Menos es más. - Ludwig Mies van der Rohe
No hay nada más cierto sobre los objetivos de un optimizador de consultas. Hacer menos: Menos memoria, menos CPU, menos disco, menos IO, menos instrucciones, menos particiones, menos desbordamiento. Menos todo para el plan de consulta que crea. Esta es la luz que guía a SQL y Optimizadores NoSQL.
En Couchbase 6.5, anunciamos el optimizador basado en costes (CBO-preview) para N1QL en el servicio de consultas. Aquí, he tratado de responder a las preguntas de los usuarios NoSQL que no están familiarizados con los beneficios de CBO.
- ¿Por qué necesitamos realmente un CBO?
- ¿Cuáles son las implicaciones para el rendimiento sin un CBO?
El tema es vasto. Las respuestas son breves y no exhaustivas.
En 2019, cuando importa -como llegar a tiempo al recital de tu hijo o a un partido de béisbol-, ¿usarías un mapa de direcciones estático que no tiene en cuenta el tráfico? El optimizador de rutas de Google Maps optimizará el tiempo. Los optimizadores intentan elaborar un plan para ejecutar la consulta con la menor cantidad de recursos: CPU, memoria. Sabiendo esto, ¿por qué aceptar una regla estática (o forma de la consulta) en la carga de trabajo crítica de su base de datos?
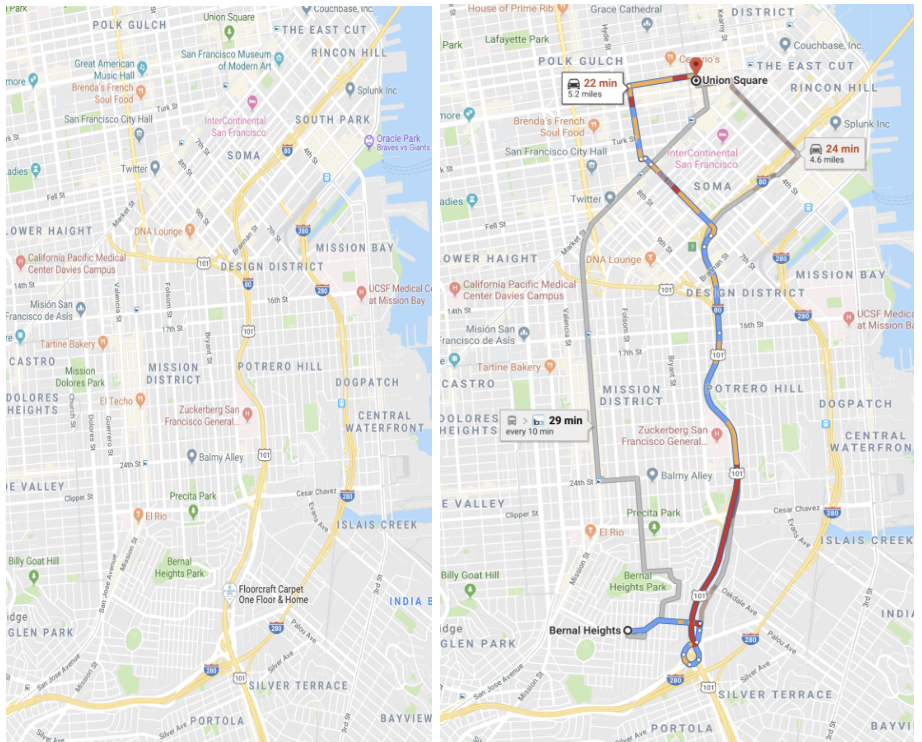
El optimizador de la base de datos toma decisiones. Estas decisiones tienen implicaciones importantes en el rendimiento de las consultas, el rendimiento del sistema y su capacidad para cumplir los SLA. Las bases de datos con un mejor optimizador facilitarán el desarrollo, la gestión y el cumplimiento de los SLA.
SQL es el lenguaje de 4ª generación más exitoso. Como lenguaje, es extraordinariamente flexible, incluso cuando el esquema subyacente no lo es. Puedes seleccionar, unir, proyectar cualquier relación (tabla o relaciones intermedias) sin tener que planificar todas las combinaciones de antemano. Esto beneficia al desarrollo de aplicaciones y al análisis de datos. Este explica cómo las principales bases de datos NoSQL han implementado varios elementos de SQL. Por lo tanto, incluso las bases de datos NoSQL tienen que preocuparse por la optimización.
La extraordinaria flexibilidad de un lenguaje de consulta conlleva la extraordinaria responsabilidad de optimizar y ejecutar las consultas de forma eficiente. Las primeras implementaciones de SQL utilizaban optimizadores basados en reglas. Esto llevó a la complejidad de las reglas, las sugerencias del optimizador definidas por el usuario y los problemas de eficiencia del plan de consulta para consultas complejas. El sitio optimizador basado en costes (CBO) lo cambió todo, optimizando correctamente la consulta para una gran variedad de datos, datos sesgados y cargas de trabajo. No es exagerado decir que los RDBMS no habrían tenido tanto éxito en la gestión de casos de uso tan ricos a tan bajo coste sin un CBO. Lo mismo puede decirse de los sistemas NoSQL con optimizadores.
El optimizador de la base de datos toma decisiones. Las malas decisiones tienen enormes implicaciones negativas para el rendimiento. Para las cargas de trabajo del mundo real, las decisiones basadas en estadísticas son mucho mejores que las decisiones basadas en reglas. Las estadísticas lo demuestran.
El optimizador, a grandes rasgos, hace lo siguiente:
- REWRITE: Reescribir la consulta a su forma equivalente óptima para facilitar la optimización. Esto incluye evaluar filtros constantes, convertir uniones, aplanar subconsultas, plegar las subconsultas y mucho más. El tipo de reescritura depende de las capacidades y matices específicos del optimizador en fases posteriores.
- RUTA DE ACCESO: Selección de índices disponibles o escaneo completo (escaneo de índice primario en el caso de Couchbase) para cada espacio clave (equivalente a tablas). Aquí seleccionamos uno o más índices para cada espacio de claves, decidimos los predicados (spans) para cada solicitud de escaneo, decidimos si está cubriendo o no.
- JOIN ORDER: El objetivo es limitar el tamaño del conjunto de resultados intermedios. Los JOINS se realizan sobre dos keypaces (tablas) a la vez. Dependiendo del tipo de join, podemos cambiar el orden sin cambiar el significado y el resultado de la consulta. Por ejemplo, ((t1 INNER JOIN t2) INNER JOIN t3) es lo mismo que ((t3 INNER JOIN t2) INNER JOIN t1). Aquí, seleccionamos la secuencia en la que se realizan las uniones. El Optimizador N1QL aún no reordena las uniones.
- TIPO DE UNIÓN: Cada motor de consulta es capaz de realizar ciertos tipos de uniones. Tanto el servicio de consultas como el servicio de análisis de Couchbase soportan el bucle anidado (NLJ) y el hash join (HJ). Para el servicio de consulta, el bucle anidado es el predeterminado y para el servicio de análisis, la unión hash es la predeterminada. Una vez elegido el tipo de unión, hay que tomar decisiones adicionales sobre el orden dentro de la unión. Para NLJ, tenemos que decidir qué tabla es la externa y cuál es la interna. Normalmente, se elige la tabla (espacio de claves) con un conjunto de resultados más pequeño para que sea la tabla externa. Para HJ, tenemos que decidir qué tabla es el lado de construcción (tabla hash) y la otra se convierte en el lado de sondeo del plan.
- Existen consideraciones adicionales para las optimizaciones (por ejemplo, optimización de la primera fila cuando se especifica la cláusula LIMIT).
- CREAR ÁRBOL DE EJECUCIÓN: Por último, crea el árbol de ejecución de la consulta (plan) con los operadores y los valores de los parámetros que representan las decisiones de las fases anteriores.
Por ejemplo:
SELECT id, address FROM customer WHERE postalcode = 57020;
La misma consulta puede operar sobre una sola fila, millones de filas o miles de millones de filas. Esto es posiblemente lo más sencillo que puede ser una consulta, pero la complejidad se esconde justo debajo de la superficie. El optimizador puede tener muchas opciones para llegar a los datos.
- Un escaneo completo de la tabla es siempre una opción. Si la tabla de clientes tiene sólo unas pocas filas que caben en una o dos páginas de la base de datos, un escaneo completo de la tabla puede ser el camino más eficiente para llegar a los datos.
- Imagina que tienes un índice sobre la mesa.
- CREATE INDEX i1 ON customer(postalcode)
Se podría pensar que la ruta del índice, en la que primero se escanea el índice para encontrar el rowid de las filas que coinciden con el predicado y luego se obtienen las filas para proyectar las columnas de adición (id, dirección) será la mejor. No es tan rápido. ¿Qué pasa si la tabla tiene un millón de filas y TODAS ellas tienen exactamente el mismo código postal - 57020? Entonces la ruta de acceso al índice es realmente más cara que una exploración de la tabla.
Consideremos ahora una ligera modificación de la consulta.
SELECT id, address FROM customer WHERE postalcode = 57020 and yob < 1980;
Considera que tienes los siguientes índices:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX i1 ON customer(postalcode); CREATE INDEX i2 ON customer(yob); CREATE INDEX i3 ON customer(postalcode, yob); CREATE INDEX i4 ON customer(yob, postalcode); CREATE INDEX i5 ON customer(postalcode, id, address); CREATE INDEX i6 ON customer(yob, id, address); CREATE INDEX i7 ON customer(postalcode, yob, id, address); CREATE INDEX i8 ON customer(yob, postalcode, id, address); |
La elección de una ruta de acceso válida para el optimizador será:
- Cada índice i1 a i8 es una ruta de acceso válida
- Una exploración de la tabla es siempre una opción.
- varios índices combinados
De repente, no es fácil elegir el mejor índice para la consulta, ni siquiera para esta consulta tan sencilla. Así que un optimizador basado en reglas mantiene un conjunto de reglas y las sigue de forma coherente para dar con el mejor plan. El conjunto de reglas que sigue Optimizador basado en reglas N1QL están bien documentados.
Estas reglas no estaban grabadas en piedra desde el primer día. Empiezas a preferir rutas de índices, índices con más claves, etc. Incluso entonces tendrás conflictos.
Ejemplo:
Consulta: SELECT id, address FROM customer WHERE postalcode = 57020 and yob < 1980;
Índices:
CREATE INDEX i7 ON customer(postalcode, yob, id, address); CREATE INDEX i8 ON customer(yob, postalcode, id, address);
Un optimizador basado en reglas no puede averiguar cuál de estos índices es el más eficiente. Todo se reduce a la asimetría de los datos: La selección de índices en una base de datos no será óptima en otra.
Por ejemplo:
Consulta:
|
1 2 3 4 5 6 |
SELECT c.state, d.status, SUM(o.sale_amt) FROM order o INNER JOIN customer c ON (o.cid = c.id) INNER JOIN demo d ON (c.did = d.did) WHERE d.edu = “college” AND d.mstatus = “married” GROUP BY c.state, d.status |
En la cláusula FROM dada, todos los órdenes siguientes son válidos. ¿Cuál de ellos debe elegir el optimizador?
- ((orden INNER JOIN cliente) INNER JOIN demo)
- ((cliente INNER JOIN pedido) INNER JOIN demo)
- ((orden INNER JOIN demo) INNER JOIN cliente)
- ((cliente INNER JOIN demo) INNER JOIN pedido)
- ((demo INNER JOIN pedido) INNER JOIN cliente)
- ((demo INNER JOIN cliente) INNER JOIN pedido)
Las opciones aumentan y la selección se complica a medida que aumenta el número de espacios de claves (o tablas) en la cláusula FROM. Un orden incorrecto significa que los resultados intermedios podrían ser enormes, sólo para descartar la mayor parte más adelante. Por ejemplo, en la consulta anterior, unir el orden con el cliente primero creará un conjunto de resultados intermedios enorme porque sólo nos interesan los clientes casados con estudios "universitarios". Un mal orden de unión afecta negativamente tanto a la latencia de la consulta como al rendimiento del sistema.
Por ejemplo:
Consulta:
|
1 2 3 4 |
SELECT c.state, c.zip, SUM(sale_amt) FROM order o INNER JOIN customer c ON (o.cid = c.id) WHERE o.year = “2018” GROUP BY state, zip; |
Aquí hay que tomar dos decisiones. El tipo de JOIN y el orden de las tablas. Sin conocer las estadísticas de cada uno, es imposible decidir de forma inteligente. Por lo tanto, los optimizadores basados en reglas simplemente elegirán por defecto un método y dependerán del usuario para cambiar del predeterminado. Esto es ineficaz e inviable para consultas de gran tamaño. Las consecuencias para el rendimiento son enormes: de segundos a minutos o de minutos a horas.
Una vez más, las estimaciones estadísticas vienen al rescate. En las aplicaciones empresariales, son habituales las consultas con muchos espacios de claves (tablas) y predicados complejos.
Conclusión
Para las cargas de trabajo del mundo real, las decisiones basadas en estadísticas son mucho mejores que las decisiones basadas en reglas. Y punto. Esa es la razón por la que N1QL implementó el CBO. Descargar Couchbase 6.5 ahora y compruébelo usted mismo.
Y antes de decidirse por una base de datos NoSQL, pregunte al proveedor: ¿Dispone de un optimizador basado en los costes?
Referencias
- La irrazonable eficacia de SQL en las bases de datos NoSQL: Un Estudio Comparativo. https://www.couchbase.com/blog/the-unreasonable-effectiveness-of-sql-in-nosql-databases/
- La irracional eficacia de SQL https://www.couchbase.com/blog/unreasonable-effectiveness-of-sql/
- Descargar Couchbase 6.5: https://couchbase.com/downloads?family=server&product=couchbase-server-developer
- Visión general de la optimización de consultas en sistemas relacionales. https://cs.stanford.edu/people/chrismre/cs345/rl/chaudhuri98.pdf