머신 러닝과 관련해서는 다음과 같이 많은 것들이 있습니다. 에서 ML 모델 훈련에 관해 많은 이야기를 하고 글을 썼습니다. 하지만 그에 못지않게 중요한 것은 어디 를 사용하면 실시간 예측을 제공할 준비가 되면 해당 모델을 저장할 수 있습니다.
지난 주에는 실시간 예측 제공 시스템에서 Couchbase를 사용하는 5가지 사용 사례. 나중에 머신 러닝(ML) 모델, 모델 메타데이터 및 예측 자체에 전달되는 입력 또는 기능을 저장하는 데 Couchbase가 어떻게 사용되는지 살펴봤습니다.
이 문서에서는 Couchbase Server를 사용하여 학습된 ML 모델을 저장하는 방법을 살펴봅니다.
온라인 머신 러닝과 빠른 모델 스토어의 필요성
일반적으로 머신 러닝 모델은 대량의 과거 데이터를 오프라인에서 학습한 다음 프로덕션에 배포하여 예측을 제공합니다.
하지만 오프라인 교육이 항상 가능한 것은 아닙니다. 예를 들어, 소규모 스타트업의 경우 대량의 학습 데이터에 액세스할 수 없는 경우가 있습니다. 트레이닝 데이터가 충분하지 않은 새로운 ML 사용 사례를 시작하는 팀이 있는 기존 기업도 마찬가지일 수 있습니다. 결과적으로 충분한 학습 데이터가 확보될 때까지 기다리면 제품 출시에 영향을 미치게 됩니다.
이 문제를 해결하기 위해 일부 회사에서는 온라인 머신 러닝. 이 접근 방식에서 기업은 소량의 데이터를 사용하여 초기 모델을 학습시키고 프로덕션 환경에 배포한 다음, 더 많은 데이터를 사용할 수 있게 되면 점진적으로 모델을 재학습시킵니다. 기업에서는 각각 다른 사용 사례를 처리하는 수천 개의 모델을 프로덕션 환경에 배포해야 할 수도 있습니다.
온라인 머신러닝을 사용하면 모델을 매우 자주 업데이트해야 할 수 있습니다. 동시에 새로 업데이트된 모델을 사용하여 예측을 계속 제공해야 합니다. ML 모델을 저장하려면 처리량이 많고 읽기 및 쓰기 대기 시간이 짧은 데이터 저장소가 필요합니다.
카우치베이스에 머신 러닝 모델 저장하기
카우치베이스 데이터 플랫폼 는 온라인 머신 러닝의 성능 요건을 충족합니다. 문서 캐시가 통합된 메모리 우선 아키텍처는 지속적으로 높은 처리량과 밀리초 미만의 일관된 지연 시간을 제공합니다.
카우치베이스 서버 는 바이너리 또는 JSON 형식의 모든 ML 모델을 최대 20MB 크기(즉, Couchbase 문서 제한)로 저장합니다. 모델은 Couchbase 버킷(또는 "컬렉션")에 저장되며, Couchbase에 저장된 다른 데이터와 마찬가지로 액세스할 수 있습니다. 간단한 키-값 업데이트로 모델이 업데이트되므로 ML 모델의 수명 주기를 쉽게 관리할 수 있습니다.
바이너리 대 JSON 모델 형식
ML 모델을 바이너리 형식으로 저장하면 예측을 수행할 때 JSON에서 바이너리로 변환할 필요가 없다는 이점이 있습니다. 또한 바이너리 모델은 크기가 더 작습니다.
그러나 모델을 JSON 형식으로 저장하면 사용자가 다양한 Couchbase 인터페이스를 통해 모델 내부를 살펴볼 수 있습니다. 이는 AI의 설명 가능성에 관심이 있고 ML 모델이 블랙박스가 되는 것을 원하지 않는 사용자에게 유용할 수 있습니다.
모델을 JSON 형식으로 저장하는 또 다른 장점은 카우치베이스 쿼리 서비스 또는 전체 텍스트 검색 서비스 모델을 색인하고 쿼리할 수 있습니다. 카우치베이스 데이터 플랫폼에는 이러한 모든 서비스가 포함되어 있으므로 별도의 제품이 필요하지 않습니다.
또한 Couchbase는 고가용성, 워크로드 증가에 따른 동적 확장 기능, 안전한 데이터 액세스 및 관리 용이성 등 프로덕션 ML 시스템이 모델 저장소에 요구하는 다른 요구 사항도 충족합니다.
ML 모델 포맷 및 ONNX
모델을 훈련하고 배포하는 데 도움이 되는 scikit-learn, TensorFlow와 같은 다양한 ML 프레임워크를 사용할 수 있습니다. 데이터 과학자는 일반적으로 가장 익숙한 프레임워크와 언어를 사용하여 모델을 구축하거나, 모델 학습에 더 적합한 프레임워크를 선택합니다.
때로는 교육 중에 사용된 것과 동일한 언어 및 프레임워크를 사용하여 프로덕션에 모델을 배포하기도 합니다. 이 접근 방식은 사용 편의성을 제공합니다. 그러나 학습에 가장 적합한 언어나 프레임워크가 예측에 최적이 아닐 수도 있습니다.
사용자는 학습된 모델을 다른 프레임워크로 변환하거나 다른 언어로 다시 작성하는 것이 일반적입니다. 오픈 신경망 교환(ONNX) 는 이러한 목적으로 널리 사용되는 모델 교환 형식입니다.
다양한 인기 프레임워크에서 학습된 모델을 ONNX로 변환할 수 있습니다. 그런 다음 배포에 더 적합한 다른 프레임워크로 ONNX 모델을 내보낼 수 있습니다. 또는 모델을 ONNX 형식으로 유지하고 오픈 소스 ONNX 런타임과 같은 지원되는 런타임 중 하나에 배포할 수 있습니다.
ONNX 런타임은 Linux, Windows, Mac에서 지원되며 Python, Java 등 다양한 언어에 대한 바인딩을 사용할 수 있습니다. 제발 자세한 내용은 ONNX 런타임을 참조하십시오..
ML 모델의 직렬화 및 역직렬화
훈련된 모델은 일반적으로 다음과 같습니다. 직렬화 을 클릭하고 어떤 형식으로 파일에 저장한 다음 역직렬화 를 사용하여 배포 중에 복원하고 로드할 수 있습니다. 예를 들어 피클 는 스키킷 학습 모델을 바이트 스트림으로 저장할 수 있는 Python 전용 형식입니다.
머신 러닝 모델을 학습하고, 직렬화하여 Couchbase에 저장한 다음, 검색, 역직렬화하여 예측에 사용하는 방법을 살펴보겠습니다.
우리는 모델을 훈련시킬 것입니다 ( SVM(서포트 벡터 머신) 분류기)를 사용하여 꽃받침과 꽃잎의 크기에 따라 붓꽃의 종류를 예측합니다. 여기서는 홍채 데이터 세트 를 사용하여 모델을 학습시키는 스키킷 학습 프레임워크입니다. 이 데이터 세트에는 세 가지 유형의 붓꽃에 대한 꽃받침과 꽃잎 치수가 총 150행에 걸쳐 포함되어 있습니다.
카우치베이스를 ML 모델 저장소로 사용하기: 바이너리 형식
교육 및 직렬화 워크플로
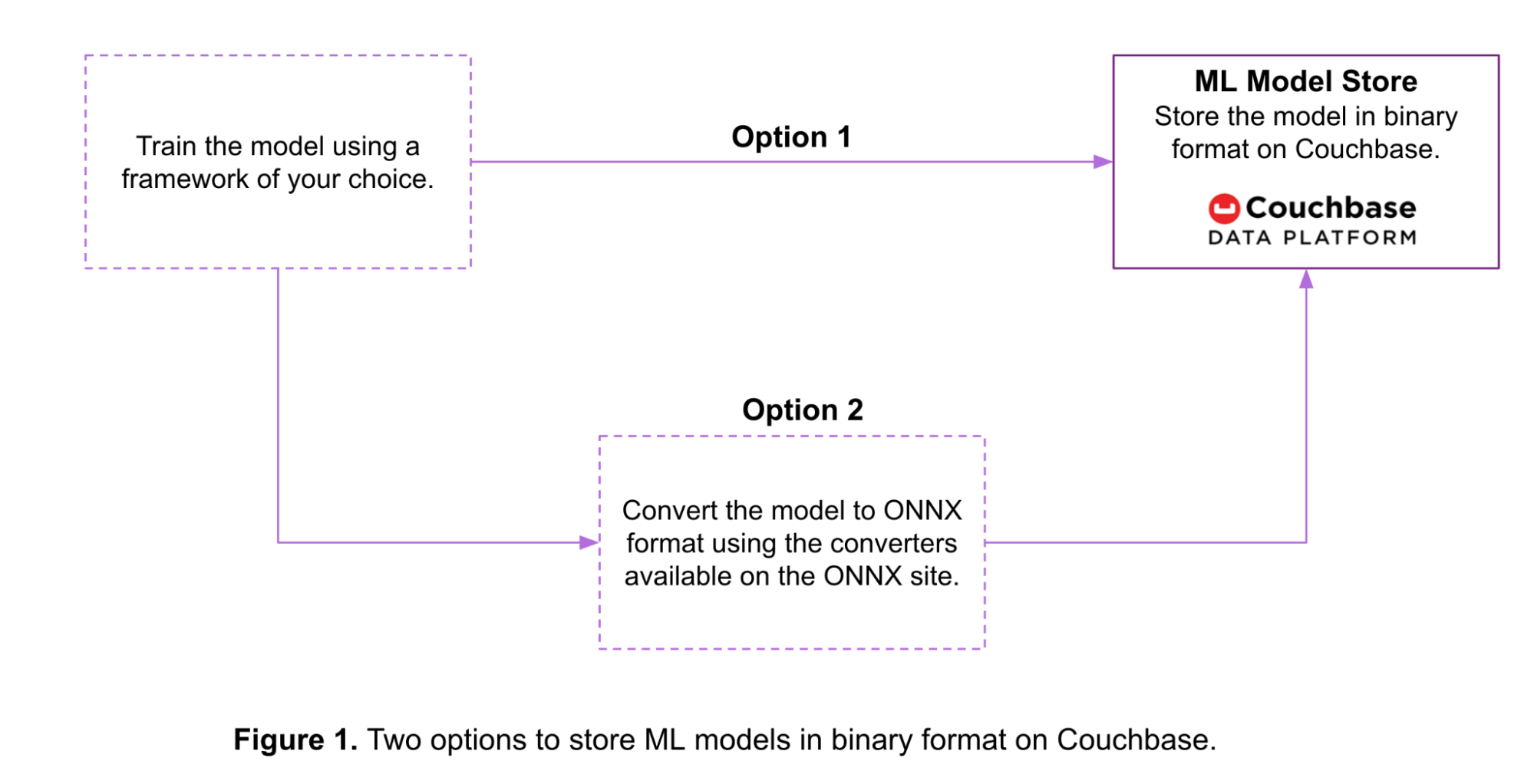
아래 그림 1에서 볼 수 있듯이, Couchbase에서 ML 모델을 바이너리 형식으로 저장하는 데는 두 가지 옵션이 있습니다:
- 옵션 1: 다양한 ML 프레임워크에서 학습된 모델은 프레임워크 자체에서 제공하는 도구를 사용하여 바이트 스트림으로 변환됩니다. 그런 다음 모델은 Couchbase 버킷 내에 해당 형식으로 저장됩니다.
- 옵션 2: 학습된 모델은 Couchbase에 저장되기 전에 ONNX 형식으로 변환됩니다. 다음은 몇 가지 예입니다. 다양한 ML 프레임워크에 사용 가능한 변환 도구.
다음은 옵션 2에 대한 몇 가지 예제 코드입니다. 이 예제에서는
- SVM 분류기는 scikit-learn 프레임워크를 사용하여 홍채 데이터 세트에 대해 학습됩니다.
- 학습된 모델은 스키킷 학습에서 ONNX 형식으로 변환됩니다. 여기에서 제공되는 변환기를 사용하여.
- 그런 다음 ONNX 모델은 다음과 같은 Couchbase 버킷에 저장됩니다.
모델 저장소카우치베이스 파이썬 SDK를 사용합니다. 여기에서 사용 가능한 Couchbase SDK에 대해 자세히 알아보세요..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Step-1: Train a scikit-learn model from sklearn import svm from sklearn import datasets clf = svm.SVC() X, y = datasets.load_iris(return_X_y = True) clf.fit(X, y) # Step-2: Convert the scikit-learn model into ONNX format from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 4]))] onx = convert_sklearn(clf, initial_types = initial_type) # Step-3: Store the ONNX model in binary format in a # Couchbase Bucket from couchbase.cluster import Cluster from couchbase.cluster import PasswordAuthenticator from couchbase import FMT_BYTES cluster = Cluster(host) authenticator = PasswordAuthenticator(user_name, password) cluster.authenticate(authenticator) modelBucket = cluster.open_bucket('ModelRepository') key = "iris.onnx" value = onx.SerializeToString() modelBucket.upsert(key, value, format = FMT_BYTES) |
역직렬화 및 예측 워크플로
예측 서비스 시스템은 카우치베이스에서 모델을 읽고 예측(예: 아이리스 꽃의 종류)을 생성합니다.
다음은 이전 예제에서 Couchbase에 저장된 모델을 읽는 코드입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Read the ONNX model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the previous example rv = modelBucket.get("iris.onnx") onnxModel = rv.value # Predict using ONNX runtime. import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
그런 다음 이 모델을 사용하여 ONNX 런타임을 사용하여 예측을 생성합니다. 예측은 이전 예제에서 얻은 입력 배열 X의 처음 세 행에 대해 생성됩니다.
또한 다음을 수행할 수도 있습니다. 데이터 세트를 학습 데이터와 테스트 데이터로 분할하고 테스트 데이터에 대한 예측을 생성합니다..
카우치베이스를 ML 모델 저장소로 사용하기: JSON 형식
교육 및 직렬화 워크플로
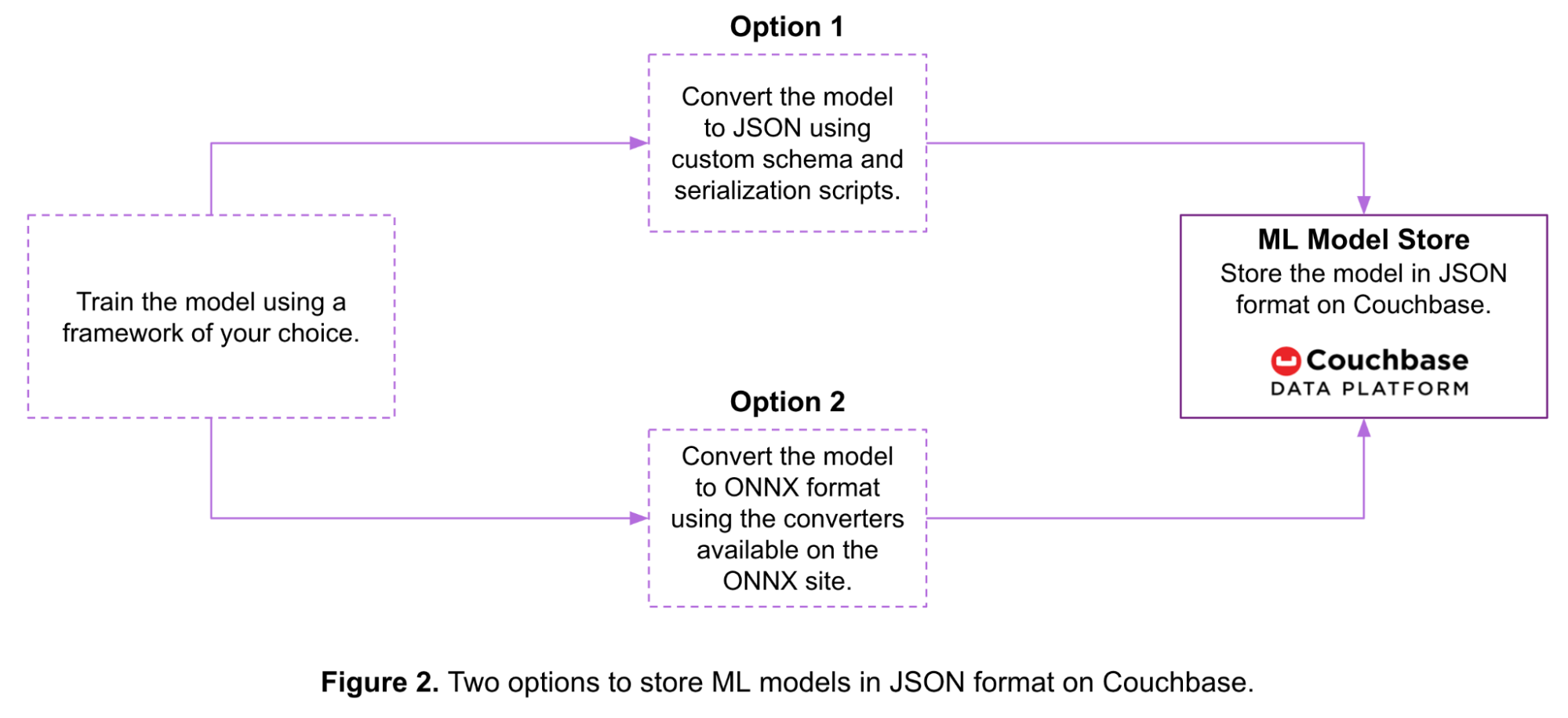
아래 그림 2는 머신 러닝 모델을 Couchbase에 JSON 문서로 저장하는 두 가지 옵션을 보여줍니다:
- 옵션 1: 사용자 지정 스키마와 스크립트를 사용하여 모델을 직렬화한 후 Couchbase에 저장할 수 있습니다.
- 옵션 2: 모델을 ONNX 형식으로 변환한 다음 Couchbase에 저장할 수 있습니다.
다음은 옵션 2에 대한 몇 가지 예제 코드입니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Steps 1 and 2 to train the model and convert it into the ONNX # format as well the steps to connect to a Couchbase bucket # are the same as the one in the earlier binary model example. # Step-3: Convert the ONNX model to JSON & store in a # Couchbase bucket from google.protobuf.json_format import MessageToJson import json key = "iris_json.onnx" value = json.loads(MessageToJson(onx)) modelBucket.upsert(key, value) |
역직렬화 및 예측 워크플로
다음은 이전 예제에서 Couchbase에 저장된 모델을 읽기 위한 역직렬화 코드입니다. 그런 다음 이 모델을 사용하여 ONNX 런타임을 사용하여 예측을 생성합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Read the ONNX-JSON model from Couchbase # Note the steps to connect to the Couchbase bucket # are as shown in the earlier example rv = modelBucket.get("iris_json.onnx") # Convert the ONNX-JSON model to ONNX object from onnx import ModelProto from google.protobuf.json_format import Parse model = ModelProto() Parse(json.dumps(rv.value), model) onnxModel1 = model.SerializeToString() # Predict using ONNX runtime import onnxruntime as rt import numpy sess = rt.InferenceSession(onnxModel1) input_name = sess.get_inputs()[0].name label_name = sess.get_outputs()[0].name prediction1 = sess.run([label_name], {input_name: X[0:3].astype(numpy.float32)})[0] |
ML 모델 저장소로 Couchbase를 사용한 온라인 머신 러닝
온라인 머신 러닝을 위한 ML 모델을 저장하는 데 Couchbase를 사용할 수 있습니다.
아래 그림 3은 카우치베이스 데이터 플랫폼에 저장된 모델을 사용한 온라인 학습 및 예측의 흐름을 보여줍니다.
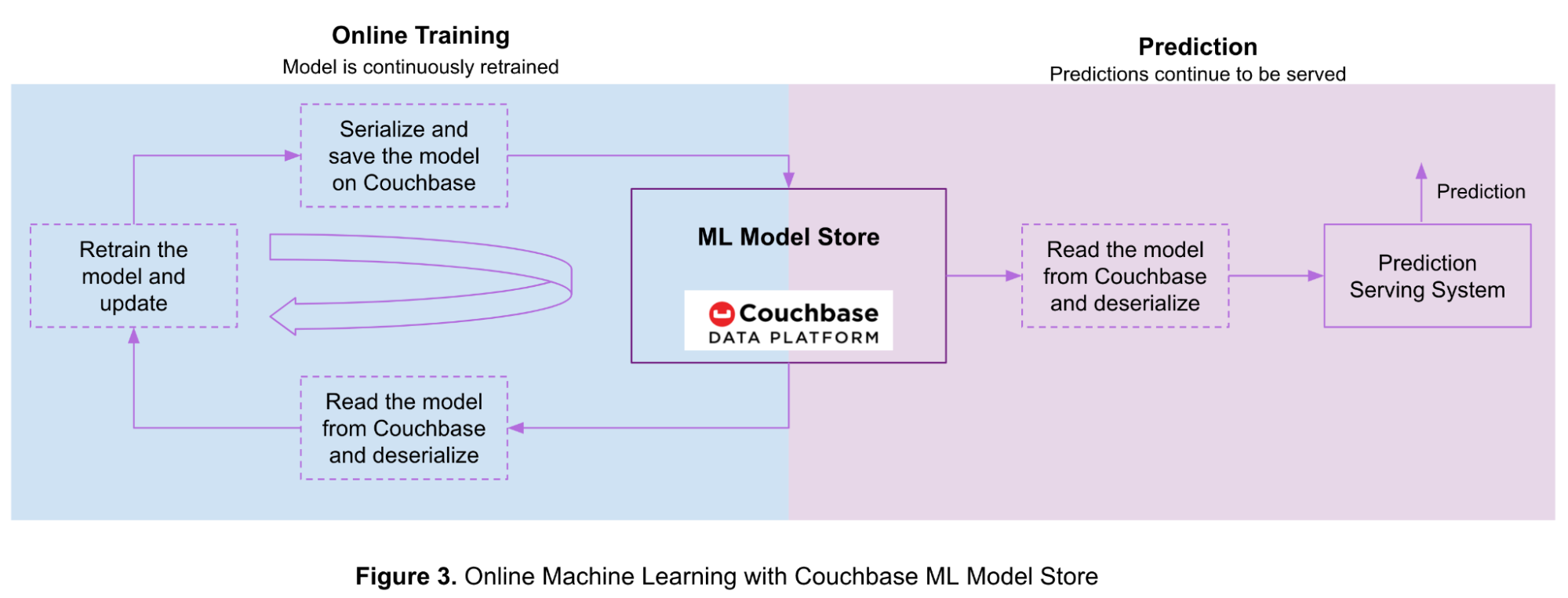
먼저 소량의 학습 데이터로 오프라인에서 모델을 학습한 다음, 이를 직렬화하여 Couchbase 버킷에 저장합니다. 더 많은 데이터를 사용할 수 있게 되면 온라인 학습을 통해 ML 모델을 지속적으로 업데이트합니다.
온라인 머신 러닝에 Couchbase를 사용하는 단계는 다음과 같습니다:
- Couchbase에서 모델을 읽고 이전 섹션에서 언급한 단계를 사용하여 역직렬화합니다.
- 새로 사용 가능한 학습 데이터를 사용하여 모델을 재학습...
- 업데이트된 모델을 직렬화하고 이전 섹션에서 설명한 단계를 사용하여 Couchbase 버킷에 저장합니다.
- 더 많은 학습 데이터를 사용할 수 있게 되면 1단계로 돌아갑니다.
예측 제공 시스템은 다음 단계에 따라 이 프로세스 중에 예측을 계속 제공합니다:
- Couchbase에서 모델을 읽고 이전 섹션에서 언급한 단계를 사용하여 역직렬화합니다.
- 예측을 생성합니다.
가장 일반적인 예측 서비스 시스템의 아키텍처는 지난 주 글에서 설명했습니다: Couchbase를 사용한 실시간 예측 서비스 시스템의 5가지 사용 사례.
결론
아래 그림 4와 같이 다음을 대체할 수 있습니다. 여러 데이터 저장소 제품을 단일 Couchbase 데이터 플랫폼으로 통합할 수 있습니다. 이 접근 방식은 복잡성, 운영 오버헤드, 총소유비용(TCO)을 줄여줍니다.
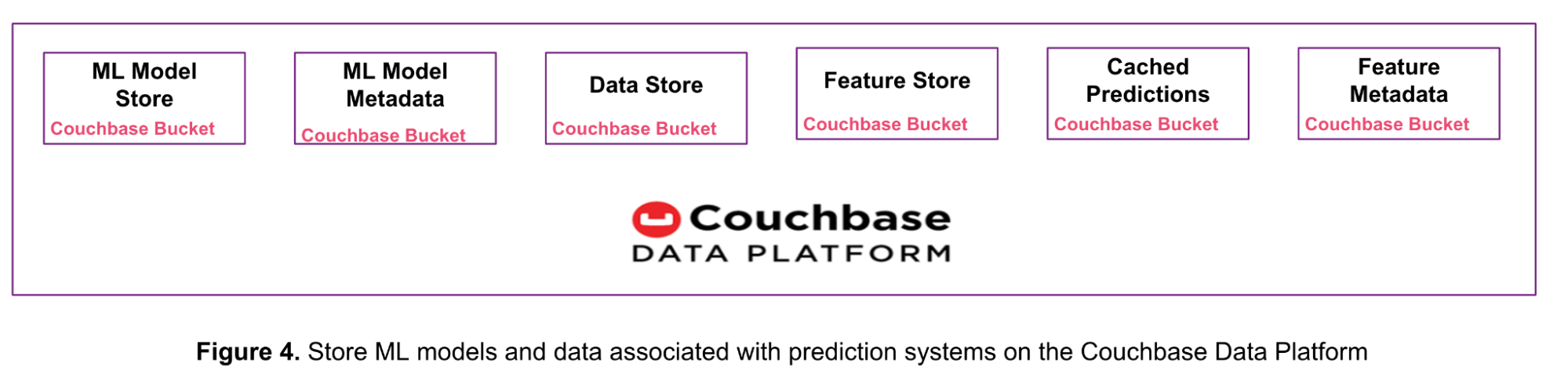
이 글에서 Couchbase 데이터 플랫폼이 최대 20MB 크기의 ML 모델을 저장하는 방법과 온라인 머신 러닝에 어떻게 사용되는지 살펴보았습니다.
지난 주에는 Couchbase를 사용한 실시간 예측 서비스 시스템의 5가지 사용 사례 를 통해 Couchbase 데이터 플랫폼이 원시 입력 데이터, 기능, 예측, 기능 메타데이터 및 모델 메타데이터를 저장하는 방법을 배웠습니다.
이러한 각 유형의 데이터는 별도의 카우치베이스 버킷 또는 컬렉션에 저장할 수 있습니다. 컬렉션은 유사한 항목을 논리적으로 그룹화하기 위한 버킷 내의 데이터 컨테이너입니다. 이 기능은 Couchbase Server 7.0에 도입되었습니다. 다음을 참조하세요. 카우치베이스의 범위 및 컬렉션에 대한 문서를 참조하십시오. 에서 자세한 내용을 확인하세요.
다음 단계
머신 러닝과 Couchbase에 대해 자세히 알아보고 싶다면 다음 단계와 리소스를 통해 시작하세요:
- Couchbase Cloud 무료 평가판 시작하기 - 설치가 필요하지 않습니다.
- 이 백서를 통해 기술적 세부 사항에 대해 자세히 알아보세요: 카우치베이스 내부 살펴보기: 아키텍처 개요.
- 살펴보기 쿼리, 전체 텍스트 검색, 이벤트및 분석 서비스를 제공합니다.
