중요 참고 사항: 이제 Couchbase에서 다중 문서 ACID 트랜잭션을 사용할 수 있습니다. 참조: NoSQL 애플리케이션을 위한 ACID 트랜잭션 에서 자세한 정보를 확인하세요!
산 속성은 제가 자주 묻는 주제입니다. 일반적으로 사람들은 트랜잭션과 관련하여 묻습니다: "NoSQL 트랜잭션이 있나요?", "Couchbase에서 ACID 트랜잭션을 사용할 수 있나요?" 등입니다. 그러나 오늘날의 분산형 애플리케이션이 항상 데이터베이스의 모든 ACID 속성을 기대하거나 필요로 하는 것은 아닙니다. Couchbase에서 NoSQL과 ACID 속성이 어떻게 결합되는지 자세히 살펴보겠습니다.
그 전에 우리가 말하는 것이 무엇인지 정의해 보겠습니다. ACID는 다음을 의미합니다: 원자성, 일관성, 격리, 내구성을 의미합니다. 1980년대에 만들어졌지만 1970년대부터 전통적인 비분산 관계형 데이터베이스에 존재해 왔습니다. ACID를 보장하는 작업을 제공할 수 있는 데이터베이스 클래스를 설명합니다.
카우치베이스 및 트랜잭션
확장성, 성능, 유연성은 Couchbase 데이터 플랫폼의 핵심 초점이었으며, 분산된 다중 문서 트랜잭션은 이러한 특성과 상충되는 경우가 많습니다.
2부로 구성된 이 블로그 게시물의 1부에서는 다음과 같은 ACID의 구성 요소에 대해 다룹니다. 는 를 사용할 수 있습니다. 이러한 "기본 요소"는 Couchbase의 전반적인 확장성, 성능 및 유연성을 희생하지 않고도 사용할 수 있습니다. 사용 사례에 따라 이러한 기본 요소는 단독으로 또는 서로 함께 사용할 수 있습니다.
현재 Couchbase는 단일 문서에서 많은 ACID 속성을 지원하지만 다중 문서 트랜잭션 지원은 제공하지 않습니다. 이 시리즈의 2부에서는 이러한 빌딩 블록을 사용하여 다음과 같은 것을 만드는 접근 방식을 보여드리겠습니다. 같은 를 사용하여 다중 문서 트랜잭션을 처리할 수 있습니다. 하지만 먼저 빌딩 블록을 완전히 이해하는 것이 중요합니다.
ACID 속성이란 무엇인가요?
애플리케이션은 모놀리식에서 분산형 마이크로서비스 기반 애플리케이션으로 진화해 왔습니다. 마이크로서비스는 여전히 원자 커밋이나 롤백과 같은 트랜잭션의 특정 측면을 기대하지만, 반드시 완전한 ACID 동작을 기대하지는 않습니다. 완전한 ACID 동작은 여전히 중요할 수 있지만, 최신 웹 및 모바일 소프트웨어에서는 성능과 확장성보다 우선순위가 낮은 경우가 많습니다. 그러나 "양자택일"의 상황은 아닙니다. Couchbase는 ACID 속성과 성능의 균형을 맞추는 데 도움이 되는 몇 가지 도구와 기능을 제공합니다.
A는 원자성
"원자성"이란 작업 그룹이 모두 성공하거나 모두 실패하는 것을 의미합니다. 카우치베이스는 단일 문서에 대해 원자성을 제공합니다. 문서를 가져오거나 설정하는 작업은 성공하거나 실패합니다. RDBMS의 다음과 같은 보장에 비해 여러 작업의 성공 또는 실패를 함께 고려하면 별것 아닌 것처럼 보일 수 있습니다.
하지만 다음을 고려하십시오. 데이터 모델링 는 문서 데이터베이스와 관계형 데이터베이스 기술 간에 큰 차이가 있습니다.
관계형 데이터베이스에서는 일반적으로 정규화 데이터를 저장합니다. 예를 들어 3개 품목이 있는 장바구니를 저장하려면 다음이 필요합니다:
- 쇼핑 카트 테이블의 1행
- 쇼핑 카트 항목 테이블의 3 행
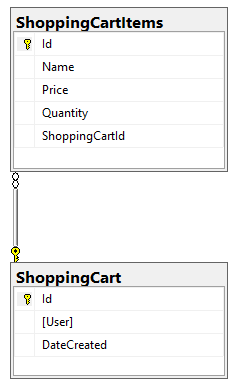
3개 품목이 있는 쇼핑 카트를 생성하려면 다음과 같이 4개가 필요합니다. 삽입 문이 필요합니다. 따라서 이 4개의 문을 원자 단위로 처리하려면 관계형 데이터베이스가 필요할 수 있습니다.
이제 문서 데이터베이스를 생각해 보겠습니다. 3개의 항목이 포함된 단일 장바구니 JSON 문서를 만들 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 |
key cart::001 { "user": "Matthew Groves", "dateCreated": "2018-03-22T13:57:31.2311892-04:00", "items": [ { "name": "widget", "price": 19.99, "quantity": 2}, { "name": "sprocket", "price": 17.89, "quantity": 1}, { "name": "doodad", "price": 20.99, "quantity": 5} ] } |
이 문서를 가져오거나 설정하는 것은 Couchbase에서 단일 원자 연산입니다. 완전히 정규화된 모델이 필요한 경우는 많지 않습니다. 이 모델을 주소로 확장하여 주문을 배송한 지 한 달 후에 주소가 변경되면 주소가 배송된 주문이 실제로 변경되나요? 정규화는 부분적으로 데이터 중복을 줄이는 것을 목표로 합니다. 이는 일부 상황에서는 정확하고 효율적인 방법이지만 모든 경우에 적용되는 것은 아닙니다.
C는 일관성을 위한 것입니다.
"일관성"이란 일반적으로 다음과 같은 작업을 의미합니다. "선언된 시스템 무결성 제약 조건을 위반하지 않음". 데이터에 대한 데이터베이스의 모든 제약 조건은 ACID 작업 전후에 일관되게 유지됩니다. 예를 들어, 원자 연산 집합이 실패하는 경우 데이터는 롤백할 수 있으므로 연산 이전과 일관성을 유지합니다. 데이터베이스에 적용될 수 있는 다른 유형의 일관성 제약 조건도 있습니다. 예를 들어 관계형 데이터베이스에서는 5열 테이블에 6열의 데이터를 삽입할 수 없습니다.
Couchbase는 스키마 대신 JSON을 사용합니다. 모든 문서에는 암시적으로 자체 스키마가 포함되어 있습니다. JSON으로 삽입 작업을 수행하는 경우 유효한 JSON을 제공해야 합니다(일반적으로 Couchbase SDK가 이를 처리합니다). Couchbase는 문서 수준에서만 이를 시행합니다. 카우치베이스는 문서마다 다른 JSON 스키마를 사용하는 것을 막을 수 없습니다. 예를 들어 다음 두 문서를 생각해 보세요:
|
1 2 3 4 5 6 7 8 9 10 11 |
key user::001 { "user": "Matthew Groves", "dateCreated": "2018-03-22T13:57:31.2311892-04:00" } key user::002 { "userName": "Matthew Groves", "the_date_created": "2018-03-22T13:57:31.2311892-04:00" } |
카우치베이스 버킷 허용 두 문서 모두에 있습니다. 필드 이름이 서로 일치하지 않는다는 점에 유의하세요. 즉, 애플리케이션 수준에서 문서에 일관된 이름을 지정해야 하는 책임이 더 커집니다(하지만 일반적으로 데이터 모델에서 파생되므로 자동으로 처리됩니다).
카우치베이스가 적용하는 또 다른 제약 조건은 키입니다. 각 문서에는 고유한 키가 있어야 합니다. 예를 들어 "user::mgroves"의 키를 가진 다른 문서를 삽입하려고 하면 오류가 발생합니다. 따라서 고유한 제약 조건을 적용해야 하는 경우 문서 키를 사용하는 것이 이를 달성하는 한 가지 방법입니다. (가능하면 자연 키를 사용하는 것이 Couchbase 클러스터가 직접 조회를 수행할 수 있도록 하는 데 유리합니다).
쿼리 일관성
마지막으로 언급하고 싶은 것은 인덱스 일관성. WN1QL 쿼리 언어를 사용합니다, 관계형 데이터베이스가 열 또는 열의 조합을 색인할 수 있는 것처럼 Couchbase는 JSON 문서에서 필드 또는 필드 조합을 색인할 수 있습니다(관계형 데이터베이스가 열 또는 열의 조합을 색인하는 것처럼). 그러나 Couchbase는 인덱스를 업데이트합니다. 비동기적으로 를 사용하여 다른 유형의 데이터베이스보다 더 나은 성능을 제공합니다. N1QL 쿼리를 실행할 때 기본 동작은 "Not Bounded"입니다. 즉, 쿼리 엔진이 시스템의 현재 상태에 따라 결과를 반환합니다. 따라서 새 문서를 만들고 즉시 쿼리를 실행하면 해당 문서가 결과에 포함되지 않을 수 있습니다.
다행히도 쿼리의 일관성을 조정하는 다른 두 가지 옵션이 있습니다: 요청 플러스 및 AtPlus.
요청 플러스 는 일관성 스펙트럼의 반대쪽 끝에 있습니다. 쿼리를 처리하기 전에 현재 클러스터에 알려진 모든 문서가 인덱스 재계산의 일부가 될 때까지 기다립니다. 물론 여기에는 지연 시간이 있다는 단점이 있습니다. 요청 플러스 쿼리는 실행하는 데 시간이 더 오래 걸릴 수 있습니다.
AtPlus 가 중간에 있습니다. 전체 인덱스가 완료될 때까지 기다리는 대신, AtPlus는 애플리케이션의 특정 인스턴스에 알려진 문서의 인덱싱만 기다립니다. 이렇게 하면 대기 시간이 짧아지고 일관성이 유지되지만 SDK에 더 많은 작업이 필요합니다. 쿼리 요청도 동일한 인스턴스에서 처리해야 합니다.
I는 격리를 위한 것입니다.
'격리'는 동일한 데이터에 대한 다른 작업이 완료된 후에만 작업이 수행되도록 하는 기능입니다. 이러한 방식으로 각 작업은 독립 의 다른 작업과 비교합니다. 이는 데이터베이스가 동시 데이터 액세스를 처리할 때 매우 중요합니다. 다음과 같이 해야 합니다. 나타나다 데이터베이스가 한 번에 하나의 작업만 처리하도록 합니다. 이를 위해서는 업데이트되는 데이터가 다음과 같아야 합니다. 잠김 작업이 완료될 때까지 수정(및/또는 보기)되지 않도록 설정합니다.
카우치베이스는 기본적으로 (다시) 단일 문서 수준에서 읽기 커밋 격리 기능을 제공합니다.
더 엄격한 격리를 위해 Couchbase에서 수행할 수 있는 잠금 유형에는 두 가지가 있습니다: 비관적 잠금 및 낙관적 잠금.
낙관적 잠금
"낙관적" 잠금은 CAS(비교 및 스왑)라는 Couchbase의 값에 달려 있습니다. 모든 문서에는 불투명한 값인 CAS 값이 있습니다. 해당 문서가 변경될 때마다 새로운 CAS 값을 얻습니다. 문서를 업데이트하려고 할 때 작업의 일부로 CAS 값을 전달합니다. CAS 값이 일치하면 Couchbase는 작업을 허용합니다. 일치하지 않으면 작업이 허용되지 않고 대신 오류를 반환합니다.
예를 들어 두 개의 프로세스가 있다고 가정해 보겠습니다: A와 B. A와 B는 모두 문서를 가져오기 위해 Couchbase에 "get" 요청을 합니다. Couchbase는 CAS 값과 함께 문서를 반환합니다. 그런 다음 A와 B는 모두 이전에 받은 CAS 값을 전달하면서 Couchbase에 "set" 요청을 보냅니다. 처리는 경쟁을 통해 둘 중 하나에서 먼저 발생합니다. B의 차례가 되면 문서의 CAS 값이 이미 변경되었으므로 작업이 실패한다고 가정해 보겠습니다.
다음은 .NET의 예제입니다. 모바일 게임을 개발 중이고 플레이어의 검 레벨을 추적하고 싶다고 가정해 보겠습니다. 레벨이 높을수록 더 많은 피해를 입힙니다. 이 예제에서 A는 레벨 2로 업그레이드하려고 하고 B는 레벨 3으로 업그레이드하려고 합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// create initial document bucket.Upsert("myweapon", new {offenseLevel = 1, name = "Excalibur"}); // document is retrieved by two different applications (A and B) var weaponAResult = bucket.Get<dynamic>("myweapon"); var weaponA = weaponAResult.Value; var weaponBResult = bucket.Get<dynamic>("myweapon"); var weaponB = weaponBResult.Value; // at this point, CAS values should be the same if (weaponAResult.Cas == weaponBResult.Cas) Console.WriteLine("CAS values are currently the same!"); // A makes a change Console.WriteLine("'A' is updating the document"); weaponA.offenseLevel = 2; IOperationResult aResult = bucket.Replace("myweapon", weaponA, weaponAResult.Cas); if (aResult.Success) Console.WriteLine($"Change by 'A' was successful. New CAS value: {aResult.Cas}"); // B tries to make a change too Console.WriteLine($"'B' is (attempting to) update the same document using old CAS value: {weaponBResult.Cas}"); weaponB.offenseLevel = 3; IOperationResult bResult = bucket.Replace("myweapon", weaponB, weaponBResult.Cas); if (!bResult.Success) Console.WriteLine($"Change by B failed: {bResult.Exception.Message}"); |
이 프로세스가 끝나면 B는 실패하고 플레이어의 검은 레벨 2에 머물러 있습니다. B가 성공하도록 하려면 문서를 다시 가져와서 최신 CAS 값을 가져온 다음 다시 시도하는 것이 한 가지 해결책입니다.
물론 이 솔루션은 또다시 실패할 수도 있습니다. 그리고 또다시. 하지만 이것이 바로 "낙관적"이라고 불리는 이유입니다. 문서가 심한 경합을 겪지 않을 것이고 결국에는 성공할 것이라고 가정하기 때문입니다. 서버에 의한 실제 잠금이 필요하지 않고 값만 확인하면 됩니다.
비관적 잠금
비관적 잠금을 사용하여 실제로 잠금을 설정할 수 있습니다. 이 기능은 여러 문서를 변경하기 위해 문서 그래프를 잠그고 싶을 때 유용할 수 있습니다.
카우치베이스에는 "GetAndLock"이라는 원자 연산이 있습니다. 이 연산은 문서와 CAS 값을 반환합니다. 이 시점에서 문서는 "잠긴" 것으로 간주됩니다. 다른 프로세스에서 더 이상 잠글 수 없으며 CAS 값만 문서의 잠금을 해제할 수 있습니다.
다음은 비관적 잠금이 실제로 작동하는 C#의 예시입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// create initial document bucket.Upsert("myshield", new { defenseLevel = 1, name = "Mirror Shield" }); // document is retrieved and locked by A var shieldAResult = bucket.GetAndLock<dynamic>("myshield",TimeSpan.FromMilliseconds(30000)); var shieldA = shieldAResult.Value; // B attempts to get and lock it as well var shieldBResult = bucket.GetAndLock<dynamic>("myshield", TimeSpan.FromMilliseconds(30000)); if (!shieldBResult.Success) { Console.WriteLine("B couldn't establish a lock, trying a plain Get"); shieldBResult = bucket.Get<dynamic>("myshield"); } // B tries to make a change, despite not having a lock Console.WriteLine("'B' is updating the document"); var shieldB = shieldBResult.Value; shieldB.defenseLevel = 3; IOperationResult bResult = bucket.Replace("myshield", shieldB); if (!bResult.Success) { Console.WriteLine($"B was unable to make a change: {bResult.Message}"); Console.WriteLine(); } // A can make the change, but MUST use the CAS value shieldA.defenseLevel = 2; IOperationResult aResult = bucket.Replace("myshield", shieldA); if (!aResult.Success) { Console.WriteLine($"A tried to make a change, but forgot to use a CAS value: {aResult.Message}"); Console.WriteLine(); Console.WriteLine("Trying again with CAS this time"); aResult = bucket.Replace("myshield", shieldA, shieldAResult.Cas); if(aResult.Success) Console.WriteLine("Success!"); } // now, the document is unlocked // so B can try again bResult = bucket.Replace("myshield", shieldB); if (bResult.Success) Console.WriteLine($"B was able to make a change."); |
또한 GetAndLock을 사용할 때는 시간 제한 기간을 설정해야 합니다. 시간 초과 기간이 지나면 Couchbase는 자동으로 잠금을 해제합니다. 다음은 타임아웃이 실제로 작동하는 예시입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
bucket.Upsert("mymagic", new { magicLevel = 1, name = "Fire Magic" }); // alternatively, if A never gets around to releasing the lock // then the lock will automatically be released after a certain time var magicAResult = bucket.GetAndLock<dynamic>("mymagic", TimeSpan.FromMilliseconds(5000)); if(magicAResult.Success) Console.WriteLine("Got a lock on 'mymagic'"); // try to get a new lock every second for (var i = 0; i < 10; i++) { var magicBResult = bucket.GetAndLock<dynamic>("mymagic", TimeSpan.FromMilliseconds(5000)); if (magicBResult.Success) { Console.WriteLine("Got a new lock on 'mymagic'!"); bucket.Unlock("mymagic", magicBResult.Cas); // unlock it right away break; } else { Console.WriteLine("'mymagic' document is still locked."); } Thread.Sleep(1000); } |
이 예제를 실행하면 다음과 같은 출력이 발생합니다:
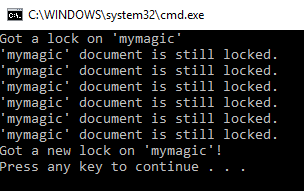
이러한 잠금을 사용하면 개별 문서를 격리하여 예상한 순서대로 변경이 이루어지도록 할 수 있습니다.
D는 내구성을 의미합니다.
"내구성"은 일반적으로 작업이 성공적으로 완료되면 다음과 같은 것을 의미합니다. 디스크 는 작업으로 인한 변경 사항을 저장합니다. 분산형 데이터베이스에서 내구성이란 디스크 및/또는 다른 노드의 메모리 변경 사항을 저장합니다. 네트워크가 디스크보다 훨씬 빠르기 때문에 다른 노드로의 복제는 Couchbase에서 내구성을 위해 선호되는 메커니즘입니다. 궁극적으로 개발자에게는 시스템 장애가 발생하더라도 변경 사항이 계속 유지된다는 의미입니다.
카우치베이스는 "메모리 우선" 아키텍처를 사용합니다. 즉, 쓰기 작업의 결과가 메모리에 수신되면 이를 확인한 다음 대기열에 넣어 비동기식으로 디스크에 쓰거나 곧 다른 노드에 복제합니다. 따라서 어떤 작업이 메모리에 쓰여지고 시스템이 즉시 종료되면 해당 작업은 내구성이 없습니다. 이것이 Couchbase의 기본 트레이드오프입니다. 내구성.
그러나 Couchbase를 사용하면 기본 구성을 재정의하고 다음을 통해 더 강력한 수준의 내구성을 지정할 수 있습니다. 내구성 요구 사항. 이렇게 하면 진자가 성능에서 ACID 속성으로 이동합니다. 이 설계의 장점은 애플리케이션 개발자가 추가 비용을 지불해야 하는 시점을 알고 결정할 수 있다는 것입니다.
기본 동작은 메모리에 문서를 쓰면 성공으로 간주하는 것입니다. Couchbase 클러스터 구성에 따라 계속 유지되고 복제되지만 메서드 호출은 작업이 승인된 후에 진행됩니다.
|
1 2 3 4 |
// default memory-first var result1 = bucket.Upsert("memory-first", new {twitter = "@mgroves"}); if(result1.Success) Console.WriteLine("Success"); |
다음을 사용하여 성공적으로 내구성 있는 작업으로 간주되는 복제할 노드 수를 지정할 수 있습니다. ReplicateTo:
|
1 2 3 4 |
// replicate var result2 = bucket.Upsert("replicate-to-1", new { email = "matthew.groves@couchbase.com" }, ReplicateTo.One); if (!result2.Success) Console.WriteLine("This will also fail if I only have 1 node"); |
또한 다음을 사용하여 다른 노드에 대한 지속성과 다른 노드에 대한 복제의 조합을 지정하여 "충분히" 내구성이 있다고 생각되는 조합을 지정할 수도 있습니다. PersistTo 도 마찬가지입니다:
|
1 2 3 4 |
// persist and replicate var result3 = bucket.Upsert("replicate-to-1-persist-to-1", new { site = "blog.couchbase.com" }, ReplicateTo.One, PersistTo.One); if (!result3.Success) Console.WriteLine("This will also fail if I only have 1 node"); |
이러한 각 메서드 호출은 원하는 값까지 차단됩니다. 내구성 요구 사항 가 충족되면 애플리케이션이 추가 오류 처리를 수행할 수 있습니다.
내구성 요구 사항을 충족하는 경우 실패를 호출해도 Couchbase는 여전히 문서를 저장하고 결국 클러스터 전체에 배포할 수 있습니다. SDK가 아는 한 성공하지 못했다는 것만 알 수 있습니다. 이 정보를 바탕으로 애플리케이션에 더 많은 ACID 속성을 도입하도록 선택할 수 있습니다.
최종 참고 사항
이 블로그 게시물에서는 애플리케이션에 ACID와 유사한 보증을 구축하기 위해 Couchbase에서 사용할 수 있는 다양한 기본 요소에 대해 설명했습니다. 이러한 기본 요소는 완전한 ACID 정의를 충족하지는 않지만, 대부분의 최신 마이크로서비스 기반 애플리케이션이 필요로 하는 것에는 충분합니다. 추가적인 트랜잭션 보장이 필요한 소수의 사용 사례를 위해 Couchbase는 계속해서 혁신을 거듭할 것입니다.
다음 게시물에서는 Couchbase에서 다중 문서 트랜잭션을 구축하는 데 활용할 수 있는 기술과 샘플 코드를 살펴보겠습니다.
이 블로그 게시물의 모든 공동 집필자에게 특별히 감사드립니다: 시바니 굽타, 라비드 마유람, 존 리앙, 친 홍, 매트 인젠트론, 마이클 니칭어(그리고 제가 놓친 분들도 있을 겁니다).
Matt, 좋은 글입니다! 문서 참조 및 조인 측면에서 Couchbase 내에서 "일관성"에 대해 논의하는 것도 도움이 될 것 같습니다. 즉, 한 문서를 다른 문서에서 참조하여 비정규화의 일반적인 문제를 피할 수 있다는 것입니다. 이렇게 하면 어느 문서에 쓰기를 해도 여전히 ACID입니다.
고마워요, 페리. '원자성'이 더 적절하다고 생각해서 '원자성'을 제외하고는 정확히 논의했습니다.
고마워요 Matt, 초기 토론을 보았지만 두 문서 간의 연결을 표시하고 다시 읽을 때 N1QL JOIN을 사용하여 여러 문서를 "일관되게" 업데이트 할 수있는 방법을 강조 할 가치가 있다고 생각합니다. 즉, 문서 1에는 대부분의 사용자 프로필과 주문 목록이 포함 된 문서 2에 대한 포인터 / 참조가 포함되어 있습니다. 문서2를 업데이트하면 문서1과 문서2를 모두 원자적으로 업데이트하지 않아도 다시 읽을 때(JOIN을 통해) 전체 사용자 프로필과 여전히 일관성이 유지됩니다. 정규화와 비정규화의 이러한 조합이 Couchbase를 매우 강력하고 쉽게 원자성과 일관성을 달성할 수 있게 해줍니다. 문서1은 여러 테이블을 포함하도록 비정규화되지만, 문서1+문서2는 데이터 부풀림을 방지하고 동시성을 개선하기 위해 정규화되지만, 두 문서(또는 체인의 모든 문서)를 업데이트할 때는 여전히 원자적이고 일관된 조합을 유지합니다. 더 이해가 되시나요?