Recientemente estuve trabajando en un proyecto que hacía uso de N1QL para consultar Servidor Couchbase datos. Se trataba de una aplicación Java interna que estaba alojando en una instancia de Amazon EC2 de bajo presupuesto. Mi problema aquí es que mis consultas se estaban ejecutando increíblemente lento. La razón de esto era que sólo tenía un índice primario que era muy genérico.
Vamos a ver lo que hice para acelerar mis consultas y algunas de las cosas que tuve que tener en cuenta durante el proceso.
En primer lugar, es probablemente una buena idea compartir qué versión de Couchbase Server estoy usando. Estoy usando Couchbase Server 4.1 en mi máquina de baja potencia. El bucket con el que estoy trabajando tiene alrededor de 100.000 documentos de diferentes tipos. No es que importe para este artículo, pero la aplicación que accede a estos datos fue construida en Java usando el Couchbase Java SDK.
Con mi configuración fuera del camino, permítanme compartir una de las consultas que estaba ejecutando:
|
1 2 3 4 5 6 7 8 9 |
SELECCIONE MILLIS_TO_UTC(fecha, '2006-01-12') AS tweetFecha, CONTAR(*) AS cuente DESDE `por defecto` DONDE tipo=tweet GRUPO POR MILLIS_TO_UTC(fecha, '2006-01-12') PEDIR POR tweetFecha ASC |
Esta consulta me devolvería el número total de Tweets que había guardado para una fecha concreta. La información sobre la hora no era importante para mí. Tenga en cuenta que al principio sólo tenía un índice, que era mi índice primario. La consulta anterior tardaría bastante tiempo en ejecutarse.
Aquí es donde empecé a reevaluar mi estrategia.
Decidí tomar ventaja de los índices de cobertura que se hicieron disponibles en Couchbase 4.1. Esto es cuando hacemos un índice que cubre todas las propiedades que serán usadas dentro de una consulta. Mi creación de índices de la consulta anterior tenía el siguiente aspecto:
|
1 2 3 4 5 |
CREAR ÍNDICE twitter_por_fecha EN `por defecto` (fecha, tipo) DONDE tipo = tweet USO DE GSI; |
Sí, estoy haciendo agregaciones, pero al fin y al cabo sólo estoy consultando en función de la variable fecha y tipo propiedades. Así que volví a ejecutar la consulta con el índice de cobertura, pero no observé ningún cambio en el rendimiento.
Esto me llevó a dirigir un EXPLICAR en la propia consulta para solucionar el problema.
|
1 2 3 4 5 6 7 8 9 |
EXPLICAR SELECCIONE MILLIS_TO_UTC(fecha, '2006-01-12') AS tweetFecha, CONTAR(*) AS cuente DESDE `por defecto` DONDE tipo=tweet GRUPO POR MILLIS_TO_UTC(fecha, '2006-01-12') PEDIR POR tweetFecha ASC |
Cuando vi el desglose de la consulta que EXPLICAR me proporcionó, pude ver que todavía estaba tratando de utilizar el #primario que había creado originalmente. Esto es incluso después de validar que el índice de cobertura ahora existía en Couchbase.
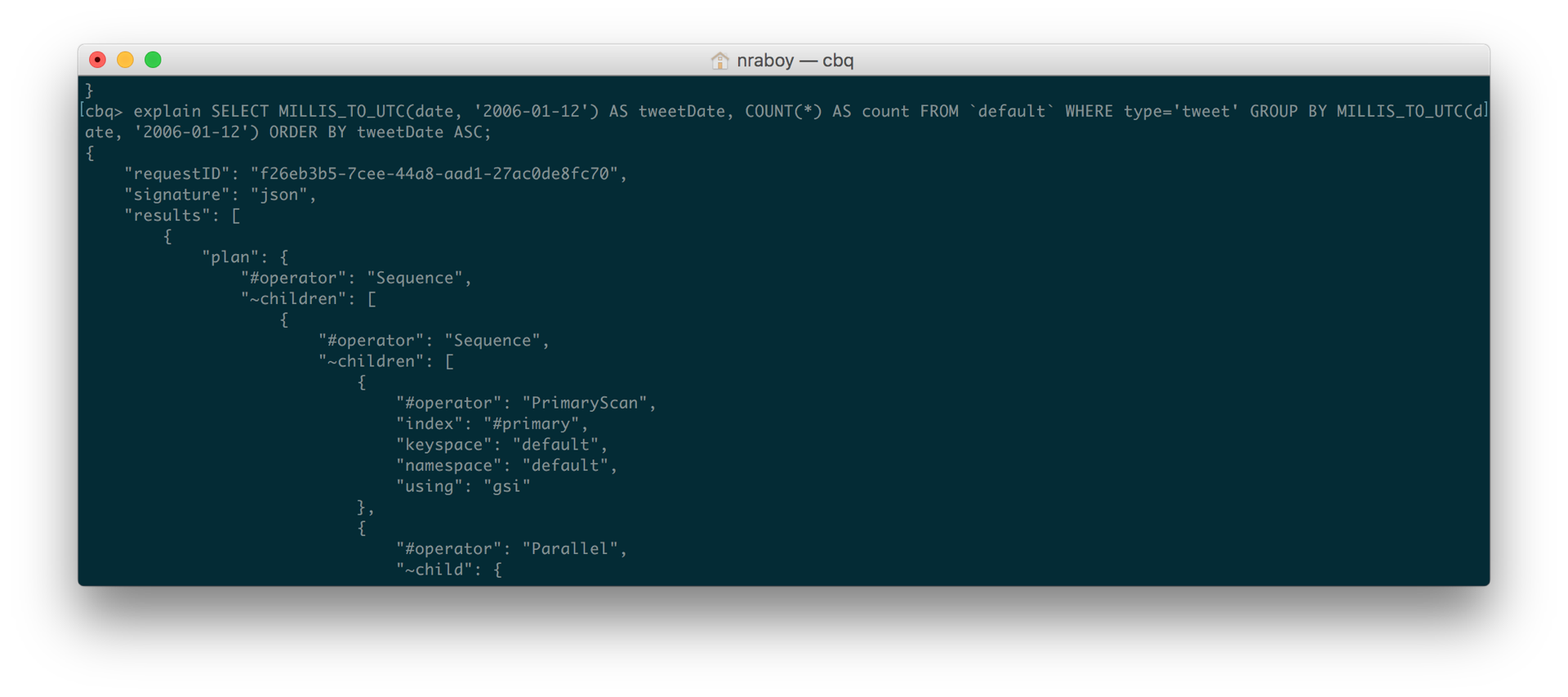
Entonces recordé que los documentos de Twitter no eran los únicos tipos de datos que existían en mi cubo. En otras palabras, no todos los documentos tenían una propiedad llamada fecha y no todos los documentos tenían una propiedad tipo que coincidía con tuitee. Ahora he tenido que revisar la consulta que quería ejecutar para comprobar estos supuestos.
|
1 2 3 4 5 6 7 8 9 |
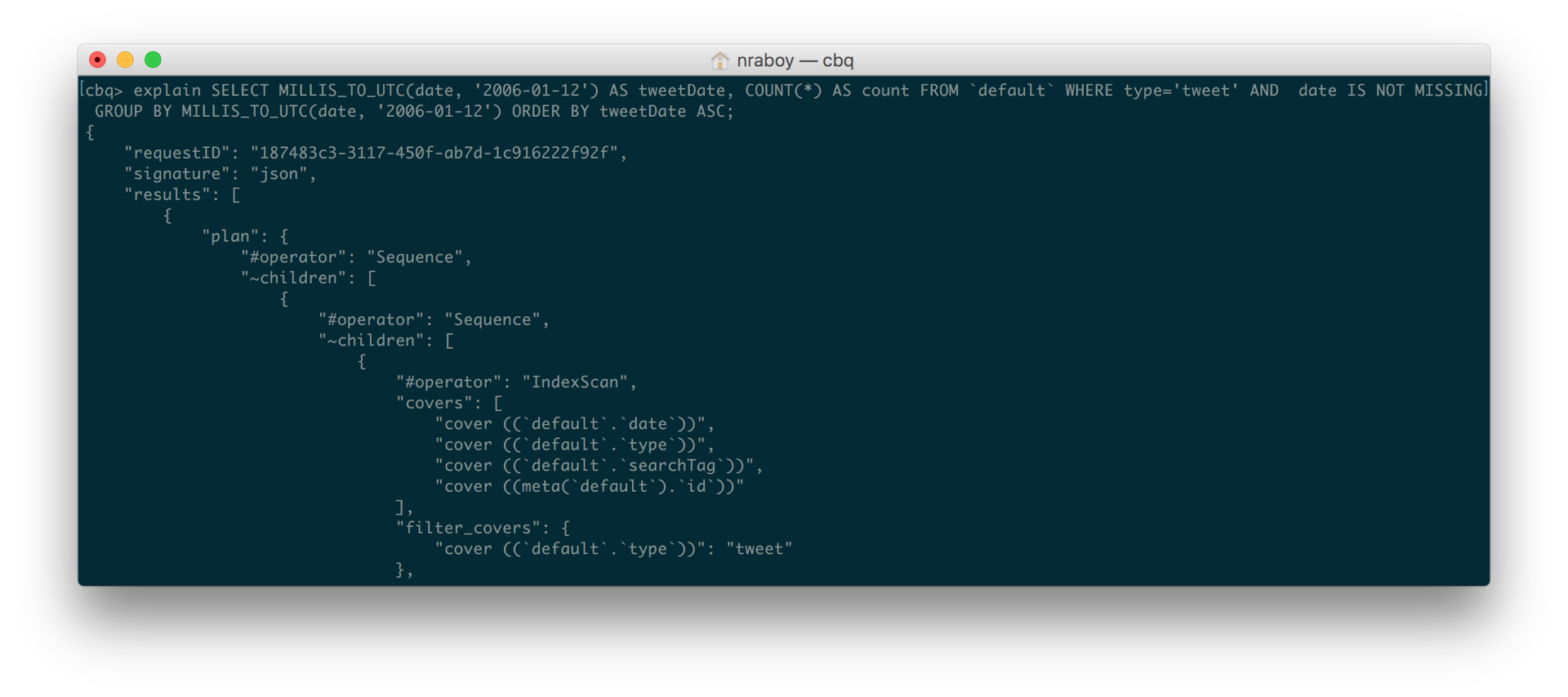
SELECCIONE MILLIS_TO_UTC(fecha, '2006-01-12') AS tweetFecha, CONTAR(*) AS cuente DESDE `por defecto` DONDE tipo=tweet Y fecha IS NO FALTA GRUPO POR MILLIS_TO_UTC(fecha, '2006-01-12') PEDIR POR tweetFecha ASC |
En la consulta anterior, observe en particular cómo he añadido Y LA FECHA NO FALTA. Primero compruebo que el fecha existe. Ya estábamos comprobando esa propiedad tipo emparejado tuiteepero les faltaba la otra pieza.
Después de ejecutar la consulta de nuevo, era significativamente más rápida. Cuando incluí EXPLICAR Inmediatamente pude ver que la consulta utilizaba ahora el índice de cobertura en lugar del índice primario.
Para saber más sobre los índices de cobertura, visite la página Portal para desarrolladores de Couchbase.