
Since the start of this year, we (Couchbase Indexing Team) undertook a project to improve indexing service on Capella. This blog discusses the goals we planned to achieve at the start of this project and the list of improvements delivered to achieve that goal. Please note that most of these improvements – even though targeted for Capella (Couchbase’s cloud database) – are also valid for self-managed clusters of Couchbase Server.
Goals
- Faster scaling operations: For cloud databases, scaling can be a very frequent activity, so it needs to be fast.
- Improve support for low-end hardware: Users may start with a low-end hardware to begin with, and later provision more/high-end hardware, as and when the application demand increases.
- Improve support for slow disk i/o: Cloud deployments use EBS like storage, which is likely to be slower than directly attached SSDs. So, the cost of a single i/o operation gets multiplied in a cloud environment.
The ultimate goal was to improve overall user experience.
The following sections explain the index service improvements done in Couchbase Server release 7.2.2, and how these improvements achieve the above mentioned goals.
Faster scaling operations
User application workload can increase/decrease frequently. When users expect the application workload to increase, users can perform either “add more nodes (i.e. scale out)”, or “increase the CPU/Memory of the nodes (i.e. scale up)”, or do both.
To scale out, Capella adds more index service nodes (having the same configuration as that of existing nodes) to the cluster. This is followed by Couchbase Server Rebalance, where the indexes may get moved from their current host node to any other node in the cluster. This movement is performed to achieve a balanced load distribution across all the indexer nodes.
To scale up, Capella scaling operation internally triggers a sequence of couchbase server’s swap rebalance operations. Each swap rebalance adds one new node (having the upgraded configuration) and removes one old node (having the old configuration). Once all the old nodes have been replaced by new nodes, the scaling operation finishes. During swap rebalance, index service needs to move the indexes from the old node to the new node, so that indexes won’t be lost.
Index service performs the index movement by (1) rebuilding the index using Data Change Protocol (DCP) on the target node, and then (2) deleting the index from the source node. As rebuilding of indexes on the target node can be CPU intensive, index service moves the indexes in batches. Each batch will require reading of the stream of the data from data service, and indexes get built on index service nodes. Once a batch of indexes is moved to the target node, that batch of indexes can serve N1QL queries (index scans) from the target node.
Scale out example
Following diagrams depict an example of the two-step “Scale Out” workflow using DCP based rebalance. Here, index service has decided to move indexes 3, 6 and 9 to the new node. Similarly, index 5 will move from node 1 to node 2. So, in the first step, indexes 3, 6 and 9 will be rebuilt on the new index node with the help of DCP. Similarly, index 5 will be rebuilt on node 2.
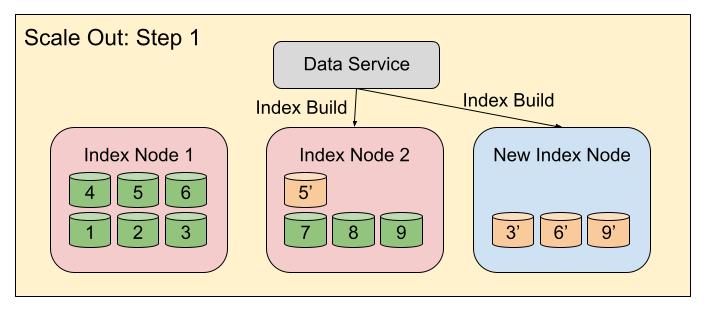
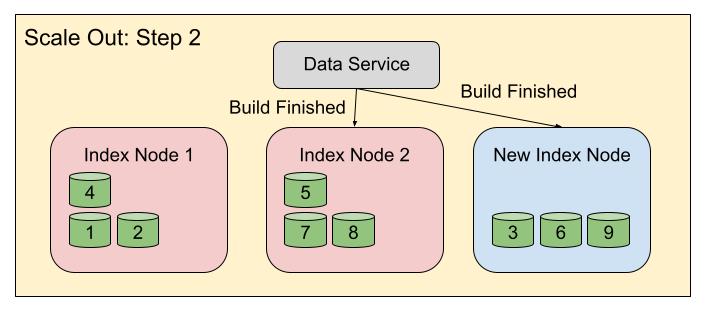
Then in the second step, indexes 3, 6 and 9 on the new node will be activated, while their older copies will be deleted from their previous host. Similarly, index 5 on node 2 will be activated, and its old copy will be deleted from node 1.
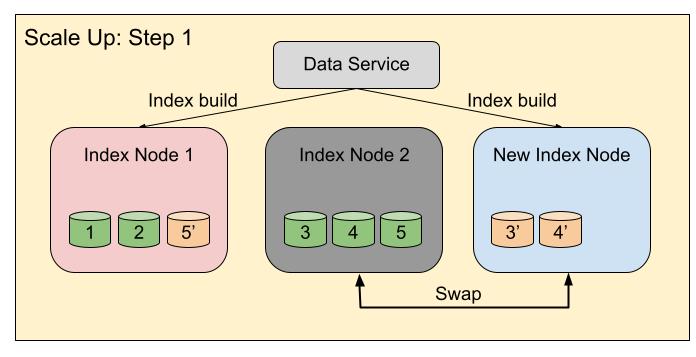
Scale up example
Following diagrams depict the DCP based swap rebalance process, which is used to perform scale up operation on nodes. Here, in the first step, a new index node is added to the cluster. The index service has decided to move indexes 3 and 4 to the new index node, while index 5 will be moved to index node 1. So, in the first step, index 3 and 4 will be rebuilt on the new index node, while index 5 will be rebuilt on index node 1.
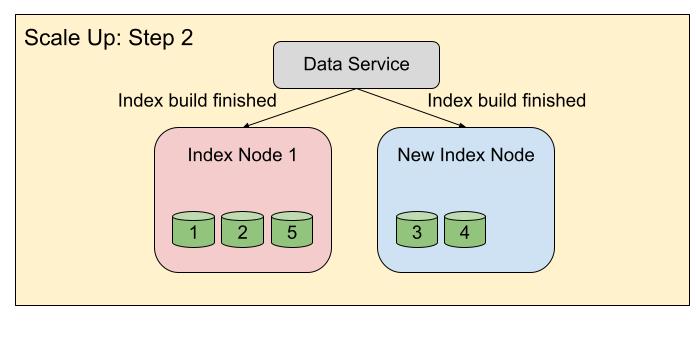
In the second step, when the index build for index 3, 4 and 5 is finished, the indexes will be activated on their corresponding destination nodes, and index node 2 will be removed from the cluster.
In Couchbase Server 7.2.2, scaling operation is made faster by:
- Increasing the number of indexes being moved in a batch
By default, the number of indexes being rebuilt on the target node is capped by a small number. The reason for choosing the small number is to avoid resource (CPU) contention between index rebuild and index scans. To solve this resource contention problem, in Couchbase Server 7.2.2, we avoided forwarding index scans to the new node, until all indexes on that node are rebuilt. With this, the entire CPU can be used for index rebuild, which enables moving of more indexes in a single batch. Please note that the larger batch is used only when the batch of indexes is moving to an “empty” node in the cluster. For non-empty nodes (i.e. nodes which are hosting some indexes), they will be required to serve index scans and CPU sharing is needed. That’s why the larger batch size is used only when indexes are moving to an empty node. Following are the default batch sizes:
Non-empty node batch Size: 3
Empty batch Size: 20
Note: increased batch size allows reducing the load on data service, as number of times data items are read from the data service are also reduced.
- Avoiding index movement between existing nodes
In case of scale out, index service can move the indexes among existing nodes in the cluster. Similarly, in case of swap rebalance, index service can move the indexes from the old node to other existing nodes as well. Such index movements are done primarily to achieve balanced load distribution in the cluster. But conceptually, these extra index movements add to the scaling overhead.
In Couchbase Server 7.2.2, the movement of the indexes is restricted to the movements which are required to ensure the functionality. Unnecessary movements are avoided.
In the above examples, in case of scale out, movement of index 5 from node 1 to node 2 will be avoided. Similarly, in case of scale up, index 5 will be moved to the newly added node instead of node 1.
Please note that, to achieve balanced load distribution, a rebalance operation can be explicitly triggered after the scaling operation finishes.
Experimental results
The experiment performs scale-out for index service, i.e. scaling from 3 index service nodes to 4 index service nodes. There are 100 indexes spread across the 3 index service nodes. As a part of scaling, these 100 indexes will be re-distributed across 4 nodes. Also, during the rebalance operation, the front-end data update workload as well as scan workload is running. So, using this experiment we were able to verify that the impact of an ongoing rebalance operation on incoming queries was reduced.
Results table:
| Couchbase Server version | 7.2.0 | 7.2.2 |
|---|---|---|
| Time taken for Scale out (from 3 to 4 index nodes) | 20.7 min | 6.8 min |
| Data Service CPU consumption during scaling operation | 400% | 270% |
Apart from above results, in our internal testing, we have also observed 8x and 15x improvement in 95th and 99th percentile query latencies respectively.
Note: This feature is enabled by default on the provisioned Capella clusters. For self-managed clusters please use the following setting to enable it.
The following REST command can be used to enable empty-node batching:
curl -X POST -u https://:9102/settings --data '{"indexer.rebalance.enableEmptyNodeBatching" : true}'
This REST command can be used to change empty-node batch size to 25:
curl -X POST -u https://:9102/settings --data '{"indexer.rebalance.emptyNodeBuildBatchSize" : 25}'
What’s next?
In the next part of this blog, we will discuss more index service improvements in Couchbase Server 7.2.2.
Learn more about Couchbase products:
- Download Couchbase Server
- Start a free trial of Couchbase Capella (DBaas)
- Access Couchbase developer documentation
- See who else is using Couchbase
Author
2 Comments
-
“Index service performs the index movement by (1) rebuilding the index using Data Change Protocol (DCP) on the target node, and then (2) deleting the index from the source node.”
Would it not be simpler (and far more efficient) to just copy the physical index files from node 1 to node 2? The GSI are anyway (Secondary Key, PK) pairs, so the physical copy would be valid. What am I missing?
-
Check out the latest new feature that does exactly that to reduce overhead: https://www.couchbase.com/blog/file-transfer-index-rebalance/ – since Couchbase Server 7.6.
-
Leave a comment
You must be logged in to post a comment.