카우치베이스 카펠라가 AI 서비스를 위한 프라이빗 프리뷰를 출시했습니다! 확인해보세요 이 블로그 에서 이러한 서비스가 어떻게 클라우드 네이티브의 확장 가능한 AI 애플리케이션과 AI 에이전트를 구축하는 프로세스를 간소화하는지에 대한 개요를 확인하세요.
이전 블로그에서는 다음과 같이 설정하는 방법을 설명했습니다. 모델 서비스에 이어 이번 포스팅에서는 다음 중요한 단계를 살펴봄으로써 튜토리얼 시리즈를 이어갑니다. 이 블로그에서는 구조화된 벡터화 서비스를 사용해 JSON 문서를 자동으로 임베드하여 Couchbase 벡터 검색에서 즉시 사용할 수 있도록 하는 방법을 살펴봅니다. 이렇게 하면 원활한 시맨틱 검색과 스마트 데이터 검색을 통해 AI 애플리케이션을 더 쉽게 구축하는 동시에 인프라 내에서 높은 성능과 데이터 보안을 유지할 수 있습니다.
Capella의 벡터화 서비스는 데이터를 대규모로 벡터 임베딩으로 안전하게 변환합니다. 이 서비스는 실시간 처리와 효율적인 데이터 변환을 위해 Couchbase Eventing을 사용합니다. 이를 통해 인프라에 가까운 곳에서 빠르고 안전하게 실행할 수 있습니다.
벡터 임베딩이란 무엇이며 왜 중요한가요?
벡터 임베딩은 텍스트, 이미지 또는 기타 데이터 유형의 미묘한 의미적 의미를 머신 러닝에 적합한 형식으로 캡처한 수치 표현입니다. 검색 증강 생성(RAG) 앱을 구축할 때 임베딩은 유사성을 기반으로 방대한 양의 데이터를 효율적으로 검색하고 순위를 매기는 중추 역할을 하며, 이는 관련 컨텍스트를 실시간으로 제공하는 데 필수적입니다. 예를 들어 시맨틱 검색 엔진, 추천 시스템, 챗봇과 같은 대화형 에이전트, 이미지 인식 앱과 같은 AI 사용 사례는 임베딩을 통해 원시 데이터를 실행 가능한 인사이트로 변환하여 궁극적으로 성능과 사용자 경험을 개선할 수 있습니다.
카펠라 벡터화 서비스는 누가 사용해야 하나요?
Capella에 JSON 문서를 저장하고 AI 개발을 가속화하려는 경우, Capella의 벡터화 서비스가 완벽한 솔루션입니다. 이 서비스는 데이터를 벡터 표현으로 원활하게 변환하여 맞춤형 임베딩 시스템을 구축할 필요가 없습니다.
검색 증강 생성(RAG) 앱 구축, 시맨틱 검색 설정, AI 기반 기능 추가 등 어떤 작업을 하든 이 서비스를 사용하면 빠르고 쉽게 처리할 수 있습니다. 기본 제공되는 효율성과 확장성으로 복잡한 작업을 처리하므로, 데이터를 즉시 AI 인사이트로 변환하는 동안 혁신에 집중할 수 있습니다.
시작하기: 벡터화 워크플로 배포하기
카펠라에서 벡터화 워크플로를 배포하는 간단한 튜토리얼을 살펴보겠습니다.
학습 내용
-
- 카펠라에서 벡터화 워크플로 만들기
- RAG 애플리케이션으로 임베딩 활용하기
전제 조건
시작하기 전에 다음 사항을 확인하세요:
-
- 비공개 미리 보기에 가입하고 조직을 위한 AI 서비스를 사용 설정했습니다. 여기에서 가입하세요!
- 조직 소유자 역할 벡터화 서비스를 관리할 수 있는 권한
- 검색 및 이벤트 서비스가 포함된 멀티 AZ 운영 클러스터
- JSON 문서가 수집되거나 저장되는 기존 키 공간
1단계: 벡터화 워크플로 배포하기
다음으로 이동합니다. AI 서비스 를 클릭하고 벡터화 서비스 를 클릭하여 계속 진행합니다.

워크플로 이름을 입력합니다.

운영 클러스터 선택
여기에서 원시 JSON 문서가 있는 클러스터, 버킷, 범위 및 컬렉션을 선택합니다.
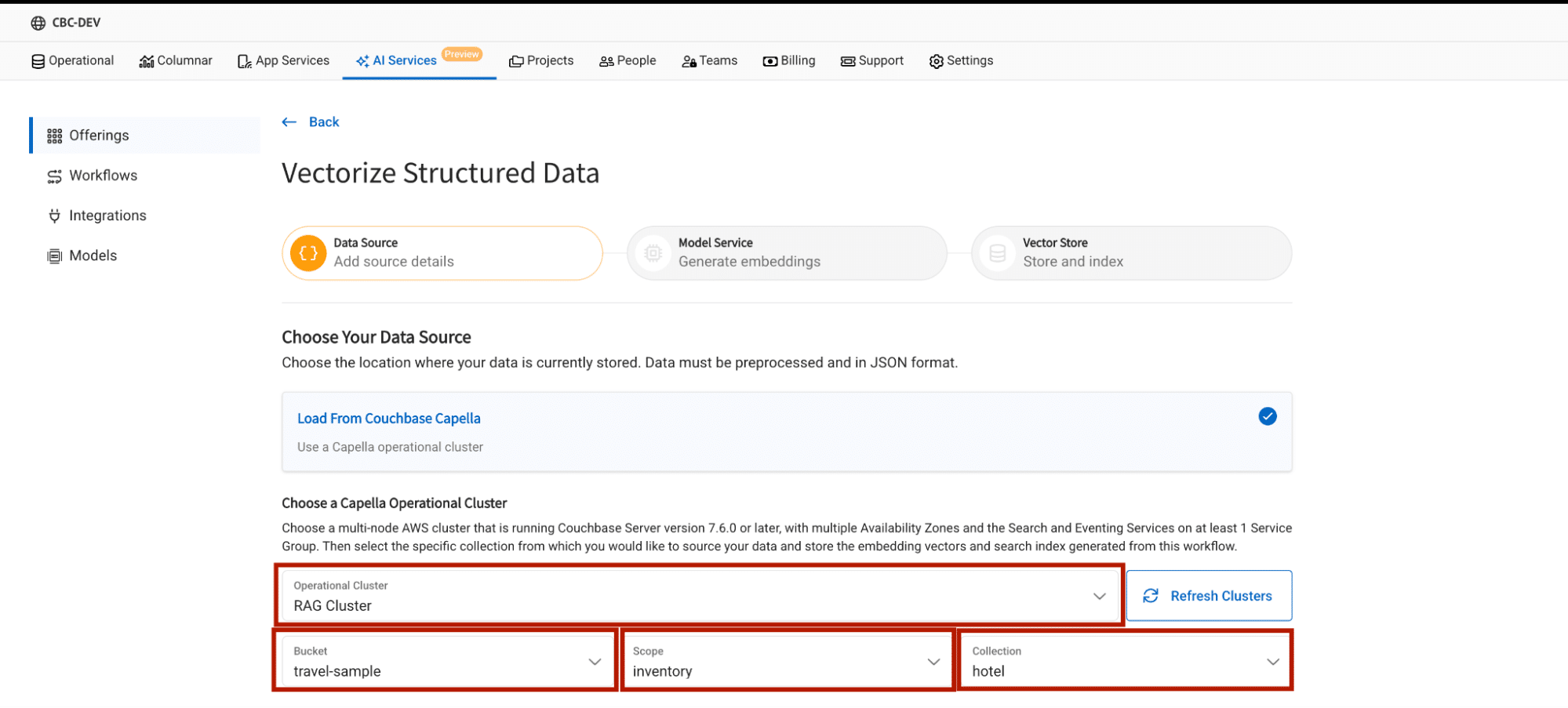
소스 필드 선택
소스 필드는 임베딩을 생성하는 데 사용할 JSON 문서의 일부를 결정합니다.
참고: 벡터화 서비스는 단일 문서에서 임베드할 텍스트를 나타내는 각 객체가 16개의 객체 그룹으로 데이터를 일괄 처리합니다. 그러나 일괄 처리에서 결합된 텍스트가 모델의 최대 허용 입력 길이를 초과하면 해당 문서의 임베딩 프로세스가 실패합니다.
일괄 처리를 사용하면 API 호출 횟수를 줄일 수 있지만 각 문서의 텍스트가 모델의 크기 제한을 벗어나지 않도록 하는 것이 중요합니다. 그렇지 않으면 크기가 큰 텍스트가 포함된 일괄 처리가 성공적으로 처리되지 않습니다.
카펠라에는 두 가지 옵션이 있습니다:
-
- 모든 소스 필드: 전체 JSON 문서에 대한 임베딩을 생성합니다.
- 사용자 정의 소스 필드: 임베딩을 생성할 특정 필드를 지정할 수 있습니다.

임베딩 모델 선택
카우치베이스 카펠라는 임베딩 제공업체로 OpenAI를 선택하거나 카펠라가 호스팅하는 임베딩 모델을 선택할 수 있는 옵션을 제공합니다.
이 블로그를 팔로우하세요. 아카펠라 호스팅 임베딩 모델 만들기.
이 블로그에서는 임베딩 제공업체로서 OpenAI에 초점을 맞출 것입니다.
Capella에서 API 키를 통합으로 추가하면 Capella는 해당 API 키를 AWS Safely 매니저에 안전하게 저장하여 나중에 다시 API 키를 추가하는 번거로움 없이 다른 워크플로에 재사용할 수 있습니다.
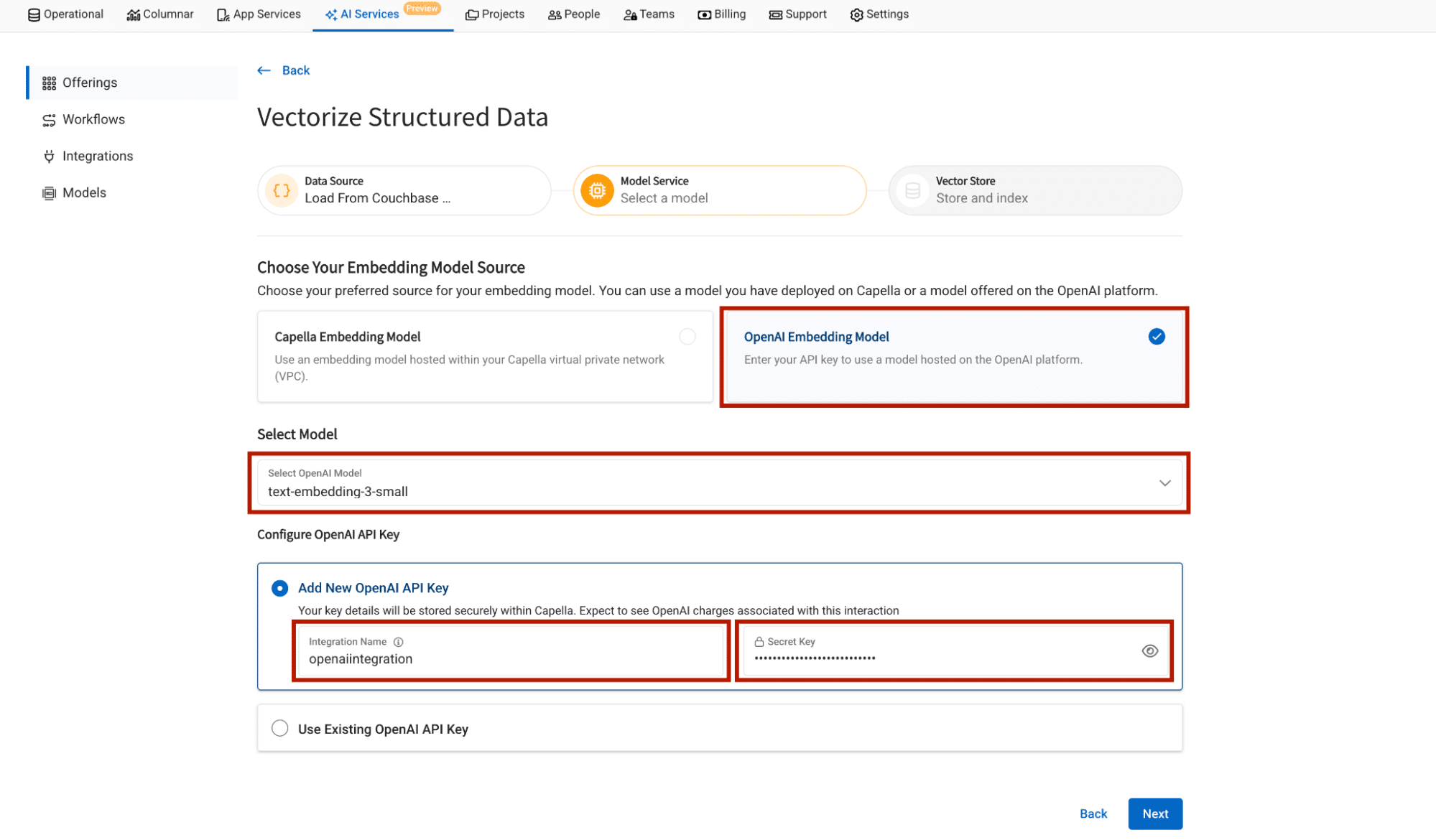
임베딩 필드 이름 및 벡터 인덱스 이름 구성하기

이제 벡터화 워크플로우를 설정했으니 이러한 임베딩을 활용하여 가치 있는 결과를 제공하는 대화형 RAG 애플리케이션을 만들어 보겠습니다.
2단계: RAG 애플리케이션으로 임베딩 활용하기
애플리케이션 정보
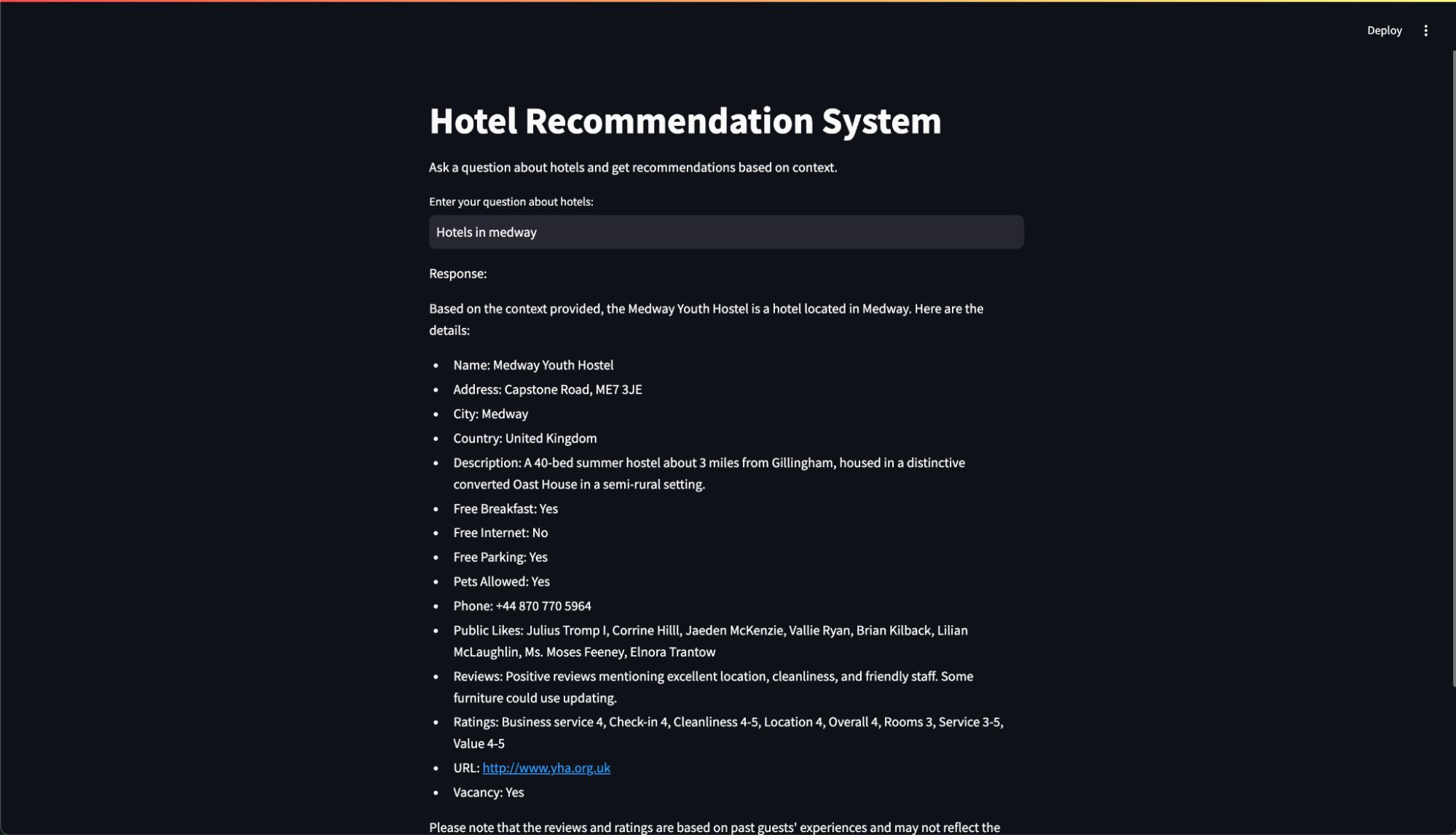
이 애플리케이션은 워크플로우에서 생성된 임베딩을 활용하여 정교한 호텔 추천 시스템. 이 애플리케이션은 사용자 입력을 받으면 정확한 임베딩을 생성하고, 카우치베이스 서버에서 벡터 검색을 수행하며, 고급 대규모 언어 모델(LLM)로 최종 응답을 다듬습니다.
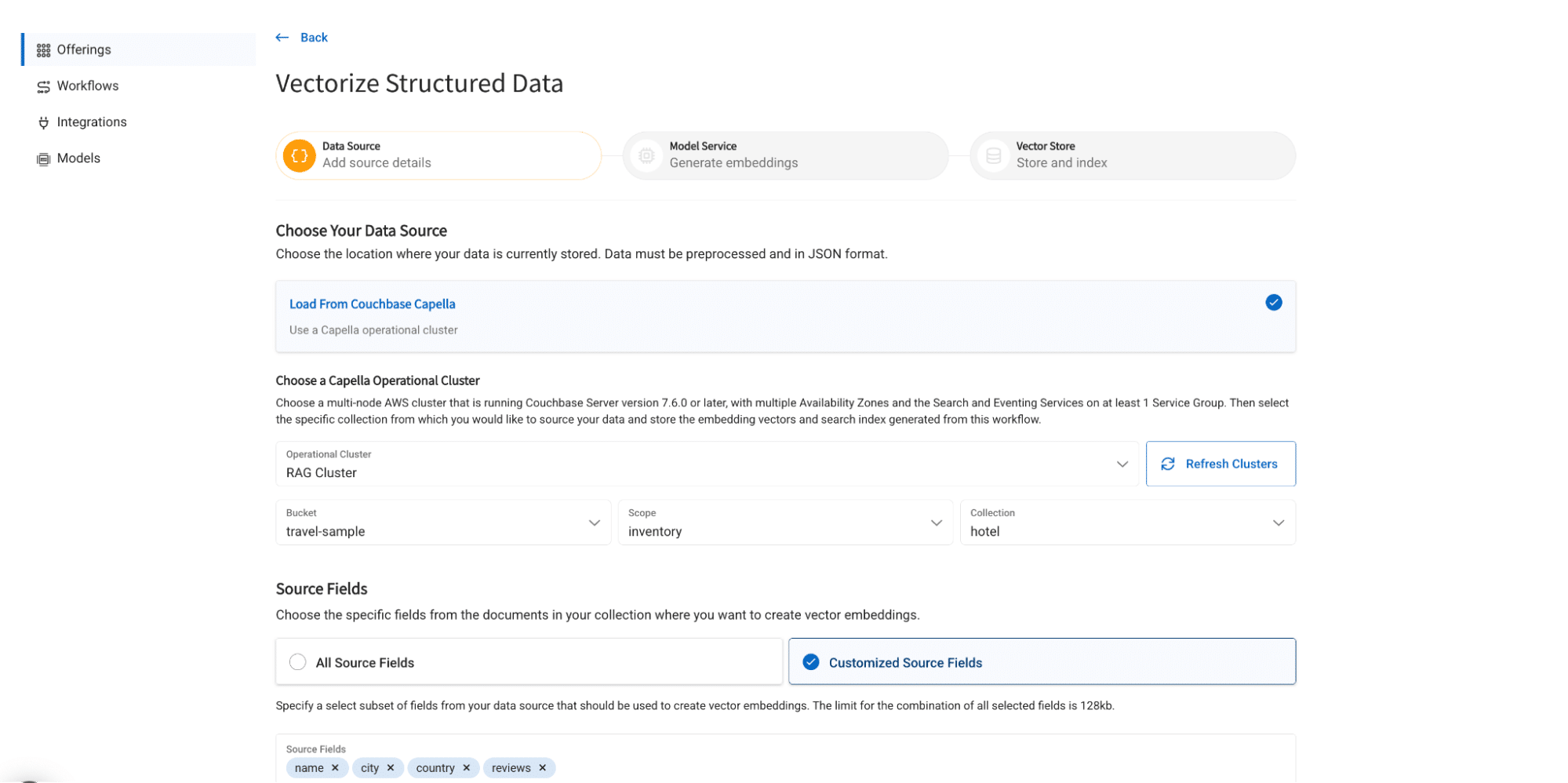
애플리케이션을 사용하려면 여행 샘플 버킷에 임베딩을 생성하고 이름,도시,국가 그리고 리뷰 필드에 입력합니다.
워크플로 설정하기
-
- 여행 샘플 버킷 가져오기
- 다음 구성으로 구조화된 워크플로 만들기
- 버킷: 여행 샘플
- 범위: 인벤토리
- 컬렉션: 호텔
- 소스 필드: 이름, 도시, 국가, 리뷰
애플리케이션 사용해보기
-
- GitHub 리포지토리 복제하기
git clone https://github.com/ayansharma2/RAG-APP.git
-
- 디렉토리 변경
cd RAG-APP
-
- (선택 사항이지만 권장 사항) 가상 환경을 만들고 활성화합니다:
- macOS/Linux에서:
- (선택 사항이지만 권장 사항) 가상 환경을 만들고 활성화합니다:
python3 -m venv venv
소스 venv/bin/activate
-
-
- Windows에서:
-
python -m venv venv
venv\Scripts\activate
-
- 프로젝트 종속성 설치
pip 설치 -r 요구 사항.txt
-
- 애플리케이션 실행
스트림라이트 실행 main.py
실제 적용 사례
최종 생각
Capella의 구조화된 벡터화 서비스는 데이터 임베딩 생성을 간단하고 원활하게 만들어 AI 기반 애플리케이션을 쉽게 구축할 수 있도록 도와줍니다. 이 서비스는 JSON 문서를 벡터 임베딩으로 자동 변환하여 시간을 절약하고 수동 데이터 변환이 필요 없습니다. 따라서 검색 증강 생성(RAG) 시스템, 시맨틱 검색 및 기타 AI 도구의 개발 속도가 빨라집니다. 고성능과 기본 제공 규정 준수를 통해 팀은 더 빠르고 안전하게 혁신할 수 있습니다.
지금 바로 비공개 미리 보기에 등록하고 Couchbase Capella로 더 스마트하고 확장 가능한 애플리케이션을 구축하세요! 여기에서 비공개 미리보기에 등록하세요!
참조
-
- 카펠라 AI 서비스 보도 자료 읽기
- 확인 카펠라 AI 서비스 에 가입하거나 비공개 미리보기
- 카펠라 모델 서비스 문서 (미리 보기 고객용)
감사
팀원들(Abhishek J, Paulomee D, Kiran M, Nithish R, Santosh H, Denis S, Talina S 등)에게 감사드립니다. 직간접적으로 도움을 주신 모든 분들께 감사드립니다!