").흐릿함(1); 검색 쿼리 결과 결과 = 영화 저장소.getCouchbaseOperations().카우치베이스 버킷 가져오기().쿼리( new 검색 쿼리(인덱스 이름, 쿼리).하이라이트().limit(12)); printResults(영화); |
결과:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
1) 블랙 예약 점수: 0.6946442424065404 히트 위치: 필드:title 용어:책 조각:[<mark>블랙</mark> <mark>예약</mark>] ----------------------------- 필드:title 용어:검은색 조각:[<mark>블랙</mark> <mark>예약</mark>] ----------------------------- 2) Hook 점수: 0.40139742528039857 히트 위치: 필드:title 용어:hook 조각:[<mark>Hook</mark>] ----------------------------- 3) 공격 의 블록 점수: 0.2838308365090324 히트 위치: 필드:title 용어:블록 조각:[공격 의 <mark>블록</mark>] ----------------------------- 4) 여기 온다 의 Boom 점수: 0.2838308365090324 히트 위치: 필드:title 용어:붐 조각:[여기 온다 의 <mark>Boom</mark>] ----------------------------- 5) 보기 Who's Talking Too 점수: 0.25687349813115684 히트 위치: field:title 용어:보기 조각:[보기 누구's 말하기 Too] ----------------------------- 6) 보기 Who의 이야기 점수: 0.25687349813115684 히트 위치: field:title 용어:보기 조각:[보기 누구's 말하기] ----------------------------- 7) Grosse Pointe 공백 점수: 0.2317469073782136 히트 위치: 필드:title 용어:빈 조각:[Grosse Pointe <mark>공백</mark>] ----------------------------- 8) 그리고 예약 도둑 점수: 0.19059065534780495 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 도둑] ----------------------------- 9) 그리고 예약 의 Eli 점수: 0.19059065534780495 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 Eli] ----------------------------- 10) 그리고 예약 의 생활 점수: 0.19059065534780495 히트 위치: 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 생활] ----------------------------- 11) 그리고 정글 예약 점수: 0.19059065534780495 히트 위치: 필드:title 용어:책 조각:[그리고 정글 <mark>예약</mark>] ----------------------------- 12) 뒤로 에 의 미래 점수: 0.17061000968368 히트 위치: 필드:title 용어:뒤로 조각:[<mark>뒤로</mark> 에 의 미래] ----------------------------- |
나쁘지 않네요. 검색하고자 하는 영화가 첫 번째 결과로 나왔습니다. 그러나 분리 쿼리를 사용하면 더 나은 결과를 얻을 수 있습니다.
하지만 키워드 수가 증가함에 따라 퍼지 매칭의 부작용이 약간 감소하는 새로운 좋은 속성이 생긴 것 같습니다. "블랙북" 흐릿하게 1 를 사용해도 백 룩이나 부족 요리와 같은 결과를 가져올 수 있지만(일부 조합은 편집 거리 1과 함께 사용) 실제 영화 제목이 될 가능성은 낮습니다.
" 검색예약 엘리'를 퍼지 2로 입력해도 여전히 세 번째 결과로 표시됩니다:
|
1 2 3 4 5 6 |
문자열 인덱스 이름 = "movies_index"; 매치 쿼리 쿼리 = 검색 쿼리.일치("예약 엘리").필드("title").흐릿함(2); 검색 쿼리 결과 결과 = 영화 저장소.getCouchbaseOperations().카우치베이스 버킷 가져오기().쿼리( new 검색 쿼리(인덱스 이름, 쿼리).하이라이트().limit(12)); printResults(영화); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Ed 목재 점수: 0.030723793900031805 히트 위치: 필드:title 용어:나무 조각:[<mark>Ed</mark> <mark>목재</mark>] ----------------------------- 필드:title 용어:ed 조각:[<mark>Ed</mark> <mark>목재</mark>] ----------------------------- 2) 남자 의 Tai Chi 점수: 0.0271042761982626 히트 위치: 필드:title 용어:chi 조각:[남자 의 <mark>Tai</mark> <mark>Chi</mark>] ----------------------------- 필드:title 용어:tai 조각:[남자 의 <mark>Tai</mark> <mark>Chi</mark>] ----------------------------- 3) 그리고 예약 의 Eli 점수: 0.02608335441670756 히트 위치: 필드:title 용어:eli 조각:[그리고 <mark>예약</mark> 의 <mark>Eli</mark>] ----------------------------- 필드:title 용어:책 조각:[그리고 <mark>예약</mark> 의 <mark>Eli</mark>] ----------------------------- 4) 그리고 Good 거짓말 점수: 0.02439822770591834 히트 위치: 필드:title 용어:거짓말 조각:[그리고 <mark>Good</mark> <mark>거짓말</mark>] ----------------------------- 필드:title 용어:좋은 조각:[그리고 <mark>Good</mark> <mark>거짓말</mark>] ----------------------------- |
하지만 평균 영어 단어의 길이가 5글자이므로, 저는 NOT 예를 들어 '슈워제네거'와 같이 철자가 틀리기 쉬운 긴 단어를 검색하는 경우가 아니라면(적어도 독일인이 아닌 사람이나 오스트리아인이 아닌 경우) 2보다 큰 편집 거리를 사용할 것을 권장합니다.
결론
이 문서에서는 퍼지 매칭과 그 주요 부작용인 관련성 문제를 해결하면서 퍼지 매칭을 극복하는 방법에 대해 설명했습니다. 퍼지 매칭은 관련성 높고 사용자 친화적인 검색을 구현할 때 활용해야 하는 많은 기능 중 하나에 불과하다는 점을 명심하세요. 이 시리즈에서 그 중 몇 가지에 대해 알아보겠습니다: N-Gram, 스톱워드, 스티밍, 싱글, 엘리젼. 기타 등등.
그동안 궁금한 점이 있으시면 다음 주소로 트윗해 주세요. @deniswsrosa.
인덱스에서 반환된 점수는 일치율과 어떤 관련이 있나요? 예를 들어, 결과의 연관성 점수가 50%를 초과하는 쿼리를 어떻게 구성할 수 있을까요?
문서가 어떻게 점수가 매겨지는지 더 자세히 알고 싶다면 루센과 블레브 모두 "설명" 메서드가 있습니다. 카우치베이스에서는 설명(true)을 설정하여 점수가 어떻게 계산되는지 정확히 확인할 수 있으며, 결과는 기본적으로 점수별로 정렬되므로 가장 관련성이 높은 항목이 목록의 첫 번째 항목에 표시되어야 합니다. 정확히 무엇을 달성하려고 하나요?