
Have you sound yourself asking the question, “What is fuzzy matching?” Fuzzy matching allows you to identify non-exact matches of your target item. It is the foundation stone of many search engine frameworks and one of the main reasons why you can get relevant search results even if you have a typo in your query or a different verbal tense.
As you might expect, there are many fuzzy searching algorithms that can be used for text, but virtually all search engine frameworks (including bleve) use primarily the Levenshtein Distance for fuzzy string matching:
Levenshtein Distance
Also known as Edit Distance, it is the number of transformations (deletions, insertions, or substitutions) required to transform a source string into the target one. For a fuzzy search example, if the target term is “book” and the source is “back”, you will need to change the first “o” to “a” and the second “o” to “c”, which will give us a Levenshtein Distance of 2.Edit Distance is very easy to implement, and it is a popular challenge during code interviews (You can find Levenshtein implementations in JavaScript, Kotlin, Java, and many others here).
Additionally, some frameworks also support the Damerau-Levenshtein distance:
Damerau-Levenshtein distance
It is an extension to Levenshtein Distance, allowing one extra operation: Transposition of two adjacent characters:
Ex: TSAR to STAR
Damerau-Levenshtein distance = 1 (Switching S and T positions cost only one operation)
Levenshtein distance = 2 (Replace S by T and T by S)
Fuzzy matching and relevance
Fuzzy matching has one big side effect; it messes up with relevance. Although Damerau-Levenshtein is a fuzzy matching algorithm that considers most of the common user’s misspellings, it also can include a significant number of false positives, especially when we are using a language with an average of just 5 letters per word, such as English. That is why most of the search engine frameworks prefer to stick with Levenshtein distance. Let’s see a real fuzzy matching example of it:
First, we are going to use this movie catalog dataset. I highly recommend it if you want to play with full-text search. Then, let’s search for movies with “book” in the title. A simple code would look like the following:
|
1 2 3 4 5 6 |
String indexName = “movies_index”; MatchQuery query = SearchQuery.match(“book”).field(“title”); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(6)); printResults(movies); |
The code above will bring the following results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) The Book Thief score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ——————————————– 2) The Book of Eli score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ——————————————– 3) The Book of Life score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ——————————————– 4) Black Book score: 4.826942606027416 Hit Locations: field:title term:book fragment:[Black <mark>Book</mark>] ——————————————– 5) The Jungle Book score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ——————————————– 6) The Jungle Book 2 score: 3.9411821308689627 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ——————————————– |
By default, the results are case-insensitive, but you can easily change this behavior by creating new indexes with different analyzers.
Now, let’s add a fuzzy matching capability to our query by setting fuzziness as 1 (Levenshtein distance 1), which means that “book” and “look” will have the same relevance.
|
1 2 3 4 5 6 |
String indexName = “movies_index”; MatchQuery query = SearchQuery.match(“book”).field(“title”).fuzziness(1); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(6)); printResults(movies); |
And here is the fuzzy search result:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Hook score: 1.1012248063242538 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ——————————————– 2) Here Comes the Boom score: 0.7786835148361213 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ——————————————– 3) Look Who‘s Talking Too score: 0.7047266634351538 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who’s Talking Too] ——————————————– 4) Look Who‘s Talking score: 0.7047266634351538 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who’s Talking] ——————————————– 5) The Book Thief score: 0.5228811753737184 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ——————————————– 6) The Book of Eli score: 0.5228811753737184 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ——————————————– |
Now, the movie called “Hook” is the very first search result, which might not be exactly what the user is expecting in a search for “Book”.
How to minimize false positives during fuzzy lookups
In an ideal world, users would never make any typos while searching for something. However, that is not the world we live in, and if you want your users to have a pleasant experience, you have got to handle at least an edit distance of 1. Therefore, the real question is: How can we make fuzzy string matching while minimizing relevance loss?
We can take advantage of one characteristic of most search engine frameworks: A match with a lower edit distance will usually score higher. That characteristic allows us to combine those two queries with different fuzziness levels into one:
|
1 2 3 4 5 6 7 8 |
String indexName = “movies_index”; String word = “Book”; MatchQuery titleFuzzy = SearchQuery.match(word).fuzziness(1).field(“title”); MatchQuery titleSimple = SearchQuery.match(word).field(“title”); DisjunctionQuery ftsQuery = SearchQuery.disjuncts(titleSimple, titleFuzzy); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, ftsQuery).highlight().limit(20)); printResults(result); |
Here is the result of the fuzzy query above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
1) The Book Thief score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ——————————————– field:title term:book fragment:[The <mark>Book</mark> Thief] ——————————————– 2) The Book of Eli score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ——————————————– field:title term:book fragment:[The <mark>Book</mark> of Eli] ——————————————– 3) The Book of Life score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ——————————————– field:title term:book fragment:[The <mark>Book</mark> of Life] ——————————————– 4) Black Book score: 2.398890092610849 Hit Locations: field:title term:book fragment:[Black <mark>Book</mark>] ——————————————– field:title term:book fragment:[Black <mark>Book</mark>] ——————————————– 5) The Jungle Book score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ——————————————– field:title term:book fragment:[The Jungle <mark>Book</mark>] ——————————————– 6) The Jungle Book 2 score: 1.958685557004688 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ——————————————– field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ——————————————– 7) National Treasure: Book of Secrets score: 1.6962714808368062 Hit Locations: field:title term:book fragment:[National Treasure: <mark>Book</mark> of Secrets] ——————————————– field:title term:book fragment:[National Treasure: <mark>Book</mark> of Secrets] ——————————————– 8) American Pie Presents: The Book of Love score: 1.517191317611584 Hit Locations: field:title term:book fragment:[American Pie Presents: The <mark>Book</mark> of Love] ——————————————– field:title term:book fragment:[American Pie Presents: The <mark>Book</mark> of Love] ——————————————– 9) Hook score: 0.5052232518679681 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ——————————————– 10) Here Comes the Boom score: 0.357246781294941 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ——————————————– 11) Look Who‘s Talking Too score: 0.32331663301992025 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who’s Talking Too] ——————————————– 12) Look Who‘s Talking score: 0.32331663301992025 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who’s Talking] ——————————————– |
As you can see, this result is much closer to what the user might expect. Note that we are using a class called DisjunctionQuery now, disjunctions are an equivalent to the “OR” operator in SQL.
What else could we improve to reduce the negative side effect of a fuzzy matching algorithm? Let’s reanalyze our problem to understand if it needs further improvement:
We already know that fuzzy lookups can produce some unexpected results (e.g. Book -> Look, Hook). However, a single term search is usually a terrible query, as it barely gives us a hint of what exactly the user is trying to accomplish.
Even Google, which has arguably one of the most highly developed fuzzy search algorithms in use, does not know exactly what I’m looking for when I search for “table”:
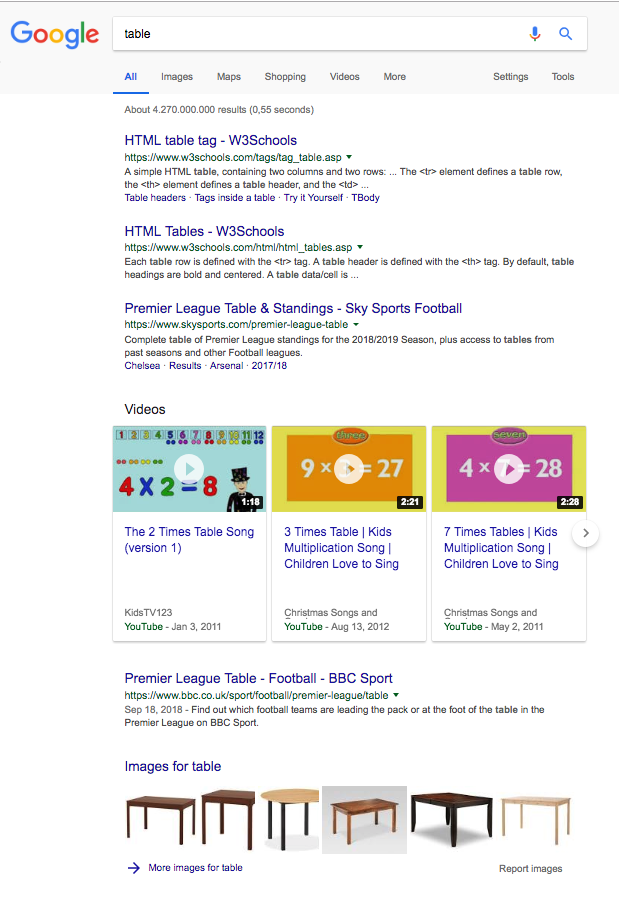
So, what is the average length of keywords in a search query? To answer this question, I will show a graph from Rand Fishkin’s 2016 presentation. (He is one of the most famous gurus in the SEO world)
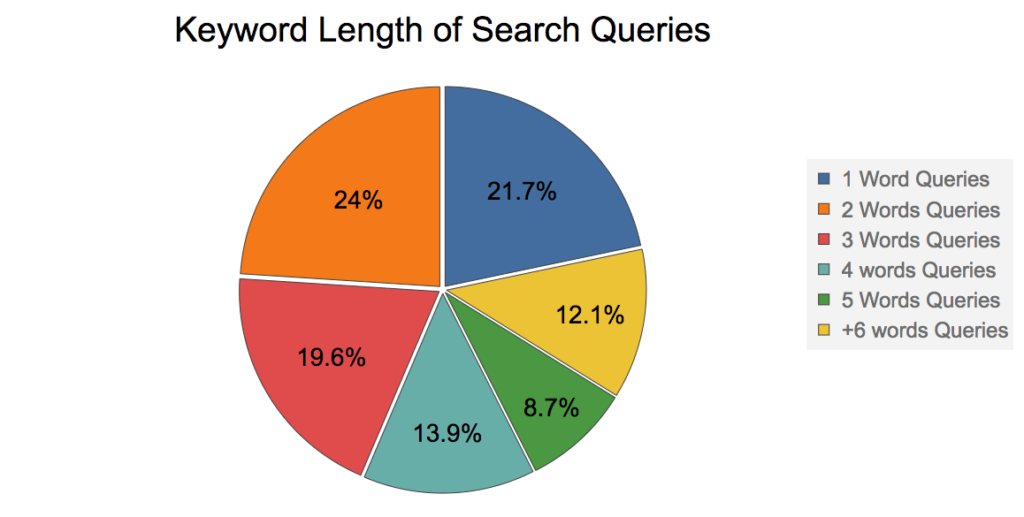
According to the graph above, ~80% of the search queries have 2 or more keywords, so let’s try to search for the movie “Black Book” using fuzziness 1:
|
1 2 3 4 5 6 |
String indexName = “movies_index”; MatchQuery query = SearchQuery.match(“Black Book”).field(“title”).fuzziness(1); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(12)); printResults(movies); |
Result:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
1) Black Book score: 0.6946442424065404 Hit Locations: field:title term:book fragment:[<mark>Black</mark> <mark>Book</mark>] ——————————————– field:title term:black fragment:[<mark>Black</mark> <mark>Book</mark>] ——————————————– 2) Hook score: 0.40139742528039857 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ——————————————– 3) Attack the Block score: 0.2838308365090324 Hit Locations: field:title term:block fragment:[Attack the <mark>Block</mark>] ——————————————– 4) Here Comes the Boom score: 0.2838308365090324 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ——————————————– 5) Look Who‘s Talking Too score: 0.25687349813115684 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who’s Talking Too] ——————————————– 6) Look Who‘s Talking score: 0.25687349813115684 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who’s Talking] ——————————————– 7) Grosse Pointe Blank score: 0.2317469073782136 Hit Locations: field:title term:blank fragment:[Grosse Pointe <mark>Blank</mark>] ——————————————– 8) The Book Thief score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ——————————————– 9) The Book of Eli score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ——————————————– 10) The Book of Life score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ——————————————– 11) The Jungle Book score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ——————————————– 12) Back to the Future score: 0.17061000968368 Hit Locations: field:title term:back fragment:[<mark>Back</mark> to the Future] ——————————————– |
Not bad. We got the movie we were searching for as the first result. However, a disjunction query would still bring a better set of results.
But still, looks like we have a new nice property here; the side effect of fuzziness matching slightly decreases as the number of keywords increases. A search for “Black Book” with fuzziness 1 can still bring results like back look or lack cook (some combinations with edit distance 1), but these are unlikely to be real movie titles.
A search for “book eli” with fuzziness 2 would still bring it as the third result:
|
1 2 3 4 5 6 |
String indexName = “movies_index”; MatchQuery query = SearchQuery.match(“book eli”).field(“title”).fuzziness(2); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(12)); printResults(movies); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Ed Wood score: 0.030723793900031805 Hit Locations: field:title term:wood fragment:[<mark>Ed</mark> <mark>Wood</mark>] ——————————————– field:title term:ed fragment:[<mark>Ed</mark> <mark>Wood</mark>] ——————————————– 2) Man of Tai Chi score: 0.0271042761982626 Hit Locations: field:title term:chi fragment:[Man of <mark>Tai</mark> <mark>Chi</mark>] ——————————————– field:title term:tai fragment:[Man of <mark>Tai</mark> <mark>Chi</mark>] ——————————————– 3) The Book of Eli score: 0.02608335441670756 Hit Locations: field:title term:eli fragment:[The <mark>Book</mark> of <mark>Eli</mark>] ——————————————– field:title term:book fragment:[The <mark>Book</mark> of <mark>Eli</mark>] ——————————————– 4) The Good Lie score: 0.02439822770591834 Hit Locations: field:title term:lie fragment:[The <mark>Good</mark> <mark>Lie</mark>] ——————————————– field:title term:good fragment:[The <mark>Good</mark> <mark>Lie</mark>] ——————————————– |
However, as the average English word is 5 letters long, I would NOT recommend using an edit distance bigger than 2 unless the user is searching for long words that are easy to misspell, like “Schwarzenegger” for instance (at least for non-Germans or non-Austrians).
Conclusion
In this article, we discussed fuzziness matching and how to overcome its major side effect without messing up with its relevance. Mind you, fuzzy matching is just one of the many features which you should take advantage of while implementing a relevant and user-friendly search. We are going to discuss some of them during this series: N-Grams, Stopwords, Steeming, Shingle, Elision. Etc.
Check out also the Part 1 and Part 2 of this series.
In the meantime, if you have any questions, tweet me at @deniswsrosa.
Author
2 respuestas
-
How does the score returned from the index relate to a percentage match? How would one construct a query for which the relevancy score of the results represent a relevancy of > 50%, for example?
-
If you want to understand more about how documents are scored, both lucene and bleve have the “explain” method. In couchbase you can set explain(true) to see exactly how the score is calculated.The results are by default sorted by score, so the most relevant ones should be the first ones in the list. What are you trying to achieve exactly?
-
Deja un comentario
Lo siento, debes estar conectado para publicar un comentario.